

STUDI KASUS
Saya ulang sedikit tentang permasalahan yang ingin kita cari solusinya dengan decision tree. Seorang pemilik showroom mobil ingin mengiklankan SUVnya sosmed. Namun ia bingung di kelompok mana ia harus mengiklankan produk SUVnya, dengan harapan kemungkinan penjualan SUVnya bisa meningkat. Untuk membantunya, kita diberikan data-data pelanggan sebelumnya.
Kita akan memecahkan permasalahan ini dengan 2 bahasa yaitu Python dan R.
Sebelum memulai, silakan download datasetnya di link ini.
Bahasa Python
# Mengimpor library yang diperlukan
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Mengimpor dataset
dataset = pd.read_csv('Iklan_sosmed.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
# Menjadi dataset ke dalam Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Membuat model Decision Tree Classification terhadap Training set
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(criterion = 'entropy', random_state = 0)
classifier.fit(X_train, y_train)
# Memprediksi hasil test set
y_pred = classifier.predict(X_test)
# Membuat confusion matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
# Visualisasi hasil model Decision Tree Classification dari Training set
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Decision Tree Classification (Training set)')
plt.xlabel('Usia')
plt.ylabel('Estimasi Gaji')
plt.legend()
plt.show()
# Visualisasi hasil model Decision Tree Classification dari Test set
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Decision Tree Classification (Training set)')
plt.xlabel('Usia')
plt.ylabel('Estimasi Gaji')
plt.legend()
plt.show()
Penjelasan:
- Line 2-4 mengimpor library yang diperlukan.
- Line 7 mengimpor datasetnya.
- Line 8 mendefinisikan variabel X dengan melakukan slicing.
- Line 9 mendefinisikan variabel y dengan melakukan slicing.
- Line 12 mengimpor library train_test_split dari sklearn.model_selection.
- Line 13 membagi dataset ke dalam training dan test set.
- Line 16 mengimpor library StandardScaler untuk melakukan feature scaling.
- Line 17 mendefinisikan variabel sc untuk melakukan feature scaling.
- Line 18-19 melakukan feature scaling.
- Line 22 menimpor library DecisionTreeClassifier dari sklear.tree untuk membuat model DTC.
- Line 23 mendefinisikan variabel classifier untuk proses DTC. Kita pilih ‘entropy’ sebagai parameternya. Kenapa kita pilih entropy? Agar data hasil pembagiannya bersifat homogen (menggunakan menggunakan maximum entropy). Kita tidak akan bahas lebih detail (terlalu teknis), tapi setidaknya pembaca tahu bahwa semakin homogen pembagian cabang dari induknya, maka semakin baik akurasinya. Tips: Untuk bisa mengetahui parameter apa saja yang diperlukan, arahkan kursor pada DecisionTreeClassifier, kemudian ketik CTRL+i di keyboard.
- Line 24 membuat model DTC untuk training set.
- Line 27 mendefinisikan y_pred untuk memprediksi hasil model DTC ke test set.
- Line 30 mengimpor library confusion_matrix untuk melihat performa modelnya (membandingkan training dan test set)
- Line 31 mendefinisikan variabel cm sebagai confusion matrixnya. Hasilnya sebagai berikut:
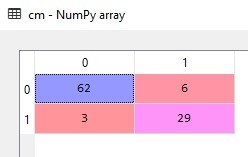
Melalui confusion matrix di atas dapat dilihat bahwa akurasi model kita cukup baik. Dari 100 deteksi, ia salah prediksi sebanyak 6+3=9, sehingga tingkat akurasinya adalah 91%.
- Line 34-49 adalah perintah untuk visualisasi hasil model training set. Jika dieksekusi maka akan tampak sebagai berikut:

Hasil decision tree classification untuk training set
Zona merah adalah zona di mana data pelanggan memutuskan untuk tidak membeli. Sementara zona hijau adalah zona di mana pelanggan memutuskan untuk membeli. Dua zona ini adalah hasil dari model decision tree yang dibuat.
Titik-titik adalah data pelanggan. Titik merah adalah data pelanggan yang memutuskan untuk tidak membeli, sementara titik hijau adalah data pelanggan memutuskan untuk membeli mobil.
Titik merah yang berada di zona hijau adalah prediksi yang salah. Begitu juga dengan titik hijau yang berada di zona merah juga merupakan prediksi yang salah.
- Line 52-67 adalah perintah untuk visualisasi hasil model test set. Jika dieksekusi maka akan tampak sebagai berikut:

Hasil decision tree classification untuk test set
Hasil visualisasi test set cukup baik. Seperti yang di bahas di bagian confusion matrix di atas, terlihat bahwa dari 100 prediksi, model ini hanya meleset sebanyak 9 titik. Dengan begitu, akurasinya 91%. Akurasi juga bisa dilihat di CM (confusion matrix) seperti yang sudah dibahas di line31.
Oleh karena itu, melalui model decision tree yang sudah dibuat, kita sarankan kepada pemilik showroom mobil untuk mengiklankan produknya di zona hijau. Dengan demikian, probabilitas (peluang) calon pelanggan setelah melihat iklannya akan naik.
Untuk melanjutkan membaca pembahasan dengan bahasa R, silakan klik tombol halaman selanjutnya di bawah ini.