

The Vanishing Gradient Problem
Walaupun teknik ini handal, teknik RNN memiliki masalah yang krusial, apalagi jika menggunakan sigmoid activation function. Masalah ini dikenal dengan istilah vanishing gradient problem, atau jika diterjemahkan artinya ‘permasalahan luruhnya/hilangnya efektivitas gradien’.
Agar mudah memahaminya, mari kita lihat ilustrasi di bawah ini.

Pada gambar di atas bisa dilihat ada beberapa simbol. Simbol W merepresentasikan bobot yang dimiliki oleh setiap neuron (perceptron) nya. Wout artinya bobot yang dimiliki oleh output layer, sementara Win adalah bobot yang dimiliki oleh input layer. Tentunya Wout satu dengan lainnya berbeda angkanya. Kita tuliskan sama hanya untuk memudahkan saja. Begitu pula dengan Win satu dengan Win lainnya yang juga berbeda.
Wrec (weight of reccurent) merupakan bobot yang dimiliki oleh jalur looping ke perceptron lain yang ada di sampingnya. Wrec satu dengan Wrec yang lain juga berbeda nilainnya. Penulisan dibuat sama hanya untuk memudahkan ilustrasi saja.
Simbol yang paling atas merupkan epsilon (Et) yang mewakili nilai error sebuah perceptron di output layer pada waktu t. Nilai error ini adalah selisih (perbedaan) antara nilai di prediksi (y topi) dengan nilai sesungguhnya (y).
Jika pembaca bingung tentang simbol-simbol ini dan beberapa istilah deep learning, ada baiknya baca artikel saya yang membahas tentang neural networks di link ini.
Dalam proses meminimasi nilai error ini, maka sebuah neural networks harus melakukan proses backpropagation, di mana ia akan mundur ke belakang untuk mengupdate nilai w yang dimiliki setiap perceptron dengan cara menghitung nilai turunannya (derivative). Berbeda dengan neural networks versi standar, di RNN maka ia juga akan mundur ke belakang termasuk ke cabang-cabang recurrent-nya. Ilustrasinya sebagai berikut.

Sekarang mulailah muncul masalah, dan ini terjadi ketika kita menggunakan fungsi aktivasi sigmoid (sigmoid activation function). Karena nilai fungsi sigmoid berkisar antara 0 hingga 1, artinya nilai w semakin lama akan semakin kecil. Semakin panjang layer nya maka semakin cepat penurunan nilai W, apalagi jika proses epoch nya dilakukan berulang-ulang (sampai ratusan bahkan ribuan kali).
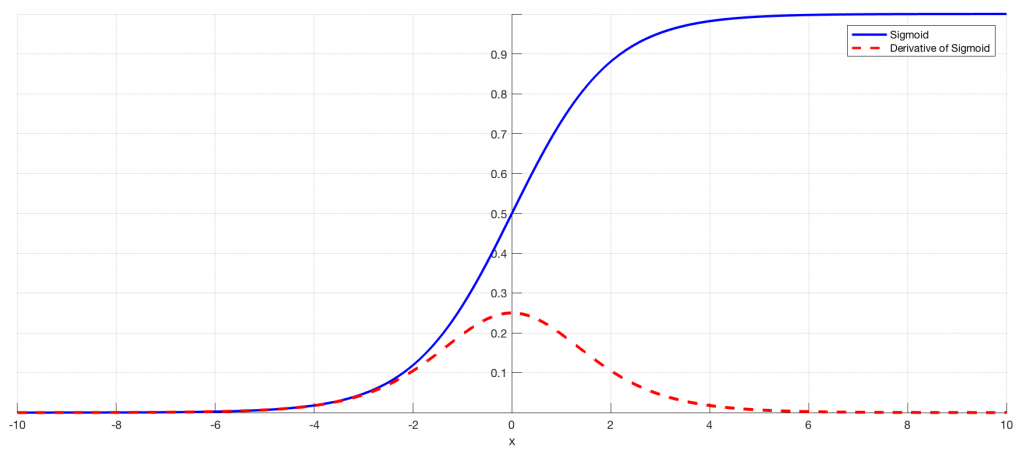
Dengan demikian, lama kelamaan nilai gradiennya (delta W) akan mendekati nol, dan penyesuaian nilai W tidak akan signifikan lagi. Jika penyesuaian nilai W sudah tidak signifikan, maka penurunan nilai epsilon (error) akan stagnan, padahal sebenarnya solusinya belum converge.
Ilustrasi matematisnya sebagai berikut:
Wbaru = Wlama – (learning_rate*gradien)
Dalam formula matematis adalah:

Apa jadinya jika gradiennya kecil? Maka nilai W baru tidak akan berubah signifikan. Ilustrasinya:
2.0999 = 2.1 – 0.001
Wbaru berubah dari 2.1 menjadi 2.0999. Namun jika terus menerus dilakukan update nilai W dnegan nilai gradien yang sangat kecil, maka angka W baru hanya berkutat berkisar antara 2.09 dan seterusnya.
Saya harap ilustrasi vanishing gradient di atas cukup membuat pembaca memahami garis besarnya.
Solusi Masalah Vanishing Gradient
Lalu bagaimana solusi untuk mengatasi masalah ini?
Ada beberapa hal yang bisa dilakukan, antara lain:
- Menggunakan fungsi aktivasi rectifier (ReLu). Walau demikian, perlu diperhatikan, penggunaan ReLu dalam RNN bisa menyebabkan masalah lain yang disebut dengan exploding gradient problem, di mana nilai gradiennya semakin lama semakin membesar. Tapi ini bisa disiasati dengan menggunakan ukuran batch yang kecil. Ini juga yang menjadi alasan mengapa penggunaan ReLu menjadi populer.
- Solusi lain adalah dengan menggunakan gradient clipping. Artinya kita mengunci agar nilai gradiennya tetap di rentang tertentu. Caranya adalah dengan me-rescale gradiennya sehingga nilainya berada di rentang tertentu.
- Menggunakan arsitektur ResNet (Residual Network), di mana sebuah neuron melewati (skip) beberapa neuron di depannya. Berikut adalah tampilan dari arsitektur ResNet.
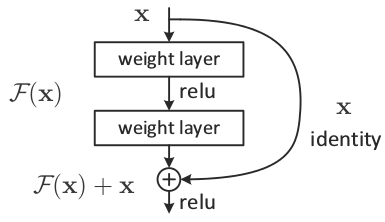
Kita tidak akan menggunakan ketiga solusi di atas. Solusi yang akan kita gunakan dan akan dibahas di halaman selanjutnya adalah menggunakan network LSTM (long short-term memory).
Untuk melanjutkan membaca, silakan klik tombol ke halaman selanjutnya di bawah ini.