

Bahasa R
# Mengimpor dataset
dataset = read.csv('Iklan_sosmed.csv')
dataset = dataset[3:5]
# Encode variabel Beli sebagai faktor
dataset$Beli = factor(dataset$Beli, levels = c(0, 1))
# Membagi data ke dalam Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Beli, SplitRatio = 0.75)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
training_set[, 1:2] = scale(training_set[, 1:2])
test_set[, 1:2] = scale(test_set[, 1:2])
# Membuat model Naive Bayes ke Training Set
# install.packages('e1071')
library(e1071)
classifier = naiveBayes(x = training_set[1:2],
y = training_set$Beli)
# Memprediksi hasil Test Set
y_pred = predict(classifier, newdata = test_set[1:2])
# Membuat Confusion Matrix
cm = table(test_set[, 3], y_pred)
# Visualisasi hasil Training Set
library(ElemStatLearn)
set = training_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Usia', 'EstimasiGaji')
y_grid = predict(classifier, newdata = grid_set)
plot(set[, 1:2],
main = 'Naive Bayes (Training set)',
xlab = 'Usia', ylab = 'Estimasi Gaji',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '19', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
# Visualisasi hasil Test Set
library(ElemStatLearn)
set = test_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Usia', 'EstimasiGaji')
y_grid = predict(classifier, newdata = grid_set)
plot(set[, 1:2],
main = 'Naive Bayes (Test set)',
xlab = 'Usia', ylab = 'Estimasi Gaji',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '19', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
Penjelasan:
- Line 2 mengimpor datasetnya.
- Line 3 melakukan slicing. Kita hanya butuh kolom Usia, Gaji dan Beli.
- Line 6 mengonversi kolom Beli sebagai faktor (categorical).
- Line 9 menginstall library caTools. Jika pembaca belum menginstallnya, maka cukup hilangkan tanda pagar.
- Line 10 menjalankan library caTools.
- Line 11 menentukan random number generator (RNG) 123, sehingga jika pembaca ingin menduplikasikan hasil olah data akan selalu sama hasilnya untuk RNG yang sama.
- Line 12-14 membagi data ke training set dan test set.
- Line 17-18 melakukan feature scaling.
- Line 21 menginstall library e1071 . Jika di Rstudio pembaca belum terinstall package ini, cukup hilangkah tanda pagar (#) nya.
- Line 22 menjalankan library e1071.
- Line 23 mendefinisikan variabel classifier sekaligus membuat model naive bayesnya dengan variabel X adalah kolom Usia dan Gaji, sementara variabel y adalah kolom Beli.
- Line 27 mendefinisikan variabel y_pred untuk memprediksi hasil test set dari model yang sudah dibuat di line 23.
- Line 30 membuat confusion matrixnya. Jika diketik cm di console maka akan tampak sebagai berikut:
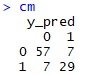
Tabel confusion matrix di atas menunjukkan bahwa prediksi kita cukup baik. Dari 100 prediksi test set, kita salah sebanyak 14 kali, sehingga akurasinya adalah 86%. Akurasi yang cukup baik!
- Line 33 menjalankan library ElemStatLearn untuk visualisasi hasil model.
- Line 34-46 adalah perintah untuk visualisasi hasil model terhadap training set. Jika dieksekusi maka tampak sebagai berikut:

Zona merah adalah zona di mana data pelanggan memutuskan untuk tidak membeli. Sementara zona hijau adalah zona di mana pelanggan memutuskan untuk membeli. Dua zona ini adalah hasil dari model naive bayes yang dibuat.
Titik-titik adalah data pelanggan. Titik merah adalah data pelanggan yang memutuskan untuk tidak membeli, sementara titik hijau adalah data pelanggan memutuskan untuk membeli mobil.
Titik merah yang berada di zona hijau adalah prediksi yang salah. Begitu juga dengan titik hijau yang berada di zona merah juga merupakan prediksi yang salah.

Hasil visualisasi test set cukup baik. Seperti yang di bahas di bagian confusion matrix di atas, terlihat bahwa dari 100 prediksi, model ini hanya meleset sebanyak 14 titik. Dengan begitu, akurasinya 86%!
Oleh karena itu, melalui model naive bayes yang sudah dibuat, kita sarankan kepada pemilik showroom mobil untuk mengiklankan produknya di zona hijau. Dengan demikian, probabilitas (peluang) calon pelanggan setelah melihat iklannya akan naik.
Mudah bukan?
Saya harap pembaca bisa memahami teknik naive bayes dan tentunya bisa mengaplikasikannya untuk memecahkan persoalan nyata.
Terus kunjungi web saya untuk belajar bersama teknik AI lainnya.
Terima kasih.
visualnya error kalo featurenya lebih dari 2, gimana ya pak caranya
Visualisasi memang mudahnya untuk 2D (2 dimensi) untuk 2 fitur. Kalau lebih dari itu susah untuk memvisualisasikan, apalagi jika lebih dari 3 fitur.
Untuk fitur lebih dari 2, penyelesaiannya direkomendasikan untuk menggunakan pendekatan Neural Networks yang dibahas di bagian Deep Learning 🙂
Maaf pak. Mengapa feature ‘kelamin’ tidak dimasukkan ?
Halo, dalam pembahasan ini yang dipakai hanya data gaji dan usia.
Silakan dicoba-coba sendiri memasukkan data kelamin sebagai variabel independen, dan bandingkan hasilnya.
Halo Pak Mega,
Dalam 2 ilustrasi yang bapak Jelaskan, saya bingung dalam menentukan variabel dari formula bayes tsb, bukan kah P(M2) diilustrasi pertama sama dengan P(Motor) / P(Mobil) diilustrasi kedua karena memiliki sampel yang homogen jika dibandingkan dengan seluruh sampel, sedangkan P(Cacat) sama dengan P(X) karena kedua himpunan tsb teresbut terbentuk dari suatu kondisi dan memiliki sampel yang tidak homogen. Lalu di Ilustrasi pertama variabel P(M2) adalah pembagi, sedangkan di ilustrasi kedua variabel P(X) adalah Pembagi. kira2 bagaimana pak penjelasannya?
Terima kasih
Halo Jacoub. Rumusnya memang seperti itu.
Bisa diperdalam lagi di mata kuliah Statistik 1, biasanya ia dibahas bersama materi probabilitas.