

Kita kembali ke permasalahan sebelumnya, yaitu 2 kelompok motor dan mobil. Namun kali ini, kita coba menghitungnya secara manual dengan angka yang ada.
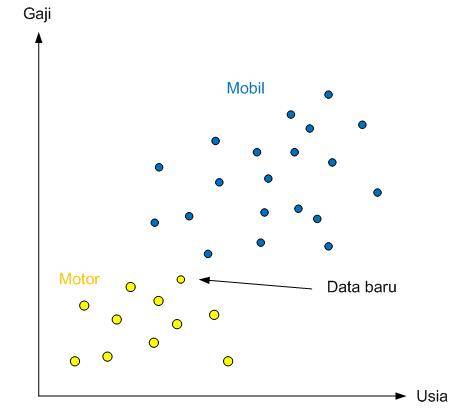
Sebelumnya kita lihat kembali scatter plot dari 2 kelompok ini:

Ilustrasi penambahan data baru di plot motor dan mobil
Proses penyelesaiannya sama dengan pembahasan sebelumnya. Urutannya juga sama.
Langkah-langkahnya sebagai berikut:
- P(Motor) = Jumlah orang pengguna motor/Total pekerja = 10/30 = 0.33
- P(X) = Jumlah data dalam fitur X/Total pekerja = ?
Pembahasan mengenai P(X) agak sedikit menarik. Jadi kita harus buat dulu sebuah lingkaran dengan jari-jari (radius) yang bisa kita tentukan. Semua titik yang masuk ke dalam lingkaran ini, akan masuk sebagai data dengan fitur X. Maksudnya adalah titik-titik yang masuk ke dalam lingkaran tidak masuk ke golongan mobil atau motor, namun masuk ke golongan X. Ilustrasi mudahnya sebagai berikut:
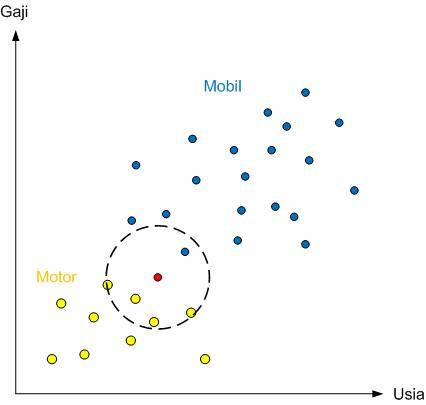
Perlu diperhatikan bahwa untuk menghitung P(X) kita tidak perlu memasukkan data baru tadi (titik berwarna merah), sehingga perhitungannya menjadi:
P(X) = Jumlah data dalam fitur X/Total pekerja = 5/30 = 0.16
Note = angka 5 didapat dari 4 pengguna motor ditambah 1 pengguna mobil
Sebagai review, P(X) adalah probabilitas titik-titik baru masuk ke dalam zona lingkaran ini.
Sampai sini pasti paham, sekarang saatnya lanjut ke tahap ketiga.
3. P(X|Motor) = Probabilitas pengguna motor yang masuk ke dalam fitur X
Jika ditulis ulang, maka menjadi:
P(X|Motor) = jumlah pengguna motor yang masuk ke fitur X / jumlah pengguna motor = 4/10 = 0.4
Note = angka 4 didapat dari total jumlah pengguna motor yang masuk ke lingkaran X, sementara 10 adalah total pengguna motor (termasuk yang masuk di lingkaran X).
4. P(Motor|X) = (0.4 * 0.33)/0.16 = 0.8
Jika sudah, sekarang gantian kita cari P(Mobil|X).
- P(Mobil) = Jumlah orang pengguna mobil/Total pekerja = 20/30 = 0.67
- P(X) = 0.16
- P(X|Mobil) = jumlah pengguna mobil yang masuk ke fitur X / jumlah pengguna mobil = 1/20 = 0.05
- P(Mobil|X) = (0.05*0.67)/0.16 = 0.2
Sekarang kita cukup membandingkan saja, mana yang lebih besar, apakah P(Motor|X) atau P(Mobil|X).
Ternyata P(Motor|X)>P(Mobil|X), di mana 0.8>0.2, sehingga titik baru tadi akan menjadi bagian dari pengguna motor.
Tips= Penjumlahan antara P(Motor|X)>P(Mobil|X) = 1. Jadi sebenarnya jika kita hanya membandingkan 2 kluster (kelompok), maka cukup dihitung salah satunya saja.
Sampai sini saya harap pembaca bisa memahami konsepnya ya.
Untuk melanjutkan membaca, silakan klik tombol lanjut ke halaman berikutnya di bawah ini.
visualnya error kalo featurenya lebih dari 2, gimana ya pak caranya
Visualisasi memang mudahnya untuk 2D (2 dimensi) untuk 2 fitur. Kalau lebih dari itu susah untuk memvisualisasikan, apalagi jika lebih dari 3 fitur.
Untuk fitur lebih dari 2, penyelesaiannya direkomendasikan untuk menggunakan pendekatan Neural Networks yang dibahas di bagian Deep Learning 🙂
Maaf pak. Mengapa feature ‘kelamin’ tidak dimasukkan ?
Halo, dalam pembahasan ini yang dipakai hanya data gaji dan usia.
Silakan dicoba-coba sendiri memasukkan data kelamin sebagai variabel independen, dan bandingkan hasilnya.
Halo Pak Mega,
Dalam 2 ilustrasi yang bapak Jelaskan, saya bingung dalam menentukan variabel dari formula bayes tsb, bukan kah P(M2) diilustrasi pertama sama dengan P(Motor) / P(Mobil) diilustrasi kedua karena memiliki sampel yang homogen jika dibandingkan dengan seluruh sampel, sedangkan P(Cacat) sama dengan P(X) karena kedua himpunan tsb teresbut terbentuk dari suatu kondisi dan memiliki sampel yang tidak homogen. Lalu di Ilustrasi pertama variabel P(M2) adalah pembagi, sedangkan di ilustrasi kedua variabel P(X) adalah Pembagi. kira2 bagaimana pak penjelasannya?
Terima kasih
Halo Jacoub. Rumusnya memang seperti itu.
Bisa diperdalam lagi di mata kuliah Statistik 1, biasanya ia dibahas bersama materi probabilitas.