

Bagaimana SOM Belajar?
Cara SOM belajar (menentukan kelompok untuk setiap data point) sangat mirip dengan K-means clustering. Apalagi jika neuron yang digunakan oleh SOM berjumlah sedikit, maka SOM akan menjadi seperti K-Means. Oleh karena itu, jika pembaca belum membaca artikel saya tentang K-means, saya harapkan pembaca membacanya terlebih dahulu, sehingga bisa mendapatkan gambaran tentang apa itu clustering.
Sekarang mari kita bahas proses dari SOM itu sendiri. Lebih mudahnya mari kita lihat ilustrasi berikut ini.

Ilustrasi di atas adalah contoh bagaimana jika kita memiliki 4 fitur dan ingin kita petakan ke dalam 8 nodes (neurons). Kita juga bisa katakan bahwa kita ingin memetakannya ke dalam grid ukuran 2×4.
Empat buah fitur yang dimaksud dalam ilustrasi di atas adalah 4 kolom dalam sebuah tabel dataset. Dengan kata lain, kita juga bisa mengatakan bahwa dataset kita memiliki 4 dimensi, di mana masing-masing dimensi mewakili fitur sendiri-sendiri (misal dalam memetakan kemiskinan, kolom pertama adalah pendapatan, kolom kedua lokasi, kolom ketiga hutang, dan kolom keempat aset). Jumlah baris dari dataset berbentuk tabel ini merepresentasikan jumlah itemnya (misal jumlah penduduk/jumlah item, dll).
Satu hal yang perlu dicatat bahwa SOM adalah sebuah teknik untuk mereduksi dimensi yang banyak menjadi 2D (2 dimensi) saja. Lalu di mana representasi gambar 2D pada ilustrasi di atas?
Representasi 2D nya terletak di output neurons (nodes), di mana 8 nodes ini dipetakan kepada sebuah bidang datar berwarna krem. Jadi saya harap pembaca bisa memahami, bahwa 8 output nodes ini berusaha untuk dipasangkan (ditempelkan) ke dalam sebuah bidang 2D. Kemudian masing-masing input neuron ini terhubung dengan node yang terpilih (node yang memiliki jarak terdekat).
Walau demikian, arsitektur NN di SOM agak berbeda. Garis yang menghubungkan antara input dan output tidak merepresentasikan hubungan layaknya neural networks (NN) pada umumnya, di mana nanti akan ada proses forward dan back propagation, SOM tidak akan ada proses ini. SOM juga tidak memiliki activation function. Perlu diingat bahwa garis yang menghubungkan antara input nodes (kolom di tabel) dengan output nodes hanyalah ilustrasi perhitungan kedekatakan input nodes dengan output nodes saja.
Jika kita asumsikan setiap kolom terhubung dengan semua nodes (hubungan garis hanya ilustrasi perhitungan jarak) maka tampilannya mirip dengan neural networks (NN). Untuk mempermudah pembahasan (kita akan bahas mengenai bobot), saya agak sedikit ubah bentuk networknya dari 2×4 menjadi 1×8 seperti di bawah ini:

Arsitektur SOM juga memiliki bobot (weights, yang direpresentasikan dengan simbol W), namun memiliki pengertian yang berbeda dengan bobot di NN. Jika di NN secara umum, W adalah bobot yang berfungsi untuk menentukan solusi optimum melalui proses back propagation, maka W di SOM hanya merepresentikan karakteristik (koordinat) masing-masing node nya.
Algoritma SOM
Sebelum kita memulai proses iterasi SOM, kita tentukan dulu ukuran grid (peta 2D) nya, di mana ukuran grid direpresentasikan oleh jumlah output neuron (nodes).
Formula untuk menghitung jumlah output neuron berdasarkan sebuah paper adalah sebagai berikut:
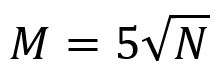
di mana N adalah jumlah baris dalam tabel dataset kita, dan M adalah jumlah output neuron berupa nilai integer (angka pembulatan). Jika kita memiliki 10000 baris di dataset kita, maka jumlah output neuron nya ada 500 nodes.
Setelah itu barulah kita menormalisasi semua nilai di input nodes (vektor input). Dengan demikian nilai input ini memiliki rentang antara 0-1. Proses normalisasi kita sering sebut dengan istilah feature scaling.
Jika sudah menormalisasi data input, langkah selanjutnya adalah menentukan nilai awal setiap bobot untuk semua output neuron. Nilai bobot ini juga memiliki rentang antara 0-1.
Setelah 3 tahap awal di atas kita lakukan, barulah kita masuk ke iterasi (prosedur) algoritma SOM:
- Tentukan secara random baris data di dataset yang akan dipilih, untuk kemudian ditempatkan di node yang sesuai (terdekat).
- Cari node (best matching unit – BMU) yang terdekat dari data yang terpilih di tahap 1 dengan cara melihat jarak euclideannya terkecil terhadap semua output neurons.
- Update nilai bobot untuk neurons yang menjadi tetangga dari BMU tadi. Neurons yang dipilih hanya jika neurons tetangga ini berada di dalam radius BMU. Besarnya radius ini ditentukan oleh sebuah formula, dan ukuran radius semakin lama semakin mengecil hingga menjadi seukuran dari neuron BMU itu sendiri.
- Dekatkan semua neurons tetangga ke BMU di tahap 3.
- Ulangi terus sampai semua baris di dataset masuk ke sebuah output neuron.
Formula untuk nenentukan radiusnya berdasarkan link ini adalah sebagai berikut:
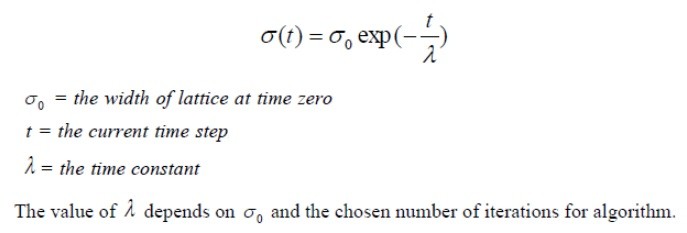
Di mana formula di atas sama dengan formula di bawah ini yang lebih detail, yang merujuk ke paper ini:

Formula yang digunakan untuk mengupdate nilai bobot BMU dan bobot tetangganya berdasarkan paper di atas adalah sebagai berikut:

Untuk memudahkan memahami konsep tahapan SOM di atas yang sangat matematis, mari kita lihat ilustrasi berikut ini:
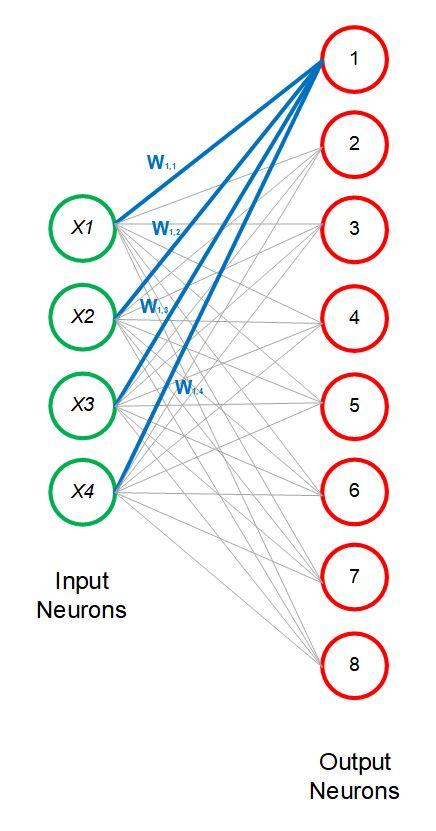
Untuk output node pertama ia memiliki 4 bobot yaitu W1,1; W1,2 ;W1,3 dan W1,4. Jika ada banyak kolom (banyak dimensi), 20 dimensi misalnya, maka bobot yang dimiliki oleh node pertama juga akan sampai 20 (W1,20 artinya adalah bobot dari input neuron ke-20 untuk neuron k- 1).
Untuk ilustrasi di atas, jika semuanya kita tuliskan bobotnya, maka kurang lebih menjadi seperti ini:
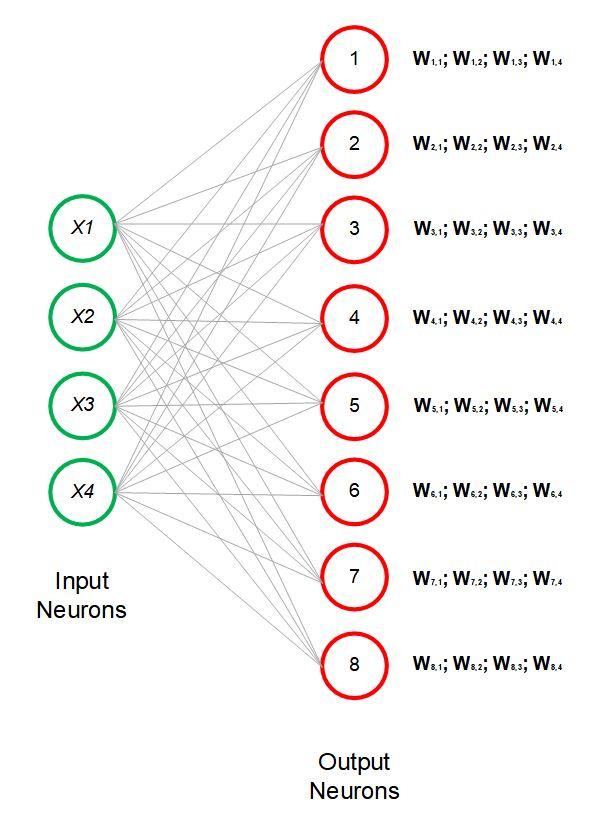
Sekali lagi perlu ditekankan, bahwa bobot (W) adalah karakteristik unik yang dimiliki oleh setiap output node. W1,2 artinya adalah karakteristik unik node ke-1 yang berasal dari kolom (dimensi) ke 2. Karakteristik ini akan diterjemahkan nanti berupa koordinat posisi dari node tersebut di dalam peta 2 dimensi. Nilai W akan terus diupdate untuk menentukan koordinat yang yang paling tepat.
Mirip dengan K-Means Clustering, setiap titik (satu baris dalam tabel) akan berkompetisi dengan 8 output nodes ini. Mana jarak output node yang terdekat bagi titik tersebut, maka ia akan masuk ke node tersebut. Jika sebuah node terpilih, maka ia akan menampung beberapa baris data ke node tersebut. Dengan demikian, sebuah output node bisa memiliki banyak baris data yang masuk ke dalamnya.
Formula yang digunakan untuk menghitung jarak adalah dengan meghitung jarak euclidean-nya (euclidean distance). Formula dari jarak euclidean ini adalah sebagai berikut:
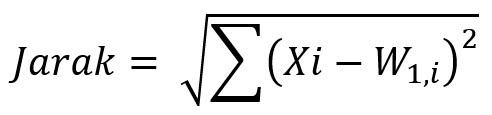
Jadi setiap data di sebuah baris untuk setiap kolom akan dikurangkan dengan bobot yang dimiliki oleh kolom tersebut. Setelah itu hasil pengurangannya dijumlahkan untuk semua kolom, kemudian dikuadratkan dan dicari nilai akarnya.
Berikut ilustrasi jika kita hitung jarak euclidean di masing-masing output node untuk baris pertama dalam tabel dataset:

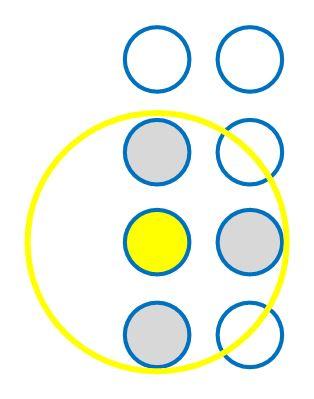
Gambar di atas menunjukkan nilai jarak euclidean untuk data baris pertama. Bisa dilihat bahwa baris pertama memiliki jarak terdekat dengan output node ke-3 (nilai 0.4). Oleh karena itu, data baris pertama akan masuk ke output node ke-3.
Dalam istilah SOM, kita menyebutkan proses masuknya sebuah data point ke dalam sebuah output node dengan sebutan BMU (best matching unit).
Setelah itu kita petakan nilai baris pertama ke sebuah peta 2D. Nilai bobot yang dimiliki oleh output node ke-3 akan menentukan koordinatnya di peta 2D.
Ilustrasi penempatan data baris pertama ke node ke-3 adalah sebagai berikut:

Kemudian semua nodes yang masuk ke dalam radius BMU ini akan terupdate nilai bobotnya dan semakin mendekat ke BMU ini. Semakin dekat sebuah node dengan BMU maka semakin kuat perubahan update W nya.
Yang dimaksud dengan nodes mendekat ke BMU adalah warna nodes tersebut akan semakin mirip dengan warna neuron BMU.
Ilustrasinya nodes yang terupdate nilai W nya (berwarna abu-abu) karena masuk ke dalam radius BMU adalah sebagai berikut:
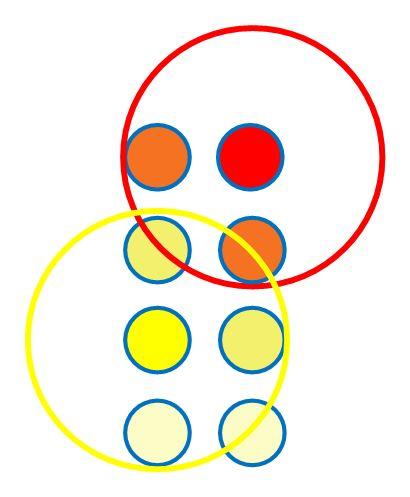
Sekarang kita coba berlaih ke baris kedua di tabel dataset kita. Anggap terpilih sebuah BMU untuk baris kedua ini menjadi seperti berikut:

Sekarang kita memiliki 2 BMU, tentunya masing-masing akan memiliki radiusnya sendiri-sendiri. Semua nodes yang masuk ke radiusnya akan diupdate mendekati BMU nya. Jadi jika ada neuron masik ke 2 radius BMU sekaligus, maka ia akan diupdate menuju kedua BMU ini, dengan catatan bahwa BMU terdekat akan memberikan pengaruh yang terkuat (menarik paling kuat mendekati BMU ini).
Dengan demikian tampilannya menjadi seperti ini:
Begitu seterusnya sampai kita sudah berhasil menempatkan setiap baris di dataset ke masing-masing nodes yang ada.
Anggap kita memiliki 3 kluster utama, maka ilustrasi akhirnya kurang lebih akan menjadi seperti ini:

Hal yang perlu diperhatikan bahwa ilustrasi di atas tentunya sangat sederhana. kita hanya memiliki 8 output neurons (2×4) di mana pada aplikasi nyata ukuran grid (jumlah neurons) bisa sangat banyak, misal 20×20 (400 neurons) dan banyak variasi lainnya. Semakin besar ukuran grid maka semakin bagus juga visualisasinya.
Berikut adalah contoh nyata aplikasi SOM di sebuah jurnal internasional, di mana SOM berhasil memetakan teknik spectroscopy sebuah laser plasma.

Sampai di sini saya harap pembaca bisa mendapatkan gambaran banyaknya aplikasi dari teknik SOM. SOM sangat tepat dipakai oleh pengambil keputusan (decision maker), karena ia akan bisa melihat hubungan antar banyak variabel secara singkat dalam sebuah representasi grafis 2 dimensi.
Di artikel selanjutnya saya akan tunjukkan bagaimana kita bisa menggunakan SOM untuk mendeteksi kecurangan aplikasi kartu kredit oleh nasabah di dunia perbankan.
Jika ada pertanyaan silakan tulis komentar di bawah.
Tetap semangat belajar AI.
Terima kasih.
Pages: 1 2
Alhamdulillah sangat membantu
Bagus sekali artikelnya. Izin saya kutip untuk mengajar