
")
MENGUJI PERFORMA MODEL CNN KITA KEMBALI
Setelah kita berhasil melatih model kita dengan cukup baik, kita belum cukup puas. Sekarang kita ingin mengujinya lagi, dan kita ingin mengetahui secara kuantitif performa model kita.
Jika pembaca memiki folder berisi gambar-gambar kucing (jika ingin menguji detektor kucing) maka pembaca bisa mengujinya. Namun kai ini kita sudah memiliki 1000 gambar kucing di folder test set. Kita uji saja lagi hasil model CNN untuk mendeteksi gambar kucing atau anjing (terserah pembaca). Namun kali ini kita ingin mengujinya untuk mendeteksi gambar anjing.
# Uji coba lagi di test_set
import numpy as np
from keras.preprocessing import image
count_dog = 0
count_cat = 0
for i in range(4001, 5001):
test_image = image.load_img('dataset/test_set/dogs/dog.' + str(i) + '.jpg', target_size = (128, 128))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = MesinKlasifikasi.predict(test_image)
training_set.class_indices
if result[0][0] == 0:
prediction = 'cat'
count_cat = count_cat + 1
else:
prediction = 'dog'
count_dog = count_dog + 1
# Mencetak hasil prediksinya agar bisa dibaca
print("count_dog:" + str(count_dog))
print("count_cat:" + str(count_cat))Penjelasan:
- Line 2-3 mengimpor library yang diperlukan.
- Line 4 dan 5 adalah mendefinisikan objek sebagai penghitung (counter).
- Line 6-17 adalah looping sebanyak 100 kali. Mengapa kita mulai dari 4001-5001? Mengapa tidak ditulis dari 1-1001? Hal ini dilakukan karena kita akan gunakan iteratornya (i) untuk nama filenya juga (bisa dilihat di line 7). Ini hanyalah style (gaya dari programmernya saja). Mungkin pembaca memiliki cara lain untuk menuliskan looping iterasi maka boleh-boleh saja.
- Line 8 merubah gambar ke array.
- Line 9 memperbesar dimensinya.
- Line 10 mendefinisikan objek result untuk menyimpan hasil prediksinya.
- Line 11 sebenarnya tidak diperlukan (bisa dihilangkan tanpa efek apa-apa). Namun jika pembaca menuliskan print(training_set.class_indices) di console spyder, maka akan memberikan hasil {‘cats’: 0, ‘dogs’: 1}. Dengan demikian kita bisa melihat dan menginterpretasikan hasilnya di objek result, bahwa nilai 0 menandakan ia adalah gambar cat, sementara 1 adalah anjing. Nilai 0 dan 1 ini ditentukan karena urutan alfabet di folder (c mendahului d, maka c=0, dan d=1).
- Line 12-17 memasukkan hasilnya ke objek count_cat jika prediksinya cat dan count_dog jika prediksinya dog.
- Line 20-21 adalah untuk melihat hasilnya di console. Kita juga sebenarnya bisa melihat hasilnya di variable explorer pada spyder. Tampilan di console spyder adalah sebagai berikut:
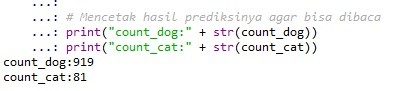
Wow! ternyata hasilnya sangat baik. Untuk memprediksi 1000 gambar anjing, model CNN kita berhasil memprediksi sebanyak 919 kali. Kalau mau dihitung akurasinya maka 91.9%.
Sampai di sini saya harap pembaca mendapatkan gambaran bagaimana cara komputer/program bisa mengenali dan mengklasifikasikan gambar. Saya harap pembaca tidak berhenti sampai di sini, dan bisa bereksperimen, merubah beberapa parameter yang sudah saya berikan di sini sehingga performa CNN nya jauh lebih baik lagi.
Yang tidak kalah penting, saya harap pembaca juga bisa mempraktekkan ini untuk permasalahan yang dihadapi di dunia nyata. Tentunya dengan belajar juga dari sumber-sumber lain akan memperkuat pemahaman pembaca dan bisa menggunakan CNN untuk permasalahan yang jauh lebih kompleks lagi.
Untuk teknik CNN dengan bahasa R, sampai saat ini masih dalam tahap pengembangan. Karena deep learning dengan R masih menggunakan server Oracle secara online dengan teknik H20, di mana merekapun juga belum selesai mengembangkan deep learning H20 ini sampai tahap final.
Jika sudah ada perkembangan CNN di bahasa R pasti akan saya posting, di web ini, dan pembaca yang sudah menjadi subscriber akan mendapatkan informasinya pertama kali.
Demikian pembahasan praktek dan aplikasi dari CNN. Sampai ketemu di kesempatan selanjutnya.
Tetap semangat belajar AI bersama saya!
Padat dan jelas, sungguh mencerahkan sekali, terimakasih pak. Website ini merupakan website yang berisi penjelasan mengenai AI, ML, DL dalam bahasa indonesia yang paling mudah dicerna dan dipahami. Jadi semangat melanjutkan belajarnya, hehe.
Terima kasih komentarnya. Senang jika bermanfaat ?
Saya sepakat Mas Raihan.
Beberapa website sy buka untuk memahapi konsep mesin learning.. Tapi website yang bisa memberi saya pemahaman lebih baik, khususnya terkait istilah-istilah dalam ML dan DL..
Terimakasih Mas MB Herlambang atas sharing ilmu nya. Semoga berkah
selamat siang, website ini sangat membantu saya memahami ANN dan saya ingin mencoba melanjutkanya ke CNN namun ada yang saya binung tuk proses import image nya bagaimana caranya ya dan apakah ada github nya? terimakasihh
Halo, senang jika bermanfaat.
Di tutorial ini untuk import image kita gunakan folder, jadi gambar-gambar dimasukkan ke dalam 2 folder yang berbeda (bisa dilihat di halaman pertama).
Untuk github sementara tidak saya publish ke umum karena untuk keperluan riset yang codingnya bersifat private.
pertanyaan saya bgaiamankah cara cnn nya melakukan test pada halaman ke 3 tanpa menggunakan weight atau model yg telah di training? apakah pada code result = MesinKlasifikasi.predict(test_image) weoght atau model yang digunakan tadi sudah tersimpan? atau pada halam ke 3 ini menjadi 1 dengan training code? terimakasih
Di halaman 3 kita mencoba untuk menguji kembali model yang sudah kita buat di halaman 2. Jadi ketika kita panggil MesinKlasifikasi otomatis modelnya sudah menyimpan pembelajaran sebelumnya.
Jika ingin melatih – simpan – latih – simpan terus menerus bisa gunakan fitur ‘model.save’ di model Keras kita (ini belum sempat saya bahas, karena di tutorial ini masih bersifat dasar sekali).
Silakan merujuk ke link ini untuk dipelajari: https://keras.io/getting-started/faq/#how-can-i-save-a-keras-model
Semoga menjawab ya
selamat malam ,terimakasih telah menjawab pertanyaan saya sebelumnya saya ada pertanyaan pada halan 2 terdapat hasil training dengan val_los >1.0 dan dan training loss 1.0 dikatakan overfitt? terimakasih
Halo, saya jawab pertanyaannya ya. Jadi overfitting terjadi jika model kita mampu mempelajari pola yang ada di training set. Walau demikian, ia terlalu baik mempelajari polanya, sehingga kemampuan prediksi saat di test set tidak sebaik jika dibandingkan dengan training set. Sementara underfitting terjadi jika model kita tidak bisa mempelajari pola yang ada di training set, sehingga sudah jelas ketika diuji di test set ia tidak bisa melakukan tugasnya dengan baik. Model yang ideal adalah tidak overfitting dan tidak underfitting. Cara melihatnya adalah dengan membuat grafik parameter hasil pengujian, seperti loss vs val_loss, atau acc vs val_acc. Yang sering dihadapi di… Read more »
terimakasihh , mohon maaf pertanyaan saya ambigu maksd saya bukankah val los >1.0 dan loss < 1.0 merupakan overfit, dengan jawaban yg sudah di berikan dapat saya terima terimakasih sekali lagi
Untuk arsitektur CNN seperti ini jika diimplementasikan 10 Cross Fold Validation caranya gimana ya pak?
Untuk Cross Validation dan implementasinya (machine learning maupun deep learning) di materi-materi selanjutnya akan saya bahas.
Ini masih fokus membuat konten pembelajaran di Youtube.
Assalamuallaikum warahmatulahi wabarokatuh, selamat siang, saya mau bertanya, terkait dataset, ketika mencoba membuat dataset untuk klasifikasi lebih dari 2 Class misal kucing, anjing, kambing, atau bahkan banyak class, bagaimana cara mengatur labeling dan foldernya ?
terimakasih
Wa’alaikumsalam. Jika lebih dari 2 class maka ada beberapa hal yang harus dilakukan:
1. Ganti activation function di langkah 4 (line 23) dari ‘sigmoid’ menjadi ‘softmax’.
2. Saat mendefinisikan training_set (line 38) dan test set (line 43) ganti class mode dari ‘binary’ menjadi ‘categorical’.
3. Tambahkan perintah labels=[0,1,2] <-- jika 3 class, sesuaikan dengan jumlah kategorinya 4. Di folder training set dan test set sesuaikan saja fodlernya dengan nama classnya. Kalau ada 3 class ya masing-masing folder memiliki nama classnya, misal kucing, anjing, jerapah. Kapan-kapan akan saya bahas di artikel untuk klasifikasi lebih dari 2 classes kalau sudah tidak sibuk dengan disertasi. Semoga menjawab.
asalamualaikum pak, kalau softmax untuk identifikasi 2 kelas boleh gak pak? saya pakai sigmoid tidak bisa melakukan proses classification pak karena error mulu
Assalamu’alaikum, Pak saya ingin bertanya, kalau kita misalnya ingin membuat aplikasi face recognition dengan CNN yg terdiri dari 20 class (20 orang berbeda) lalu ketika kita ingin prediksi nya dengan webcam, Bagaimana cara kita membuat / mendefinisikan bahwa orang yang tidak termasuk kedalam 20 class atau tidak ada di dalam dataset tersebut di prediksi sebagai “UNKNOWN”? dan berapa jumlah neuron yg seharusnya kita masukkan di Dense terakhir pada output layer pak?, Terima Kasih.
Waálaikumsalam. Ini penjelasannya panjang ini.
Ada banyak cara untuk mencapai ini, bisa pakai Tensorflow (Keras) pakai activation function softmax, pakai OpenCV juga bisa, pakai Theano juga bisa.
Jawabannya mirip dengan jawaban pertanyaan sebelumnya di materi ini.
Kapan-kapan saya bahas detailnya di website ini aplikasi dan codingnya, ini masih fokus ke disertasi saya di kampus.
Harap bersabar ?
Jd Pak, Kalau misalnya mau buat face recognition, jenis data yg dimasukkan di input_shape itu lebih cocok yg rgb (3 channel) atau grayscale (1 channel)? mohon pencerahannya, terima kasih pak
Pakai 3 channel biasanya.
Semoga menjawab.
Pak saya ingin bertanya, kalo misalanya ingin buat face recognition 30 kelas dengan data keseluruhan 50 rb data (train dan validasi) serta data tersebut hasil augmentasi, apakah data dgn jumlah segitu sudah cukup mas? mohon penjelasannya pak terima kasih
Dicoba saja, kalau hasilnya baik berarti cukup datanya.
Aturannya semakin banyak data semakin baik.
Kalau data sudah mentok, maka kualitas data yang menentukan.
Baik pak, oiya pak kalau misalnya data sudah diaugmentasi secara manual, apakah perlu diaugmentasi kembali di dalam program ketika ingin training data, seperti pada halaman ini yaitu dgn ImageDataGenerator (rescale = 1./255, zoom_range = 0, 2, Horizontal_flip=True… dst) apakah ada pengaruhnya untuk data yg sudah diaugmentasi secara manua pak?
Silakan dicoba-coba sendiri untuk melihat efeknya, dengan begitu kita justru bisa belajar banyak.
Tidak ada batasan untuk berkreasi di dunia AI karena ilmunya masih terus berkembang.
Selamat berkreasi!
Oke baik, pak noted, oiya pak kalo misalnya training data tapi hasilnya kadang2 yg validation accuracy lebih tinggi dari pada training accuracy misal 98 % : 96 % atau kadang 99 % : 100 %, itu kenapa bisa begitu ya kira2pak? apakah itu tidak masalah? terima kasih pak
Masih bagus itu, tidak terlampau jauh.
Kecuali kalau satunya 90% satunya 60% baru bermasalah.
Assalamu’alaikum pak, saya ingin bertanya, gimana ya caranya untuk mengatasi validation loss yg naik turun dan beda jauh jaraknya sama training loss? padahal validation accuracy nya sudah cukup bagus dan mendekati training accuracy nya. uda byak eksperimen dilakukan tanpa dan dgn regularization seperti (dropout, L2) dan data augmentation serta sudah juga mencoba menambah atau mengurangi layer convolusi dan pooling, tapi validation loss nya tetep aja naik turun, jumlah data yg saya gunakan 50 ribu. Tampilan grafiknya seperti dibawah ini
Waálaikumsalam. Saya tidak tahu data apa yang diolah.
Coba dipahami datanya, karakteristik data, matrix apa yang dipakai di balik layar (misal kalau gambar adalah pixel, kalau data genetik adalah sequence rantai protein, dll).
Setelah memahami data, telaah apa yang bisa membuat sebuah proses training berhasil untuk data tersebut, baru lanjutkan dengan teknik yang pas dengan datanya.
Banyak tutorial di luar menjelaskan tools (teknik-teknik2) yang hanya pas untuk tipe data dan kasus tertentu, tapi tidak berlaku umum.
Kaidah umumnya, tools mengikuti tipe data, dan bukan tools yang dipaksakan untuk semua jenis data
Semoga menjawab.
data saya data image pak, saya sedang membuat face recognition dgn jumlah class 30, dan dgn split data, train (75 %) = per class 1200 data, val (25 %) = perclass 400 data, uda dicoba manual/offline augmentasi juga pak dgn jumlah data jdi 96 rb, tapi val loss nya msh ga stabil (naik turun) padahal val accuracy ny sudah cukup bagus. Model saya seperti pada gambar dgn 3 hidden layer setelah flatten ().
Assalamu’alaikum, Terimakasih penjelasannya. Saya ingin bertanya, apakah CNN dapat diaplikasikan untuk melakukan prediksi data spasial / data grid?
Misalkan saya memiliki series data curah hujan pengamatan dalam bentuk grid, suhu dan kelembapan udara dalam bentuk grid [X,Y,Z(curah hujan, suhu, kelembapan) dan T(waktu)]. Kemudian saya ingin memprediksi curah hujan tersebut menggunakan data suhu dan kelembapan sebagai prediktor. Apakah ini bisa dilakukan dengan CNN?
Wa’alaikumsalam,
CNN umumnya digunakan untuk klasifikasi.
Solusi dari pertanyaan ini adalah menggunakan pendekatan regresi. Bisa dicoba menggunakan multiple regression baik metode linear maupun non-linear.
Semoga menjawab.
Terimakasih pak atas responnya.
Selain menggunakan pendekatan regresi, apakah pendekatan RNN juga dapat diaplikasikan pada kasus prediksi seperti di atas?
RNN juga bisa digunakan.
Terima kasih utk penjelasan mengenai deep learning. Saya mau bertanya di bagian ‘dataset/training_set’ apakah folder dataset tsb harus 1 folder dgn aplikasi deeplearning yg dibuat?
Iya harus 1 folder.
trimakasihbanyak penjelasanya mencerahkan bangut bagi kami para pemula.
Apakah ada email atau apapun yang bisa saya hubungi untuk diskusi?
Apakah jika val_loss naik berarti model tidak baik? bagaimana menurunkan val_loss?
val_loss adalah nilai cost fuction dari test set. Naik bisa jadi pertanda overfitting, tapi bukan berarti tidak baik, tergantung jenis data, algoritma, dll.
Solusinya sudah dibahas di artikel ini termasuk di bagian komentar.
assalamualaikum mohon pencerahanya saya ada tugas akhir perkuliyahan tentang menghitung kerumunan orang menggunakan CNN minta tolong saranya pak saya kebingungan bagaimana cara saya menghitungnya sedangkan setau saya CNN cuma buat klasifikasi untuk deteksi objek saja.. mohon pencerahanya dan trimakasih banyak.
Wlkmslm, deteksi saja jumlah orang, kemudian dihitung ada berapa total orangnya, simpel 👍
trimakasih banyak saranya pak akan tetapi saya masih bingung untuk memisahkan background dengan objek orangnya bagaimana pak? misal dalam sebuah pusat perbelanjaan, kan banyak objek bukan hanya orang terus untuk memisahkan objek-objek tersebut bagaimana pak? saya masih belum faham mohon sangat pencerahanya.
terimakasih banyak
Kalau untuk deteksi suara seperti membedakan suara alat musik, apakah hampir mirip-mirip ya untuk code nya ? Apakah cuman berbeda di data set nya saja ? Terimakasih
Saya belum pernah mengolah data musik. Sepertinya harus ada preprocessing raw datanya terlebih dahulu merubah suara menjadi data numerik, dan training setnya harus sudah ada labelnya. Selebihnya menggunakan ANN seperti biasa.
Pak mau tanya bagian yang terakhir ini semisal kita cma gambar untuk test nya cma 3 apa bisa?
Untuk test bisa2 saja tidak masalah, karena dia tugasnya hanya menguji (testing). Yang penting modelnya sudah jadi dengan baik (perlu banyak data training set).
Apa menambahkan epoch tanpa memperbaiki arsitektur cnn dapat menghindarkan terjadinya overfitting?
Kemudian training itu dikatakanan optimal
apabila ?
Menambah epoch terlalu banyak justru bisa overfitting.
Untuk melihat optimal atau tidak, buat plot perbandingan acc dan loss untuk training set dengan valdation set (atau test set).
Permisi pak izin bertanya..
Menurut bapak, rasio yang baik utk pemabagian dataset yang terbilang sedikit hanya sekitar 300 citra seperti apa ya pak?
Saya membagi dataset sebanyak 80% yaitu (training dan validasi) masing-masing adalah 210 citra dan 30 citra (akan sy gunakan utk proses training/pembuatan model classifier)
kemudian 20% untuk testing (60 citra) diuji melalui GUI mobile (andorid)
apakah rasio diatas cukup baik pak? atau sebaiknya sy mengurangi jumlah data testing, dan menambahkannya menjadi data (training/validasi) agar hasilnya semakin baik?
Mohon jawaban masukkannya pak. Terimakasih..
Tidak ada aturan baku apakah 80:20, 70:30 bahkan 60:40.
Intinya semakin banyak data untuk training, maka semakin bagus.
Kalau kepepet karena datanya sedikit, banyakin ke trainingnya saja.
Oh bgitu ya pak.. 1 lagi pak mohon pencerahannya.. Kasus yang sedang sy alami adalah dataset yang sangat sedikit. yaitu citra daun cabai yang terserang hama Saya melakukan proses pengambilan data (pemotretan langsung) dgn beberapa parameter (jarak antara objek dan kamera, intesitas cahaya dll) Namun, berhubung objek yang sy kumpulkan sangat sedikit, sy melakukan augmentasi secara manual pada saat pemotretan seperti merotasi objek daun tsb atau mengacak sudut pemotretan yg sy lakukan.. misalnya sy memiliki 15 citra daun per kelas, setiap daun sy lakukan 10 kali parubahan sudut saat pemotretan. dan total data yg saya dapat kan 150 citra per… Read more »
Iya ini tidak apa-apa, malah menurut saya normal-normal saja.
Ilustrasi lain adalah ketika mentraining objek jeruk, maka kita foto jeruk dari berbagai sudut.
Jadi lanjutkan saja 👍
bintang 5 artikelnya
Permisi Pak,link datasetnya tidak bisa di akses pak mohon solusinya
Sudah diperbaiki linknya.
Sekarang bisa diakses kembali.
Luar biasa pak. sungguh bermanfaat bagi saya yg baru memulai :).
kenapa setelah saya coba running, terdapat eror di line 38 ya pak?