
")
Catatan penting : Jika pengunjung benar-benar awam tentang apa itu Python, silakan klik artikel saya ini. Jika Anda awam tentang R, silakan klik artikel ini.
Jika pengunjung belum memahami tentang LDA, ada baiknya membaca artikel saya yang membahas tentang teorinya di link ini.
Di artikel kali ini kita akan belajar bagaimana mengaplikasikan LDA (Linear discriminant analysis) untuk kasus nyata. Sama seperti kasus yang sudah bahas di pembahasan PCA, kita juga akan memecahkan permasalahan yang sama di mana kita akan mengolah data milik perusahaan produsen minuman anggur (wine).
Perusahaan ini memiliki dataset dengan banyak kolom. Ia ingin membagi-bagi kriteria (karakteristik) komposisi wine yang pas untuk setiap segmen pelanggannya (ada 3 segmen). Dengan banyaknya kolom data, ia kesulitan untuk membuat visualisasinya dan meminta bantuan kita sebagai seorang data scientist.
Kita akan selesaikan permasalahan ini dengan menggunakan bahasa Phyton dan R.
Silakan mengunduh (donwload) datasetnya di link ini.
Ilustrasi datasetnya adalah sebagai berikut:

Bahasa Python
# Mengimpor library yang diperlukan
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Mengimpor datasetnya
dataset = pd.read_csv('Wine.csv')
X = dataset.iloc[:, 0:13].values
y = dataset.iloc[:, 13].values
# Membagi data ke dalam Training set dan Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Proses Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Menjalankan algoritma LDA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
lda = LDA(n_components = 2)
X_train = lda.fit_transform(X_train, y_train)
X_test = lda.transform(X_test)
# Menjalankan algoritma logistic regression ke training set
from sklearn.linear_model import LogisticRegression
mesin_klasifikasi = LogisticRegression(random_state = 0)
mesin_klasifikasi.fit(X_train, y_train)
# Memprediksi test set berdasakan model logistic regression
y_pred = mesin_klasifikasi.predict(X_test)
# Membuat confusion matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
# Visualisasi Training Set
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, mesin_klasifikasi.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green', 'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i), label = j)
plt.title('Logistic Regression (Training set)')
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.legend()
plt.show()
# Visualisasi Test Set
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, mesin_klasifikasi.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green', 'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i), label = j)
plt.title('Logistic Regression (Test set)')
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.legend()
plt.show()
Penjelasan:
- Pada dasarnya sebagian besar script nya mirip dengan yang ada di pembahasan aplikasi PCA.
- Line 2-4 mengimpor library yang diperlukan.
- Line 7 mengimpor dataset yang diperlukan.
- Line 8 dan 9 melakukan slicing untuk X (variabel independen) dan y (variabel dependen). Kita memerlukan kolom terakhir (paling kanan) sebagai y, dan sisanya sebagai X.
- Line 12 mengimpor library yang diperlukan untuk membagi dataset ke dalam training dan test set.
- Line 13 membagi dataset ke training dan test set dengan komposisi 80:20.
- Line 16-19 melakukan proses feature scaling untuk X_train dan X_test. Artinya kita menyamakan satuan (skala) untuk semua kolom di variabel X_train dan X_test.
- Line 16 mengimpor library untuk proses feature scaling.
- Line 17 mendefinisikan objek dengan nama sc untuk proses feature scaling. Kita cukup menggunakan perintah StandardScaler.
- Line 18 melakukan proses feature scaling untuk X_train dengan perintah fit_transform.
- Line 19 melakukan proses feature scaling untuk X_test dengan perintah transform. Hasil dari feature scaling adalah sebagai berikut:
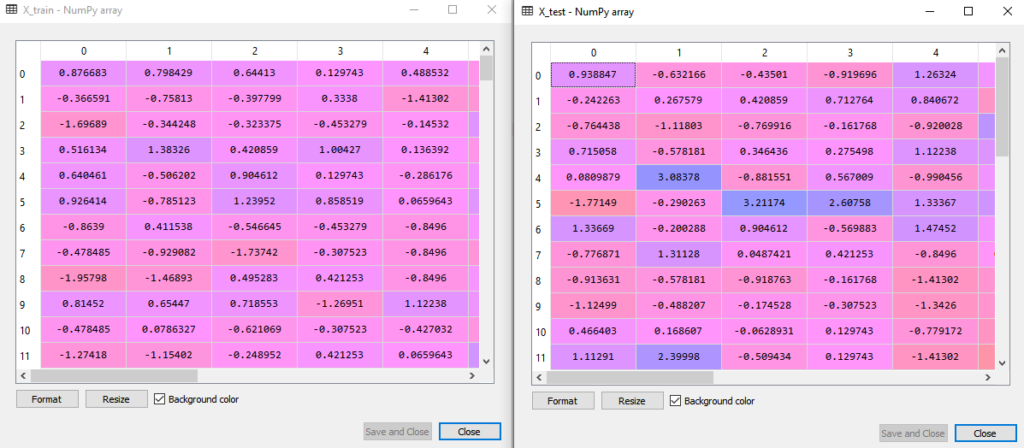
- Line 22 menginpor library yang diperlukan untuk menjalankan algoritma LDA. Kita gunakan library LinearDiscriminantAnalysis dari sklearn.discriminant_analysis.
- Line 23 kita definisikan variabel (objek) dengan nama lda untuk menjalankan algoritma LDA itu sendiri. Parameter yang diperlukan adalah n_components = 2, artinya kita ingin membuat 2 linear discriminants (2 LDs) saja. Dengan demikian, kita akan memiliki 2 variabel independen baru (LD1 dan LD2) yang merupakan ringkasan dari beberapa kolom variabel independen X. Mengapa kita memilih sebanyak 2 komponen? Karena kita memerlukan 2 sumbu untuk visualisasi 2 dimensi (2D) nantinya.
Berbeda dengan PCA, di mana setelah kita buat objek PCA kita melakukan pengecekan variasi (variance) terlebih dahulu, di LDA kita tidak perlu melakukannya karena kita tidak tertarik dengan berapa banyak variance yang bisa dijelaskan oleh LDs (linear discriminants) yang dihasilkan.
Hasil dari 2 linear discriminants (LD1 dan LD1) di training dan test set adalah sebagai berikut:

- Line 24 mengaplikasikan hasil perhitungan LDA ke X_train dengan menggunakan perintah fit_transform .
- Line 25 melakukan proses transform hasil perhitungan LDA ke X_test.
- Line 28 mengimpor library yang diperlukan untuk proses regresi logistik (logistic regression). Tentu saja pembaca bisa menggunakan teknik klasifikasi lain seperti SVM (support vector machine), decision tree, random forest, dan lain-lain.
- Line 29 mendefinisikan objek (variabel) dengan nama mesin_klasifikasi untuk proses klasifikasi menggunakan logistic regression. Kita gunakan perintah LogisticRegression dengan bilangan random (random_state = 0). Artinya jika pembaca ingin mendapatkan hasil yang sama, maka gunakan nilai random_state yang sama pula.
- Line 30 melakukan fitting / menjalankan algoritma logistic regression yang sudah ada di variabel mesin_klasifikasi ke training set kita (X_train dan y_train).
- Line 33 mendefinisikan objek (variabel) y_pred untuk memprediksi hasil klasifikasi yang sudah dipelajari oleh mesin_klasifikasi. Nantinya kita bandingkan y_pred ini dengan y_test (test set yang asli).Hasil dari y_pred adalah sebagai berikut:
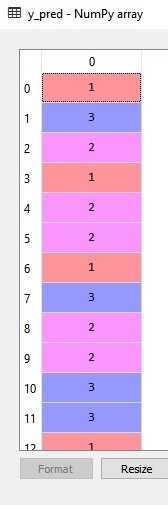
- Line 36 mengimpor library yang diperlukan untuk membuat confusion matrix.
- Line 37 mendefinisikan objek cm untuk confusion matrix. Hasilnya adalah sebagai berikut:

Kita lihat bahwa LDA menghasilkan pembagian yang sempurna. Tidak ada kesalahan klasifikasi sedikitpun dengan tingkat akurasi 100%. Sebanyak 14 data berhasil kita klasifikasikan di segmen konsumen 1, 16 data di segmen konsumen 2, dan 6 data di segmen konsumen 3.
Sekarang mari kita bandingkan hasilnya dengan PCA:

Dengan metode PCA yang sudah kita bahas di artikel sebelumnya, kita bisa melihat ada 1 kesalahan klasifikasi, di mana yang seharusnya masuk kelompok 1 justru masuk di kelompok 2.
LDA sangat cocok digunakan untuk teknik klasifikasi, karena sejak awal proses algoritma dijalankan, ia sudah melakukan proses pembentukan sumbu-sumbu baru (linear discriminants) dengan mencari jarak terjauh dari masing-masing kelompok data (baca lagi teori LDA di artikel saya).
Sekarang kita ingin melihat hasil visualisasinya.
- Line 40-55 adalah perintha untuk visualisasi training set.
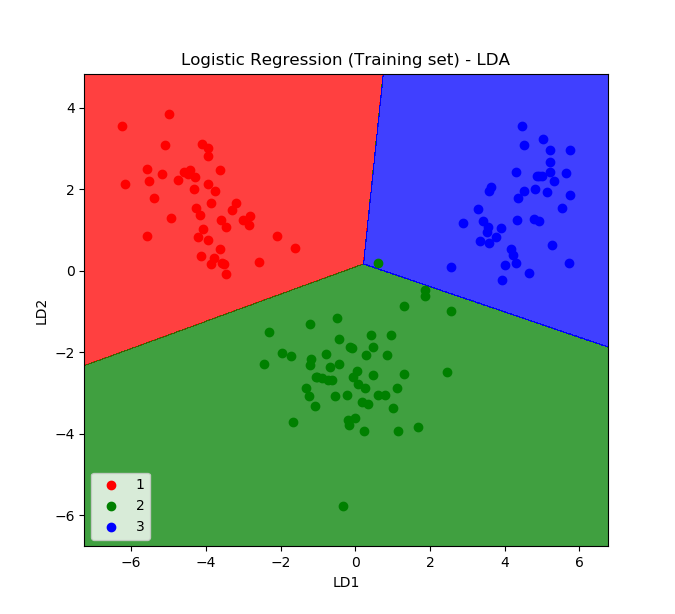
Terlihat secara visual ada 1 titik yang salah masuk klasifikasi (titik hijau masuk ke zona biru). Namun hasil ini jauh lebih baik jika dibandingkan dengan PCA.
Berikut training_set hasil PCA:

Bisa dilihat di training_set PCA, terdapat lebih banyak kesalahan klasifikasi jika dibandingkan LDA. Sekarang kita lihat hasil prediksi test_set nya.
- Line 58-72 adalah perintah untuk visualisasi test_set. Hasilnya adalah sebagai berikut:

Terlihat secara visual bahwa pengklasifikasian dengan menggunakan LDA memberikan hasil yang memuaskan. Sekarang kita coba bandingkan dengan PCA yang sempat dibahas di artikel sebelumnya.
Visualisasi test set PCA adalah sebagai berikut:
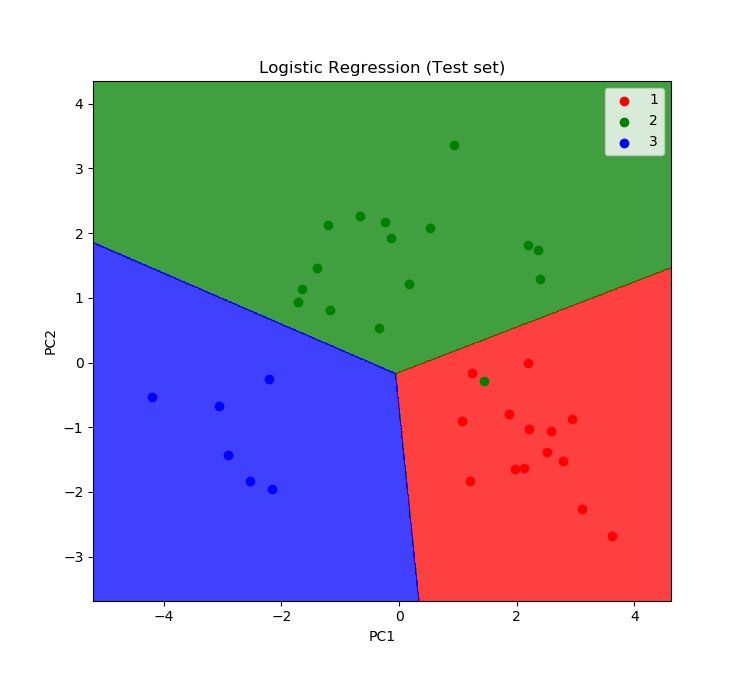
Bisa kita simpulkan bahwa LDA (linear discriminant analysis) memberikan hasil klasifikasi yang lebih baik (akurasi lebih tinggi) jika dikombinasikan dengan teknik klasifikasi klasik machine learning, baik itu logistic regression, support vector regression, dan lain-lain.
Saya harap pembaca bisa memahami apa itu teknik LDA dan penggunaannya. Saya harap pembaca bisa menggunakannya untuk memecahkan permasalahan nyata yang dihadapi dan cukup sesuaikan datasetnya dengan dataset yang dimiliki.
Jika ingin belajar aplikasi LDA menggunakan bahasa R, silakan klik tombol ke halaman selanjutnya di bawah ini.
Pages: 1 2
Selamat pagi, Pak
Bisa request teori dan implementasi survival analysis kaplan meier ???
Terima kasih requestnya. Akan saya pertimbangkan untuk artikel-artikel selanjutnya.
Mohon dipertimbangkan pak, karena topik ini menarik bagi saya (semoga yang lain juga), terima kasih banyak pak ??????
Assalamualaikum wr.wb. Bp. Bagus, perkenalkan saya Bp. Usman, mohon ijin bertanya:
line 20: training_set_lda = training_set_lda[c
(5, 6, 1)]
c(5, 6, 1) fungsinya untuk apa ya? kenapa 5, 6, 1?
Line 35,36: Confusion Matrix di laporan tidak keluar
grid_set hasil dari proses apa? hasil eksekusi 1297076 obs. of 2 variables
Wa’alaikumsalam. Untuk keterangan masing-masing line bisa dilihat di bagian penjelasan di bawahnya.
Assalamualaikum, pak
Izin bertanya pak, Aplikasi yang bapak, gunakan untuk implementasi program diatas apa ya pak?
dan cara bapak memanggil hasil numpy array dari x_train dan x_test seperti pada line 19 bagaimana ya pak? soalnya saya gunakan visual code, tidak terpanggil hasil arraynya seperti yang dicontoh.
Wa’alaikumsalam.
Saya menggunakan Spyder.