

4. FULL CONNECTION
Di tahapan ini kita memasukkan hasil flattening ke dalam struktur ANN (artificial neural networks) yang utuh.
Hal yang perlu diperhatikan adalah dalam pembahasan ANN sebelumnya setiap neuron (nodes) tidaklah harus saling terhubung dengan nodes di depannya. Dalam konteks CNN, maka semua nodes harus terhubung dengan nodes di depan dan belakangnya. Oleh karena itu disebut dengan full connection.

Pada ilustrasi di atas kita bisa lihat bahwa hasil dari flattening menjadi input dari ANN. Seperti biasa, ANN terdiri dari 3 bagian, yaitu input layer, hidden layer, dan output layer. Dalam konteks CNN, maka semua nodes saling terhubung dengan nodes di depan dan belakang.
Kemudian di bagian output layer ada terdiri dari beberapa class (kategori). Di gambar atas, kita memiliki 2 class, misalnya apakah gambar masuk ke dalam kategori anjing atau kucing. Jika lebih dari 2 kategori, misal 5 kategori, maka nodes di output layer ada 5 buah.
Hasil dari 2 kategori pada gambar di atas (apakah gambarnya adalah anjing atau kucing) berupa probabiitas. Ia akan mengeluarkan nilai probabilitas untuk masing-masing kategori. Jika ia menebak bahwa gambarnya adalah gambar kucing, bisa jadi nilai probabilitas akhirnya adalah anjing=0.2, kucing 0.87.
Cara kerja ANN di CNN juga sama. Ia akan maju (forward propagation) dan mundur (back propagation). Yang paling berperan dalam penentuan apakah input gambar masuk ke kategori A, B, dan seterusnya adalah bobot yang dimiliki setiap node. Bobot ini akan selalu disesuaikan setiap epochnya.
Jika pembaca bingung tentang ANN, ada baiknya mereview kembali materinya di link ini.

Ilustrasi di atas menggambarkan arsitektur ANN untuk memilih apakah gambar tertentu termasuk ke dalam golongan gambar anjing atau kucing. Anggap sekarang arsitektur ANN ini sudah melalui beberapa epoch, masing-masing nodes di hidden layer kedua memiliki nilai dan bobot.
Ilustrasinya sebagai berikut:
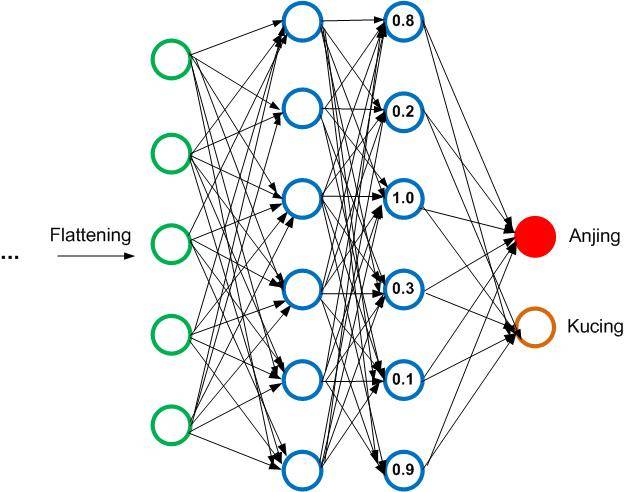
Sekarang kita lihat bahwa nodes di hidden layer kedua memiliki nilai. Nilai ini adalah nilai saat perhitungan output layer kategori anjing (nilai untuk kategori kucing akan berbeda lagi).
Anggap kita urutkan node paling atas sesuai angka, maka kita bisa lihat node 1, 3, dan 6 memiliki nilai paling tinggi dengan angka masing-masing 0.8, 1.0, dan 0.9 (angkanya hanya permisalan saja antara 0-1; nilai 1 artinya node ini mendapatkan fitur yang jelas, sementara nilai 0 artinya tidak ada fitur jelas yang tertangkap).
Masing-masing dari node ini mewakili sebuah fitur tertentu. Misal node no 1 adalah fitur telinga, no 3 adalah fitur bentuk wajah, dan fitur ke 6 adalah mata. Setiap kita suguhkan gambar 100% anjing (saat proses training), maka nilai ketiga nodes ini (node 1, 3, dan 6) adalah 0.8, 1.0, dan 0.9. Dengan demikian, lama kelamaan output node anjing akan memiliki asosiasi yang kuat terhadap ketiga neuron ini, dan mulai melupakan (ignoring) neuron yang lainnya (sekali lagi perlu diingat bahwa nilai node ini adalah untuk gambar 100% anjing saja, untuk 100% kucing berbeda lagi).
Ilustrasinya menjadi seperti ini:
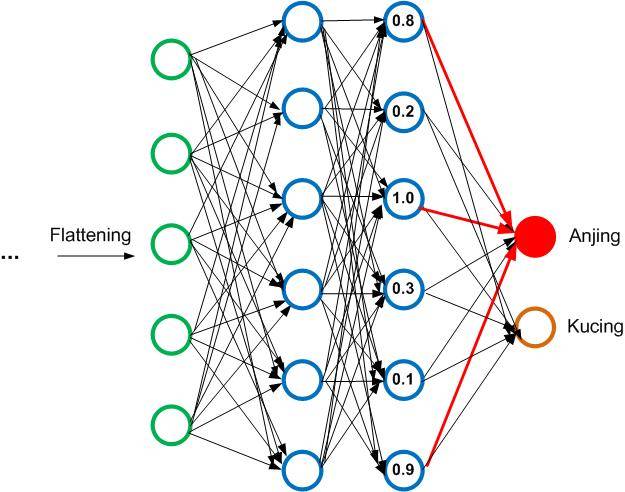
Walaupun nilai neuron tertentu sangat kuat untuk anjing, penentu nilai probabilitas anjing juga ditentukan oleh bobot antara neuron tersebut dengan bobot yang dimilikinya, di mana bobot ini adaah hasil penyempurnaan dari beberapa kali epoch.
Sekarang kita beralih untuk gambar 100% kucing. Ternyata hidden layer kedua juga memiliki nilai berbeda ketika disuguhkan gambar yang benar-benar kucing. Ilustrasinya sebagai berikut:
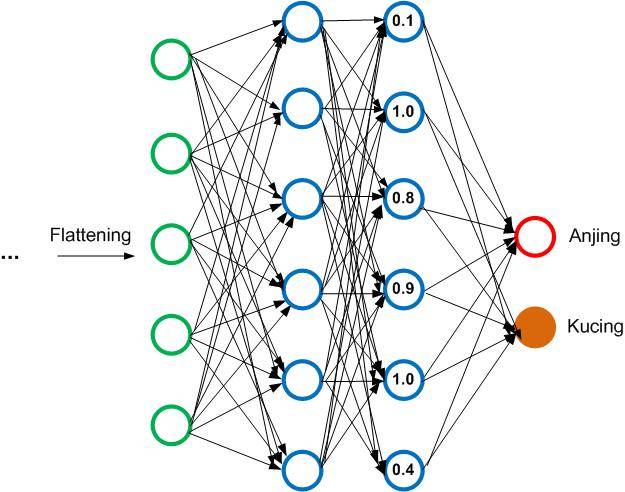
Kita bisa lihat bahwa neuron no 2, 3, 4, dan 5 berhasil menangkap fitur yang cukup baik untuk gambar kucing. Seakan-akan neuron ini memberikan sinyal kepada output neuron di depannya, ‘aku berhasil menangkap fitur dasar yang ada pada gambar kucing.’. Dengan demikian, untuk training dengan gambar 100% kucing ilustrasinya menjadi seperti ini:

Jadi setiap keputusan baik itu kucing maupun anjing, masing-masing neuron ini memiliki neuron prioritas di belakangnya (di hidden layer sebelah kirinya). Tentunya prioritas ini diperkuat lagi oleh bobot yang dimiliki neuron tersebut. Bobot yang tinggi menyatakan bahwa neuron tersebut memang penting, begitu pula sebaliknya.
Hasil dari sebuah deteksi gambar melalui proses CNN kurang lebih akan tampak sebagai berikut:
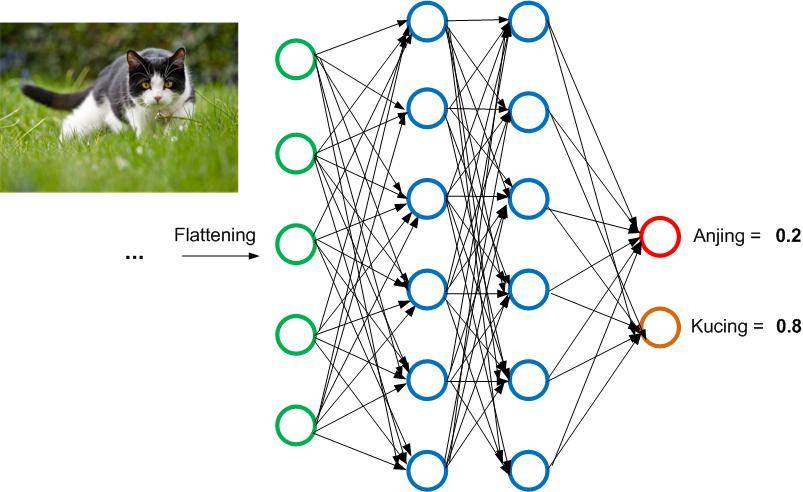
Sekarang kita memiliki nilai probabilitas yang menyatakan apakah gambar input tersebut termasuk ke dalam kategori anjing atau kucing. Dalam ilustrasi di atas bisa dilihat bahwa hasil akhirnya menunjukkan peluang terbesar gambar tersebut adalah gambar kucing sebesar 0.8, sedangkan peluang untuk masuk ke kategori anjing adalah 0.2. Dengan demikian, mesin besar kemungkinan bahwa gambar tersebut adalah gambar kucing.
Sebagai tambahan informasi, penentu nilai di mana total probabilitasnya adalah 1 (0.2 + 0.8) menggunakan algoritma yang disebut dengan softmax. Sementara, proses evaluasi CNNnya tidak menggunakan cost function, melainkan loss function (istilah lain untuk cost function di domain ANN). Loss function yang digunakan di output layer adalah cross-entropy. Kita tidak akan bahas keduanya secara detail, karena sangat matematis.
Demikian pembahasan tentang convolutional neural networks (CNN). Saya harap pembaca bisa memahami alurnya. Yang jelas saya mengharapkan pembaca memahami proses dan cara kerjanya. Tentunya pemahaman tentang CNN akan jauh lebih baik saat berlatih dan praktek saat programming.
Di kesempatan selanjutnya saya akan berbagi teknis tentang bagaimana melakukan CNN dan memprediksi gambar. Jadi terus ikuti dan belajar tentang AI bersama saya.
Semoga bermanfaat, terima kasih.
Assalamu’alaikum pak saya ingin bertanya, pada pembahasan di halaman ini kan feature detector / filter berukuran 3 x 3 dan nilainya 0,1,0,1 karena hanya sebagai contoh agar lebih mempermudah, bagaimana pak cara menentukan ataupun mengetahui nilai2 piksel dari suatu feature detektor (misal 3×3 atau 5×5) jika gambar kita grayscale maupun RGB?
[…] International, Deep Learning: Convolutional Neural Networks (https://www.megabagus.id/deep-learning-convolutional-neural-networks) diakses pada 21 September […]