
?")
Sebelumnya saya sudah membahas tentang PCA (Principal Component Analysis), di mana teknik ini mampu mereduksi dimensi yang dimiliki oleh sebuah dataset. Ada teknik lain dengan fungsi yang sama namun dengan pendekatan yang berbeda, yaitu LDA (Linear Discriminant Analysis).
LDA adalah teknik statistika klasik yang sudah dipakai sejak lama untuk mereduksi dimensi. Dengan LDA, kita juga bisa melakukan pembagian data ke dalam beberapa kelompok (clustering). Untuk bisa memahaminya dengan mudah, mari kita mulai dengan sebuah contoh.
Anggap kita memproduksi obat pusing, dengan beberapa zat aktif. Lalu kita uji cobakan obat ini ke beberapa calon pasien. Tentu saja ini hanyalah contoh yang tidak nyata, karena biasanya uji coba obat harus dilakukan ke hewan terlebih dahulu sebelum diuji coba ke manusia. Namun, anggap saja beberapa komponen ini adalah komponen yang sangat aman.
Oke, kembali ke obat pusing, hasil dari uji coba obat ini adalah sebagai berikut:

Ilustrasi di atas memberikan gambaran bahwa ada 2 hasil yang didapat, di mana warna coklat menunjukkan bahwa obat tidak efektif (pasien masih mengatakan pusing), dan warna biru menunjukkan obatnya efektif (pasien merasakan pusingnya hilang). Sumbu x merepresentasikan kadar kandungan zat X pada obat tersebut, di mana semakin ke kanan maka kandungannya semakin banyak, dan semakin ke kiri adalah sebaliknya.
Kita bisa melihat bahwa seperti ada dua kelompok di sini (zona biru dan zona coklat), dan ada batas yang samar sebagai pemisah antara dua zona ini, karena warna biru dan coklat ada yang bercampur di bagian tengah.
Melalui grafik di atas, kita bisa mengatakan bahwa semakin sedikit kandungan zat X, maka semakin efektif untuk menghilangkan rasa pusing, dan semakin banyak maka semakin tidak efektif. Tentu saja ada batas kandungan minimal yang masih bisa membuatnya efektif, namun kita tidak perlu membahas sedetail itu untuk ilustrasi kali ini.
Sekarang kita coba kombinasikan 2 bahan dalam obat tersebut. Jika sebelumnya kita buat grafik untuk bahan X, sekarang kita gabungkan dengan bahan Y. Ilustrasinya adalah sebagai berikut.
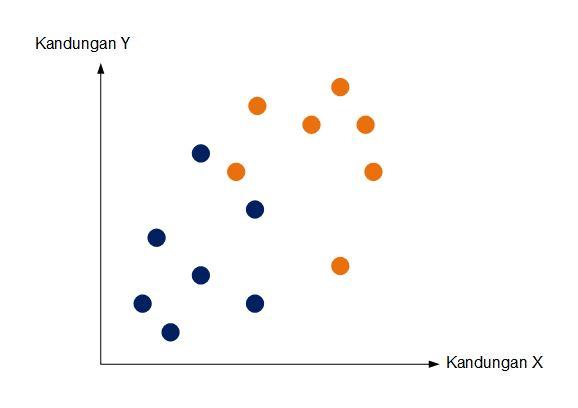
Kita memiliki 2 bahan sebagai pertimbangan sekarang yaitu bahan X (dipetakan melalui sumbu x) dan bahan Y (dipetakan melalui sumbu y). Kita bisa melihat dengan cukup jelas pembagian 2 wilayah (titik-titik biru dengan hasil efektif, dan titik-titik coklat) dengan hasil tidak efektif).
Kalau kita buat sebuah garis pembatas linear yang memisahkan keduanya, kira-kira seperti ini hasilnya:

Walau kita sudah membuat garis, namun masih ada satu titik coklat yang masuk di zona biru. Artinya garis pembatas kita belum sempurna. Lalu bagaimana jika kita pertimbangkan bahan ketiga (kandungan Z)? Apakah akan jauh lebih baik dalam memisahkan dua zona (efektif dan tidak)?
Ilustrasinya grafik dengan 3 bahan aktif (X, Y, dan Z) adalah sebagai berikut
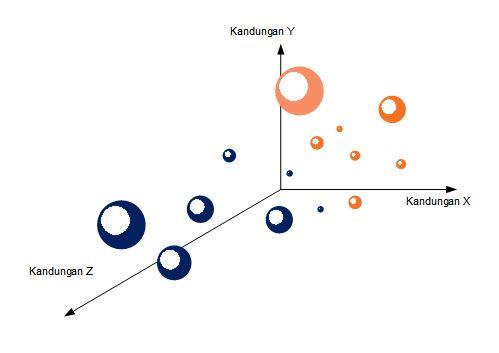
Kita sekarang memiliki 3 bahan aktif, dengan bulatan besar menunjukkan ia semakin dekat ke layar (sumbu z), dan bulatan kecil menunjukkan ia semakin jauh. Namun dengan 3 dimensi seperti ini, justru membuat kita semakin sulit untuk membaginya, karena membuat mata kita bingung. Jadi sepertinya dengan membuat dari 2 dimensi (mempertimbangkan 2 bahan aktif) menjadi 3 dimensi (mempertimbangkan 3 bahan aktif) justru membuat visualisasinya semakin buruk.
Jika 3 dimensi saja sudah susah, bagaimana jika kita mau mempertimbangkan bahan aktif keempat, kelima, keenam dan seterusnya? Artinya kita memiliki banyak sekali dimensi (n dimensi). Pasti mustahil membuat visualisasinya.
Kita sedang membicarakan masalah yang sama persis ketika kita membahas PCA, yaitu sulitnya membuat visualisasi lebih dari 3 dimensi. Solusi yang paling optimum (memudahkan mata kita untuk menginterpretasikan insights-nya) adalah dengan membuat visualisasi 2 dimensi (2D). Walau demikian, sumbu yang kita miliki di visualisasi 2D ini bukan sumbu asli, melainkan hasil transformasi dari datasetnya itu sendiri.
Jika di PCA kita membuat beberapa PCs (principle components) di mana PCs yang terpilih adalah yang bisa merepresentasikan variasi (variance) terbesar, dan PCs inilah yang akan menjadi sumbu baru untuk visualisasinya. maka LDA sedikit berbeda.
Di LDA kita tidak tertarik sama sekali dengan variasi (variance), namun kita sangat tertarik bagaimana caranya agar bisa memaksimalkan jarak antara 2 zona (kelompok) yang berbeda atau lebih. Jadi di LDA, kita mengusahakan agar sebisa mungkin sumbu yang baru nantinya adalah hasil dari representasi pemisahan (separability) beberapa zona yang ada di dataset.
LDA sangat mirip dengan PCA, namun kita fokus ke memaksimalkan keterpisahan (separability) antara beberapa kelompok.
Tenang saja, jika pembaca masih bingung, kita akan mulai lagi dengan sebuah contoh, agar konsep LDA bisa dipahami dengan baik.
Anggap kita ingin mereduksi dimensi dengan cara merubah grafik 2D di atas menjadi sebuah grafik 1D. Caranya adalah dengan memproyeksikan semua titik ke sumbu X (dengan melupakan sumbu Y). Ilustrasinya sebagai berikut:
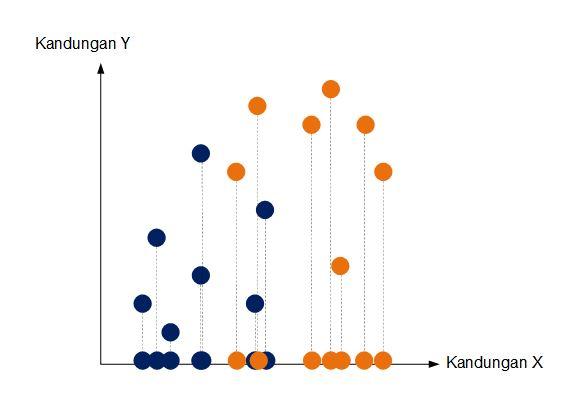
Sekarang kita memiliki grafik hasil pemetaan dataset ke sumbu x. Dengan demikian kita hanya memiliki 1 dimensi saja. Perlu diperhatikan bahwa grafik ini sama persis seperti grafik sebelumnya ilustrasi pertama dengan hanya 1 dimensi sumbu x).
Tentunya dengan memetakan semuanya ke sumbu x (dan melupakan sumbu y), maka kita kehilangan banyak informasi. Kita kehilangan informasi hubungan pengaruh efektivitas bahan aktif Y terhadap obat yang kita buat. Namun, jika sebaliknya kita petakan ke sumbu y (dengan melupakan sumbu x) maka itu juga tidak membuatnya semakin baik.
Lalu bagaimana solusinya? Mulailah kita masuk ke LDA.
Cara yang tepat untuk mereduksi dimensi dari 2 dimensi ke 1 dimensi adalah dengan LDA. Dengan LDA ia akan membuat sebuah sumbu baru di mana sumbu ini akan memaksimalkan pemisahan 2 kategori (kita sedang berbicara reduksi 2D ke 1D).
Ilustrasi sumbu LDA adalah sebagai berikut:

Sekarang kita memiliki sumbu baru hasil LDA, di mana sumbu ini dengan sangat baik bisa membagi dataset ke 2 kelompok (biru dan coklat). Lalu bagaimana caranya sumbu ini dibuat? Caranya adalah dengan sedikit perhitungan statistik dasar.
Sumbu itu dibuat dengan mencari rasio antara perubahan rataan dan perubahan variasi (variance). Perubahan rataan yang dimaksud disebut dengan distance (d), dengan cara mengurangkan nilai rataan kelompok 1 dengan kelompok 2. Kemudian perubahaan variance adalah dengan menjumlahkan kedua variance.
Ilustrasi mudahnya sebagai berikut:

Formula di atas menunjukkan bahwa sebisa mungkin sumbu yang baru menghasilkan jarak rataan (distance) antara keduanya sebesar mungkin (artinya semakin jauh), dan jumlah variance nya semakin kecil (artinya masing-masing zona persebarannya kecil/memusat). Dengan demikian, akan tejadi pemisahan yang akurat antar kedua kategori.
LDA untuk 3 dimensi dan 2 kategori
Lalu bagaimana jika kita memiliki 3 dimensi (bahan aktif X, Y, dan Z) seperti kasus di atas? Prosesnya sama saja, yaitu dengan membuat sebuah sumbu LDA baru yang tetap memaksimalkan rasio jarak dengan variance. Ilustrasinya sebagai berikut.
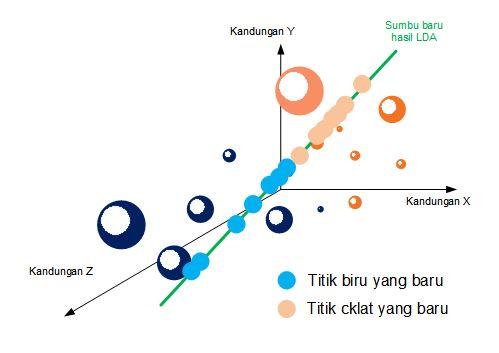
Kita belum memerlukan 2 sumbu LDA untuk kasus dengan 3 bahan aktif. Mengapa? Karena nilai rataan yang kita cari tetaplah hanya 2, begitu pula dengan variance-nya, sehingga formulanya tetap sama.
Namun kasusnya akan menjadi berbeda jika kita memiliki 3 kategori (efektif, netral, dan tidak efektif), barulah kita memerlukan 2 sumbu LDA.
LDA untuk 3 kategori
Anggap sekarang kita memiliki 3 kategori seperti di atas, dan kita petakan terhadap 2 bahan aktif (X dan Y), maka ilustrasinya sebagai berikut.

Sekarang kita memiliki 3 kategori (2 kategori lama dan 1 kategori baru netral berwarna hijau). Sekarang cara perhitungannya sedikit berbeda, namun tidak berbeda jauh.
Langkah pertama untuk menghitung rataan masing-masing kategori adalah dengan mencari titik pusat utama untuk ketiga kategori tersebut. Kemudian untuk setiap kategori carilah titik pusatnya, sehingga jarak rataan adalah jarak titik pusat masing-masing kategori terhadap titik pusat utama tadi. Ilustrasinya sebagai berikut.

Sekarang kita memiliki 2 sumbu baru (disebut dengan LD1 dan LD2), di mana sumbu ini merupakan hasil perhitungan LDA untuk 3 kategori dan 2 sumbu awal (bahan aktif X dan Y).
Mengapa bisa ada 2 sumbu baru? Karena kita memiliki 3 titik pusat (3 kategori). Dua titik pusat menghasilkan garis (1 dimensi), dan 3 titik pusat menghasilkan bidang (2 dimensi).
Lalu bagaimana jika kita memiliki ratusan variabel dan ratusan kategori? Tentunya kita memerlukan perhitungan menggunakan komputer dan tetap dengan tujuan untuk mereduksi dimensinya menjadi 2 dimensi.
Sebagai ringkasan, PCA dan LDA adalah metode yang memiliki tujuan yang sama yaitu mereduksi dimensi (dimensionality reduction). Perbedaan output keduanya nya adalah:
- PCA menghasilkan beberapa PCs (principal components), di mana PC1 akan menjelaskan variance terbesar dataset, PC2 menjelaskan variance terbesar setelah PC1, PC3 menjelaskan variance terbesar setelah PC2 dan seterusnya. Masing-masing PC akan membentuk sumbu baru pada visualisasi data.
- LDA menghasilkan beberapa LDs (linear discriminants). LD1 menjelaskan pemisahan (separability) terbesar antar kelompok. LD2 menjelaskan separability terbesar antar kelompok setelah LD1, dan seterusnya. Masing-masing LD akan membentuk sumbu baru pada visualisasi data.
Sampai di sini saya harap pembaca bisa memahami konsep dasar tentang LDA dan tahu perbedaanya jika dibandingkan dengan PCA. Di artikel selanjutnya kita akan mengaplikasikan LDA untuk kasus nyata di dunia industri.
Tetap semangat belajar AI dan machine learning.
Semoga bermanfaat.
Kapan kita menggunakan PCA atau LDA ya?
Gunakan PCA untuk unsupervised (digunakan untuk ‘merubuhkan’ ruang multidimensi dari banyak menjadi sedikit), gunakan LDA untuk supervised learning khususnya di permasalahan klasifikasi (digunakan untuk mengukir ruang multidimensi).
Permisi untuk implementasi LDA-nya dimana ya artikelnya?. Mohon informasinya 🙏, dan apakah bisa melakukan reduksi data unsupervised learning dengan tujuan utama untuk clustering menggunakan DBSCAN dan reduksi datanya menggunakan LDA?
implkementasi LDA ada di link satunya lagi