

STUDI KASUS
Kali ini kita akan coba memecahkan masalah dari klien kita. Ia merupakan seorang pemilik showroom mobil. Saat ini ia memberikan kepada kita data pelanggannya berupa:
- User ID
- Jenis kelamin
- Usia (dalam tahun)
- Estimasi gaji (gaji per 6 bulan, dalam ribu rupiah. Misal, 8000 artinya 8 juta)
- Keputusan beli atau tidak
Ia ingin membuat sebuah sistem yang bisa memprediksi apakah calon pelanggan ke depannya akan membeli produk SUV di showroomnya atau tidak berdasarkan data usia dan gaji. Sehingga ke depannya, ia ingin membuat iklan di sosial media/internet yang dia targetkan ke mereka saja yang kemungkinan besar akan membeli produknya.
Sebelum kita memulai dengan dua bahasa (Python dan R), pembaca bisa download datasetnya di sini.
Bahasa Python
# Mengimpor library
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Mengimpor dataset
dataset = pd.read_csv('Iklan_sosmed.csv')
X = dataset.iloc[:, [2, 3]].values
y = dataset.iloc[:, 4].values
# Membagi data ke dalam training dan test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Membuat model regresi logistik dari training set
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, y_train)
# Memprediksi hasil modelnya ke test set
y_pred = classifier.predict(X_test)
# Membuat Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
# Memvisualisasikan hasil training set
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Logistic Regression (Training set)')
plt.xlabel('Usia')
plt.ylabel('Estimasi Gaji')
plt.legend()
plt.show()
# Memvisualisasikan hasil test set
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Logistic Regression (Test set)')
plt.xlabel('Usia')
plt.ylabel('Estimasi Gaji')
plt.legend()
plt.show()
Penjelasan:
- Line 2 sampai 4 adalah mengimpor libraries yang diperlukan.
- Line 7 adalah mengimpor datasetnya.
- Line 8 adalah menentukan variabel independen X yang merupakan kolom usia dan gaji. Untuk bisa memilih kolom usia dan gaji, kita melakukan teknik slicing.
- Line 9 adalah menentukan variabel dependen Y yang merupakan kolom terakhir (keputusan membeli atau tidak).
- Line 12 mengimpor library untuk membagi ke test dan training set dari sklearn
- Line 13 membagi training dan test set, dengan 25% untuk test, dan 75% untuk training set.
- Line 16 mengimpor library untuk feature scaling.
- Line 17-19 melakukan feature scaling.
- Line 22 mengimpor regresi logistik dari sklearn
- Line 23 mendefinisikan variabel (object) classifier dengan random state nol.
- Line 24 membuat model regresi logistiknya dengan cara melakukan fitting variabel classifier ke training set (X_train dan y_train). Intinya adalah model regresi logistik kita akan belajar mencari hubungan antara X_train dengan y_train melalui formula regresi logistik.
- Line 27 memprediksi hasil dari model regresi yang dibuat di line 24 terhadap X_test. Kita definisikan variabel (object) y_pred sebagai hasil prediksinya. Jika pada line 24 metode yang digunakan adalah fit maka untuk prediksi, metodenya adalah predict. Sebagai tambahan bahwa dalam bahasa matematis y_pred ini adalah sebuah vektor (vector).
- Line 29-31 adalah untuk melihat performa model kita, apakah hasil y_pred di line 27 sama dengan y_test yang sudah ketahui. Kali ini kita lakukan dengan membuat confusion matrix.
- Line 30 mengimpor library confusion_matrix dari sklearn.
- Line 31 mendefinisikan variabel cm sebagai hasil confusion matrix antara y_test dan y_pred.
Tips : Jika pembaca bingung apa itu confusion matrix, maka cukup arahkan kursor ke line 31 pada bagian confusion matrix, lalu ketik CTRL+i secara bersamaan untuk melihat parameter apa saja yang diperlukan sekaligus pengertian dari confusion matrix. Tampilannya akan tampak sebagai berikut:

Langkah selanjutnya, coba klik 2x pada variabel cm di bagian variabel explorer. Jika sudah, tampilannya akan seperti ini:

Perhatikan pada tabel di atas pada bagian kiri atas (pasangan 0 dan 0) dan kanan bawah (pasangan 1 dan 1) merupakan prediksi yang tepat. Kita memiliki 65 prediksi benar bahwa data poin memutuskan untuk tidak membeli, dan 24 data poin memutuskan untuk membeli, total 89.
Sekarang pada tabel di atas, fokus pada bagian kanan atas (pasangan 0 dan 1) dan kiri bawah (pasangan 1 dan 0). Kita memiliki prediksi yang keliru (misal, prediksi 0 padahal data aslinya 1) sebanyak 3 dan 8 buah, total 11 buah.
Secara umum, model kita sudah cukup baik. Dari 100 data poin y_test, model kita memiliki akurasi 89%.
- Hasil regresi logistik di atas bisa dilihat melalui perintah line 34-49 untuk training set, dan line 52-67 untuk test set.
Tampilan regresi logistik untuk training set adalah sebagai berikut:
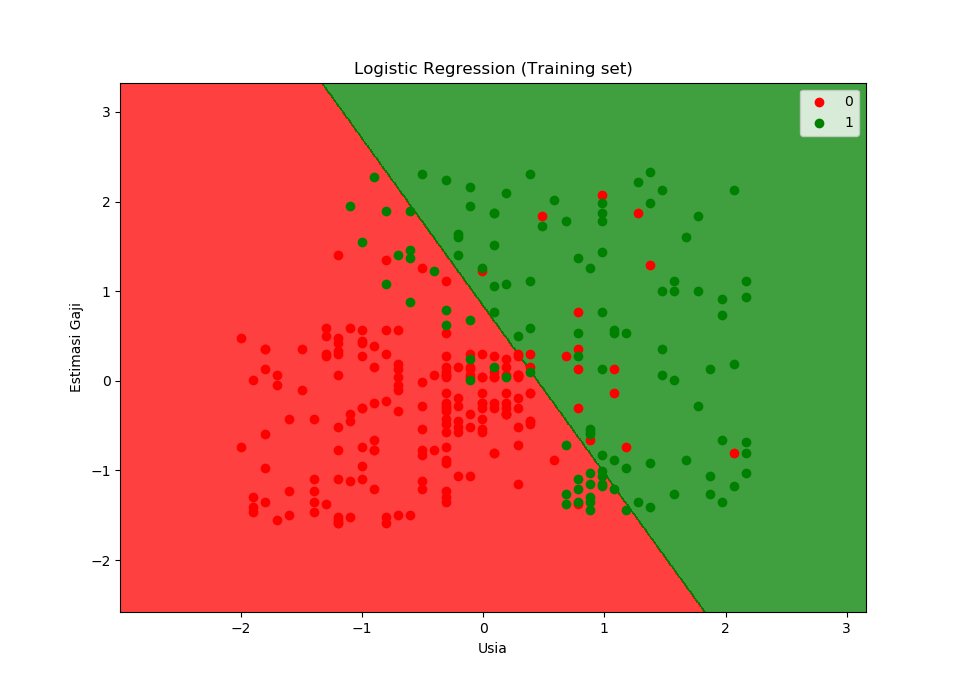
Gambar ini adalah hasil prediksi keputusan beli/tidak berdasarkan usia dan gaji yang dimiliki pelanggan.
Sekarang mari kita interpretasikan gambar di atas.
Hambar di atas adalah hasil regresi logistik dari data training set. Artinya model kita belajar dari training set.
Titik-titik merah adalah data poin di mana pelanggan memutuskan untuk tidak membeli. Sementara titik-titik hijau adalah data poin di mana pelanggan memutuskan untuk membeli SUV.
Garis diagonal adalah boundary line (garis pembatas), yang membatasi antara zona merah (zona tidak membeli) dan zona hijau (zona membeli). Dua zona ini adalah hasil pembagian dari regresi logistik. Karena regresi logistik adalah masuk dalam kategori linear, maka garis pembaginya (pembatas) adalah garis lurus. Dengan garis lurus ini, tentu saja memiliki kekurangan, semisal di zona merah kita masih bisa melihat ada beberapa data poin berwarna hijau di situ. Begitu sebaliknya di zona hijau, juga ada beberapa data poin merah di situ.
Karena sudah melalui feature scaling, maka nilai sumbu x dan sumbu y berkisar dari -2 hingga 2. Untuk membacanya perlu diingat bahwa nilai nol (0), merupakan rataan dari data awal.
Bisa dikatakan bahwa model ini mampu memprediksi di mana mereka yang berpenghasilan tinggi dan berusia di atas rata-rata (rata-rata dari usia training set) cenderung memutuskan untuk membeli. Sementara mereka yang berpenghasilan kecil dan berusia di bawah rata-rata, cenderung memutukan untuk tidak membeli SUV. Oleh karena itu, sebaiknya pemilik usaha fokus mengiklankan produknya di internet di zona hijau saja.
Note: Kali ini kita membahas klasifikasi yang bersifat linear, di sesi selanjutnya kita bahas teknik klasifikasi untuk data non-linear yang bisa jadi akan memberikan hasil lebih akurat.
Jika kita mengeksekusi line 53-67, maka prediksi regresi logistik untuk test set akan tampak sebagai berikut:
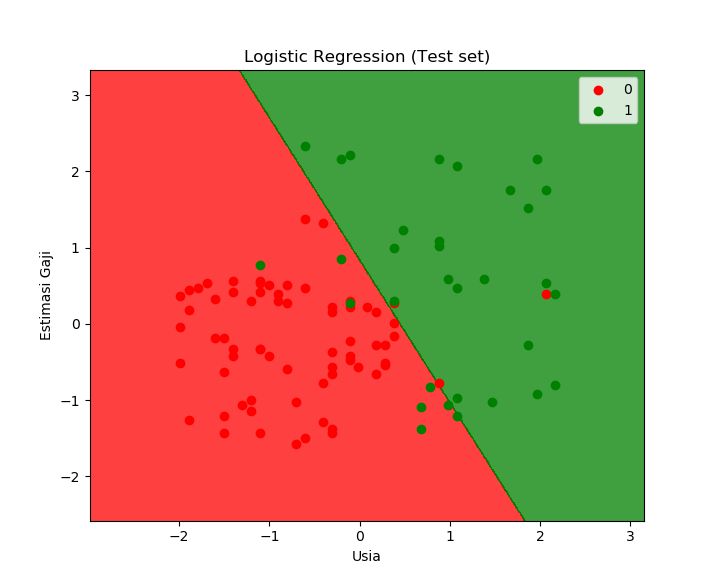
Dapat dilihat bahwa hasilnya cukup baik.
Jika melihat prediksi di atas, maka hasilnya cukup baik. Melalui confusion matrix kita mengetahui bahwa akurasinya 89%.
Melalui model ini (visualisasi training set dan test set), maka kita bisa memberikan saran kepada pemilik usaha untuk fokus mengiklankan produk SUVnya di internet pada zona hijau, yaitu untuk mereka kalangan berpenghasilan tinggi dan usia di atas rata-rata.
Untuk melanjutkan membaca silakan klik halaman berikutnya di bawah ini.
Assalamu’alaikum pak,
Saya coba dengan dataset yang sama di google colab hasil confusion matric nya tidak sama pak. Mohon pencerahannya.
ini link google colabnya : https://colab.research.google.com/drive/1ww_sdcn1svFPzB8w6a8u76iYc4zvfwOq
maaf pak, sudah saya perbaiki. sudah benar. salah memasukan x_test ke model, bukan x_test_scaler
Halo pak.
Saya mau bertanya, jika feature scaling dilakukan sebelum spliting data apakah akan beda hasilnya jika spliting data dulu baru feature scaling? Terimakasih.