

Bahasa R
# Mengimpor dataset
dataset = read.csv('Iklan_sosmed.csv')
dataset = dataset[3:5]
# Mengencode variabel dependen sebagai factor (kategori)
dataset$Beli = factor(dataset$Beli, levels = c(0, 1))
# Membagi data ke training set and test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Beli, SplitRatio = 0.75)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
training_set[, 1:2] = scale(training_set[, 1:2])
test_set[, 1:2] = scale(test_set[, 1:2])
# Membuat model regresi logistik ke training set
classifier = glm(formula = Beli ~ .,
family = binomial,
data = training_set)
# Memprediksi hasil test set
prob_pred = predict(classifier, type = 'response', newdata = test_set[1:2])
y_pred = ifelse(prob_pred > 0.5, 1, 0)
# Membuat Confusion Matrix
cm = table(test_set[, 3], y_pred)
# Visualisasi model regresi logistik dari training set
library(ElemStatLearn)
set = training_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Usia', 'EstimasiGaji')
prob_set = predict(classifier, type = 'response', newdata = grid_set)
y_grid = ifelse(prob_set > 0.5, 1, 0)
plot(set[, -3],
main = 'Logistic Regression (Training set)',
xlab = 'Usia', ylab = 'Estimasi Gaji',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '19', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
# Visualisasi model regresi logistik dari test set
library(ElemStatLearn)
set = test_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Usia', 'EstimasiGaji')
prob_set = predict(classifier, type = 'response', newdata = grid_set)
y_grid = ifelse(prob_set > 0.5, 1, 0)
plot(set[, -3],
main = 'Logistic Regression (Test set)',
xlab = 'Usia', ylab = 'Estimasi Gaji',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '19', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
Penjelasan:
- Line 2 mengimpor dataset.
- Line 3 melakukan slicing.
- Line 6 mengonversi variabel dependen Beli sebagai faktor (kategori).
- Line 9 menginstall package CaTools jika belum diinstall. Jika ingin mengeksekusi line ini, cukup hilangkan tanda # nya.
- Line 10 mengimpor library CaTools.
- Line 11 menentukan random number generatornya yaitu 123 (angka ini bebas).
- Line 12 membagi ke dalam training dan test set dengan rasio 25:75.
- Line 13 dan 14 membuat variabel training dan test set,
- Line 17 dan 18 melakukan feature scaling. Yang kita lakukan feature scaling hanya kolom 1 dan 2 saja, yaitu kolom usia dan gaji
- Line 21-23 membuat model regresi logistiknya dengan menggunakan fungsi glm (generalized linear model) dengan variabel dependen adalah Beli, dan distribusinya adalah binomial karena hanya ada 2 pilihan yaitu YA/TIDAK). Tips: arahkan kursor pada glm kemudian ketik F1 pada keyboard, maka kita bisa melihat definisi dan parameter apa saja yang diperlukan di glm. Model regresi logistik ini dibuat dari training set.
- Line 26 membuat variabel prob_pred sebagai probabilitas untuk prediksi test set dengan menggunakan model regresi logistik yang sudah dibuat, yaitu classifier di line 21. Tips: arahkan kursor pada predict dan tekan F1 untuk melihat parameternya.
- Line 27 mengonversi probabilitas di line 26, di mana jika probabilitasnya di atas 0.5 (batas ini bisa diubah sesuai keinginan kita) maka akan menjadi 1, dan jika tidak akan menjadi nol.
- Line 30 membuat confusion matrix untuk melihat performa model kita apakah akurat atau tidak. Jika di ketik cm di console maka akan tampak sebagai berikut:
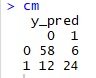
Kita memiliki 58+24 prediksi benar dan 12+6 prediksi salah, sehingga komposisinya 82 benar dan 18 salah. Akurasi model kita 82%.
- Line 33-47 adalah perintah untuk visualisasi model kita dari training set. Pastikan library di line 33 ElemStatLearn sudah terinstall di R kita. Tampilannya akan tampak sebagai berikut:

Titik-titik merah adalah keputusan untuk tidak membeli, sementara titik hijau adalah keputusan membeli. Zona merah adalah zona di bawah garis batas diagonal yang merupakan zona tidak membeli, sementara zona hijau adalah sebaliknya.
- Sekarang mari kita lihat hasil dari perintah line 50-64 untuk test set nya.

Bisa dilihat bahwa model kita bisa memprediksi test set dengan baik (akurasi 82%).
Untuk menginterpretasikan usia dan estimasi gaji yang sudah melalui feature scaling maka nilai 0 pada sumbu x dan y adalah nilai rataannya.
Kesimpulannya, model kita memprediksi bahwa semakin tinggi gaji dan semakin besar usianya, maka peluang untuk membeli semakin besar. Dengan demikian, kita rekomendasikan agar pemilik showroom SUV harus fokus mengiklankan produknya di pelanggan yang berada di zona hijau untuk memaksimalkan efektifitas iklannya di internet.
Assalamu’alaikum pak,
Saya coba dengan dataset yang sama di google colab hasil confusion matric nya tidak sama pak. Mohon pencerahannya.
ini link google colabnya : https://colab.research.google.com/drive/1ww_sdcn1svFPzB8w6a8u76iYc4zvfwOq
maaf pak, sudah saya perbaiki. sudah benar. salah memasukan x_test ke model, bukan x_test_scaler
Halo pak.
Saya mau bertanya, jika feature scaling dilakukan sebelum spliting data apakah akan beda hasilnya jika spliting data dulu baru feature scaling? Terimakasih.