

1. CONVOLUTION
Sesuai namanya, CNN (Convolutional Neural Networks) terinspirasi oleh langkah pertamanya, yaitu convolution. Lalu apa yang dimaksud dengan convolution?
Untuk bisa memahaminya dengan mudah, mari kita lihat ilustrasi berikut:

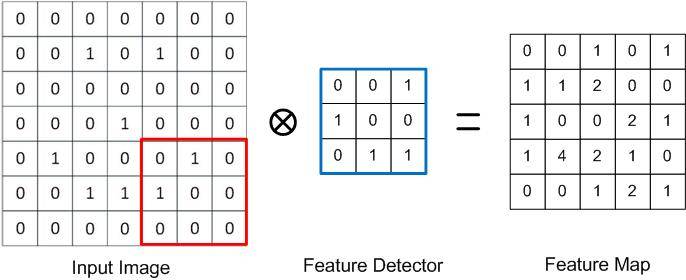
Gambar sebelah kiri adalah gambar wajah senyum yang sudah kita siapkan sebelumnya, di mana gambar ini sudah dikonversi ke dalam unit pixel dengan ukuran 7×7. Nilai pixel untuk gambar ini adalah 0 dan 1 saja untuk memudahkan pemahaman karena hanya merepresentasikan gambar senyum dengan warna hitam dan putih saja (dalam realitas nilai pixel antara 0-255).
Kemudian di bagian tengah ada yang disebut dengan feature detector yang merupakan sebuah matriks yang bisa mengonversi dari gambar awal menjadi feature map. Feature detector ini adalah matriks persegi (sama jumlah baris dan kolomnya) yang pada contoh adalah berukuran 3×3. Ukuran feature detector tidaklah harus 3×3, bisa 5×5 dan bahkan 7×7 dalam literatur lain. Namun secara umum adalah 3×3 dan yang kita pakai di pembelajaran ini adalah 3×3.
Dalam literatur lain feature detector sering disebut dengan istilah kernel atau filter. Sehingga saya harap pembaca tidak bingung jika membaca referensi lain, feature detector disebut dengan nama yang lain.
Kemudian yang terjadi dalam tahap convolution adalah mengalikan pixel pada gambar (ditandai dengan warna merah) dengan feature detector. Hasil dari perkalian tiap pixelnya kemudian dijumlahkan. Ilustrasinya sebagai berikut:
(0x0) + (0x0) + (0x1) + (0x1) + (0x0) + (1×0) + (0x0) + (0x1) + (0x1) = 0+0+0+0+0+0+0+0+0 = 0
Kemudian sekarang kita geser sedikit ke kanan. Ilustrasinya sebagai berikut:

Perkaliannya sebagai berikut:
(0x0) + (0x0) + (0x1) + (0x1) + (1×0) + (0x0) + (0x0) + (0x1) + (0x1) = 0+0+0+0+0+0+0+0+0 = 0
Begitu seterusnya sampai selesai untuk semua pixel yang ada.
Kita bisa melihat bahwa gambar awal yang berukuran 7×7 berkurang menjadi lebih kecil yaitu 5×5. Ini memang salah satu tujuan utama feature detector. Bisa dibayangkan jika mengolah gambar yang berukuran besar dengan resolusi tinggi, maka bisa sampai ribuan pixel. Melalui feature detector proses pengolahan gambar menjadi semakin cepat karena data pixel yang diolah juga semakin kecil (sedikit).
Pertanyaan yang muncul selanjutnya adalah apakah setelah mengecilkan gambar awal, adakah informasi dari gambar yang hilang? Ya tentu saja kita kehilangan sedikit informasi karena memang ukurannya berubah dari besar ke kecil. Namun, tujuan utama dari feature detector adalah mencari (mendeteksi) informasi (fitur) tertentu yang bersifat integral.
Ilustrasi mudahnya adalah sebagai berikut. Jika kita memiliki feature detector seperti di atas (dengan angka 0 dan 1 di pixelnya), maka nilai-nilai di feature map menunjukkan seberapa banyak features (fitur-fitur) yang mirip dengan feature detector. Semakin tinggi nilai pixel di feature map, maka semakin banyak kesamaan terhadap feature detector yang direpresentasikan oleh pixel tersebut. Jadi bisa dipahami ya sampai sini bahwa feature map merepresentasikan gambar awal dalam versi yang lebih kecil, yang sudah disaring oleh feature detector.
Agar pembaca tidak bingung, dalam literatur lain nama feature map juga disebut dengan istilah convolved feature, atau activation map.
Sebenarnya apa itu features? Apa yang dimaksud dengan fitur dalam konteks gambar?
Yang dicari dalam tahapan CNN adalah fitur, dan kita tidak tertarik nilai pixel demi pixel, tetapi yang menarik adalah fitur dalam pixel itu.
Anggap saja kita ingin mencari hidung pada foto wajah seseorang. Maka dalam hal ini, fitur yang dimaksud adalah hidung (feature detector = hidung). Kemudian, melalui feature detector ini, ia akan mencari mana dari semua pixel yang ada di gambar wajah tadi yang menunjukkan bahwa fiturnya mirip dengan kriteria hidung yang ada di feature detector. Nilai kemiripan itu selanjutnya diterjemahkan ke dalam feature map. Dengan demikian, tingginya nilai pixel di feature map, menunjukkan tingkatan kemiripan pixel di gambar yang memiliki fitur hidung. Semakin tinggi maka pixel itu dapat diduga sebagai hidung yang kita cari. Sampai sini saya harap bisa dipahami.
Dalam proses CNN, ada banyak feature detector. Dengan demikian, maka ada banyak feature map. Kumpulan dari feature map disebut dengan convolutional layer. Ilustrasinya sebagai berikut:

Setelah kita memiliki beberapa feature maps, langkah selanjutnya adalah menggunakan rectifier linear units (ReLU) activation function untuk mengurangi lineartitas dari feature map yanga da di convolutional layer. Pertanyaan selanjutnya adalah, mengapa harus dikurangi linearitasnya?
Gambar pada dasarnya memiliki kecenderungan non-linear. Non-liniear artinya tidak berhubungan. Misal ada foto wajah seseorang yang berpose di depan rumahnya. Tentunya tidak ada hubungan (linearitas) antara wajah orang dengan background rumahnya. Begitu pula tidak ada hubungan antara rambut dengan rumput halaman yang berwarna hijau misalnya. Banyak elemen dalam sebuah gambar yang tidak linear satu dengan lainnya.
Walau demikian, bisa jadi terjadi lineraritas karena proses feature detection itu sendiri, di mana tahapan ini memang mencari kesamaan feature di setiap pixelnya. Semakin banyak kesamaan, maka semakin besar potensi hubungan linear yang terjadi antar pixelnya. Dalam konteks matematis, linearitas artinya naiknya variabel independen, diiringi juga oleh naiknya variabel dependen.
Tujuan dari ReLU adalah memutuskan ikatan linearitas yang terjadi dari proses feature detection.

Rectifier function bernilai dari 0 sampai dengan 1. Dengan demikian ia tidak bisa mengolah data yang bernilai negatif. Jika ada nilai negatif, maka akan ia filter.
Untuk memudahkan pemahaman tentang tujuan ReLU mari kita lihat ilustrasi berikut. Ada sebuah gambar pemandangan gedung bertingkat berwarna hitam putih. Tampilannya adalah seperti ini:

Setelah melalui proses feature detection, maka tampilannya berubah menjadi seperti ini:

Bisa kita lihat warna hitam bernilai negatif dan warna putih bernilai positif. Mengapa bisa bernilai negatif? Karena beberapa pixel dalam feature detector (filter) yang digunakan bernilai negatif. Contohnya misal seperti ini:
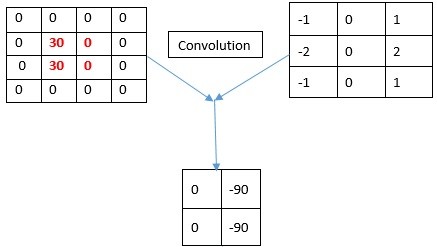
Dengan menggunakan ReLU, maka akan menghilangkan nilai negatif di pixelnya (semua nilai negatif akan dikonversi menjadi nol). Dengan demikian ia menghilangkan warna hitam. Tampilannya menjadi seperti ini:

Dengan menggunakan ReLU, maka algoritma CNN lebih mudah mencapai nilai optimum (converge). Dari sisi konteks matematis, maka hal ini masuk akal. Jika kita memiliki fungsi linear (garis lurus dari kiri bawah ke kanan atas) maka sulit mencari nilai optimumnya (tidak ada ujungnya). Namun dengan ReLu (dengan tujuan utamanya adalah mengurangi linearitas), maka lebih mudah mencari nilai optimumnya (baik minimum atau maksimum). Jika bingung, silakan baca kembali konsep gradient descent di link ini.
Untuk melanjutkan membaca, silakan klik tombol ke halaman selanjutnya di bawah ini.
Assalamu’alaikum pak saya ingin bertanya, pada pembahasan di halaman ini kan feature detector / filter berukuran 3 x 3 dan nilainya 0,1,0,1 karena hanya sebagai contoh agar lebih mempermudah, bagaimana pak cara menentukan ataupun mengetahui nilai2 piksel dari suatu feature detektor (misal 3×3 atau 5×5) jika gambar kita grayscale maupun RGB?
[…] International, Deep Learning: Convolutional Neural Networks (https://www.megabagus.id/deep-learning-convolutional-neural-networks) diakses pada 21 September […]