

Bahasa R
# Mengimpor dataset
dataset = read.csv('Iklan_sosmed.csv')
dataset = dataset[3:5]
# Mengencode variabel dependen sebagai faktor
dataset$Beli = factor(dataset$Beli, levels = c(0, 1))
# Membagi dataset ke dalam Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Beli, SplitRatio = 0.75)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
training_set[, 1:2] = scale(training_set[, 1:2])
test_set[, 1:2] = scale(test_set[, 1:2])
# Membuat model k-NN ke training set sekaligus memprediksi Test set
library(class)
y_pred = knn(train = training_set[, 1:2],
test = test_set[, 1:2],
cl = training_set[, 3],
k = 5)
# Membuat Confusion Matrix
cm = table(test_set[, 3], y_pred)
# Visualisasi hasil Training set
library(ElemStatLearn)
set = training_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Usia', 'EstimasiGaji')
y_grid = knn(train = training_set[, 1:2], test = grid_set, cl = training_set[, 3], k = 5)
plot(set[, -3],
main = 'K-NN (Training set)',
xlab = 'Usia', ylab = 'Estimasi Gaji',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
# Visualisasi hasil Test set
library(ElemStatLearn)
set = test_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Usia', 'EstimasiGaji')
y_grid = knn(train = training_set[, 1:2], test = grid_set, cl = training_set[, 3], k = 5)
plot(set[, -3],
main = 'K-NN (Test set)',
xlab = 'Usia', ylab = 'Estimasi Gaji',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
Penjelasan:
- Line 2 mengimpor dataset.
- Line 3 melakukan slicing di mana kolom yang kita perlukan hanya kolom 3 (usia) sampai kolom 5 (beli).
- Line 6 merubah variabel dependen (kolom beli) menjadi faktor. Hal ini untuk menunjukkan bahwa variabel beli adalah jenis kategori, dan bukan string atau nominal.
- Line 9 menginstall library caTools jika belum diinstall di Rstudio.
- Line 10 mengimpor libraru caTools.
- Line 11 menentukan random number generator 123 (angka ini bebas, namun kali ini untuk replikasi di kemudian hari dan perbandingan antar teknik klasifikasi, kita tentukan 123).
- Line 12 mendefinisikan variabel split sebagai training dan test set nantinya.
- Line 13 mendefinisikan variabel training_set.
- Line 14 mendefiniskan variabel test_set.
- Line 17-18 melakukan feature scaling.
- Line 21 mengimpor librari class yang merupakan library khusus klasifikasi di R.
- Line 22-26 membuat model k-NN sekaligus memprediksi y_pred dari model ini. Untuk memudahkan mengetahui parameter apa saja yang diperlukan maka cukup arahkan kursor ke knn, lalu ketik F1 di keyboard. Maka tampilannya akan seperti ini:
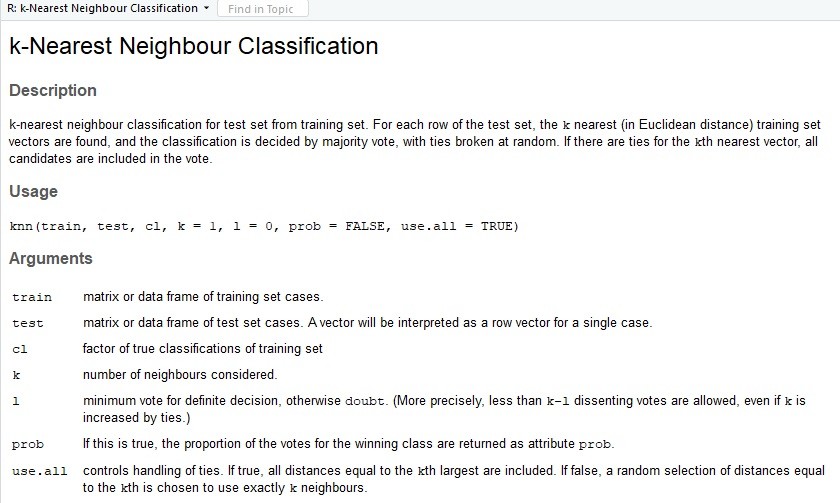
Kita tentukan train = training_set dengan kolom usia dan EstimasiGaji, begitu juga dengan variabel test di line 23. Kemudian cl adalah variabel dependennya, maka kita tentukan cl= training_set[, 3]. Kita tentukan k=5 (5 tetangga terdekat).
- Line 28 mendefinisikan variabel cm untk membandingkan antara test set (data asli) dengan y_pred (data hasil prediksi). Hasil cm akan tampak sebagai berikut:
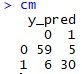
Bisa dilihat bahwa akurasi kita cukup baik. Prediksi benar sebanyak 59+30=89, sementara prediksi salah 6+5=11, sehingga akurasi model kita 89%.
- Line 31-44 adalah visualisasi hasil model k-NN terhadap training set. Pastikan library ElemStatLearn sudah terinstall di Rstudio. Hasilnya akan tampak sebagai berikut:

Gambar ini adalah hasil prediksi keputusan beli/tidak berdasarkan usia dan gaji yang dimiliki pelanggan.
- Line 47-60 adalah visualisasi hasil model k-NN terhadap test set. Hasilnya akan tampak sebagai berikut:
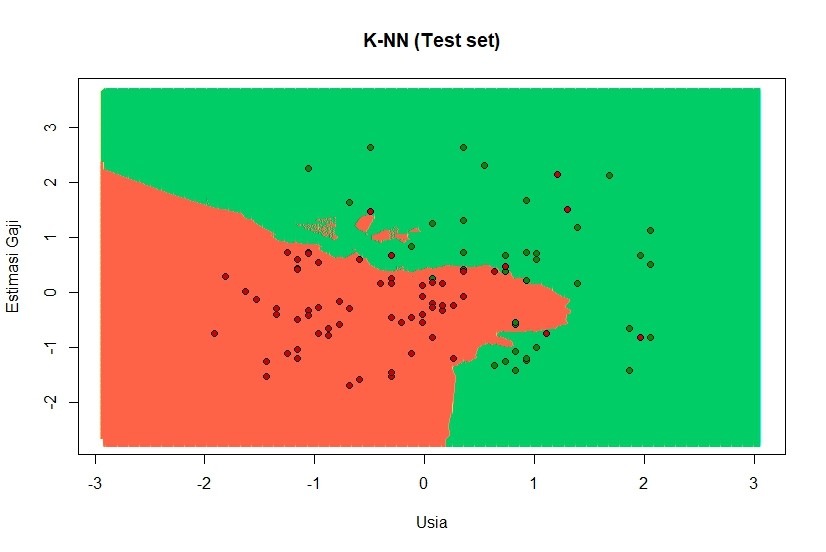
Gambar ini adalah hasil prediksi keputusan beli/tidak berdasarkan usia dan gaji yang dimiliki pelanggan.
Melalui gambar di atas, bisa dilihat bahwa zona merah menunjukkan prediksi model kita di mana pelanggan memutuskan untuk tidak membeli mobil SUV, sementara titik-titik merah adalah data asli di mana pelanggan akhirnya memutuskan untuk tidak membeli. Model kita sangat akurat, di mana hanya ada 5 titik hijau yang masuk di zona merah.
Begitu pula dengan zona hijau, ini adalah zona kelompok hasil prediksi model kita. Di zona hijau pelanggan diprediksi untuk akan memutuskan untuk membeli. Terlihat hanya ada 6 titik merah yang masuk di zona hijau ini (kesalahan prediksi oleh model).
Ket: Karena kolom usia dan estimasi penghasilan sudah melalui proses feature scaling maka nilai nol (0) pada sumbu x dan y adalah nilai rataannya.
Bisa disimpulkan, dengan menggunakan metode K-nearest Neighbors, model kita mampu memprediksi keputusan pembelian pelanggan dengan cukup akurat. Dengan demikian, kita rekomendasikan pemilik showroom mobil untuk fokus melakukan pemasarannya di zona hijau, dengan karakteristik penghasilan tinggi dan usia cukup dewasa.
Halo pak.
Saya mau bertanya, untuk di python bagaimana kita mengetahui UserID orang2 yang ada di zona hijau dan merah yang digunakan sebagai daftar orang2 yang akan diberikan penawaran produk? Terimakasih.