

STUDI KASUS
Kali ini kita akan mengaplikasikan metode K-Means ini untuk sebuah permasalahan nyata. Anggap kita adalah seorang data scientist profesional yang diminta oleh klien untuk menganalisis data pelanggan yang berkunjung ke mall mereka. Mereka data pelanggan setia, namun mereka bingung cara mengelompokkan data ini, sehingga nantinya pengelompokan ini bisa mereka gunakan untuk semakin memperkuat hubungan mereka terhadap konsumen. Misal untuk penguatan marketing, strategi penawaran yang tepat, barang-barang apa saja yang cocok bagi mereka, dll.
Untuk bisa memulai, silakan download datasetnya di link ini.
Data yang kita miliki adalah :
- ID pelanggan
- Jenis kelamin
- Usia
- Penghasilan tahunan
- Kategori pengeluaran saat belanja (1=kecil, 100=sangat besar)
Berikut adalah solusi K-Means dengan bahasa Python dan R.
Bahasa Python
# Mengimpor library
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Mengimpor dataset
dataset = pd.read_csv('Pengunjung_mall.csv')
X = dataset.iloc[:, [3, 4]].values
# Menggunakan metode elbow untuk menentukan angka cluster yang tepat
from sklearn.cluster import KMeans
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('Metode Elbow')
plt.xlabel('Jumlah clusters')
plt.ylabel('WCSS')
plt.show()
# Menjalankan K-Means Clustering ke dataset
kmeans = KMeans(n_clusters = 5, init = 'k-means++', random_state = 42)
y_kmeans = kmeans.fit_predict(X)
# Visualisasi hasil clusters
plt.scatter(X[y_kmeans == 0, 0], X[y_kmeans == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X[y_kmeans == 1, 0], X[y_kmeans == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X[y_kmeans == 2, 0], X[y_kmeans == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X[y_kmeans == 3, 0], X[y_kmeans == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X[y_kmeans == 4, 0], X[y_kmeans == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Centroids')
plt.title('Clusters pelanggan')
plt.xlabel('Pendapatan tahunan (juta Rupiah)')
plt.ylabel('Rating pengeluaran (1-100)')
plt.legend()
plt.show()
Penjelasan:
- Line 2 sampai 4 mengimpor library yang dibutuhkan
- Line 7, mengimpor dataset
Jika benar, maka datasetnya akan tampak sebagai berikut:

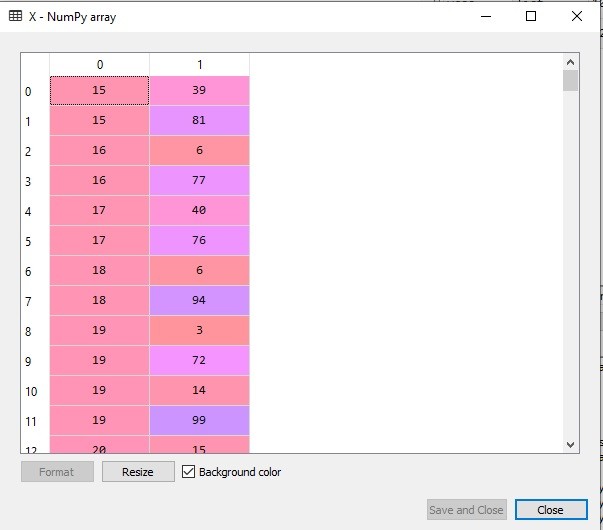
- Line 8, melakukan slicing, dari dataset yang dimiliki. Kita hanya memerlukan kolom ke 3 (pendapatan) dan 4 (rating pengeluaran) saja
Jika slicing nya benar, maka akan tampak sebagai berikut:
- Line 11, mengimpor library K-Means.
- Line 12, membuat list WCSS (mempersiapkan perhitungan WCSS).
- Line 13 adalah perintah looping, perlu diingat bahwa kita ingin melakukan looping 10 kali. Oleh karena itu di python ditulis range(1,11), karena angka 11 tidak diikutkan oleh python. Sehingga jika ingin iterasi sebanyak 21 kali misalnya, maka penulisannya range (1,22).
- Line 14 adalah menuliskan objek kmeans untuk melakukan algoritma K-Means. Selanjutnya perintah pertama adalah KMeans (kapital K dan M), yang merupakan class dari library K-Means yang diimpor di line 11, dengan beberapa parameter n_clusters yang merupakan jumlah kluster, diikuti dengan parameter kedua init yang merupakan pemilihan jumlah K di awal (kali ini kita gunakan K++, agar tidak terkena jebakan centroid. Kemudian parameter yang terakhir adalah random_state = 42. Random state ini seperti seed pada R, yang jika dipilih 42, maka ketika kita memilih 42 di kesempatan yang berbeda, maka bilangan random yang dihasilkan akan sama. Tips: Arahkan kurson pada KMeans, lalu ketik CTRL+i pada keyboard untuk menampilkan parameter apa saja yang diperlukan.
- Line 15 merupakan perintah agar objek kmeans di line 14, digunakan untuk mengolah data X yang sudah kita definisikan di line 8.
- Line 16 merupakan perintah untuk menghitung WCSS dengan menuliskan perintah append setelah wcss. Append merupakan method di python untuk menambahkan objek. Algoritma wcss dituliskan dengan perintah kmeans.inertia_ (dengan underscore).
- Line 17 merupakan perintah untuk menampilkan plot. Sumbu x pada plot adalah jumlah kluster dari 1-10, maka ditulis range(1,11). Sumbu y nya adalah skor wcss yang dihitung di line 16.
- Line 18-20 adalah perintah plot untuk estetika, seperti nama sumbu x, sumbu y dll.
- Line 21 adalah perintah menampilkan plotnya.
Jika benar, maka tampilan plotnya akan tampak sebagai berikut:

Melalui gambar di atas, dapat dilihat bahwa bentuk elbow (siku) terlihat saat jumlah kluster adalah 5. Oleh karena itu, kita tentukan bahwa jumlah K yang baik adalah 5.
Note: Jika pembaca berpendapat bahwa bentuk siku juga terlihat pada K=3, maka itu juga benar. Dalam kondisi seperti ini, di mana K=3 dan K=5 menunjukkan bentuk siku, kita pilih yang nilai K nya lebih besar, dalam hal ini K=5.
- Sekarang saatnya kita memilih jumlah kluster=5. Line 24 adalah perintah melakukan K-Means clustering terhadap objek kmeans. Perintahnya mirip dengan line 14, namun kali ini parameter n_clusters diisi dengan 5.
- Line 25 adalah melakukan prediksi seperti apa pengelompokan klusternya jika kita pilih K=5. Kita siapkan objek y_kmeans (tentu saja pemilihan nama ini bebas) dengan method bukan fit melainkan fit_predict terhadap variabel X yang sudah didefinisikan di line 8.
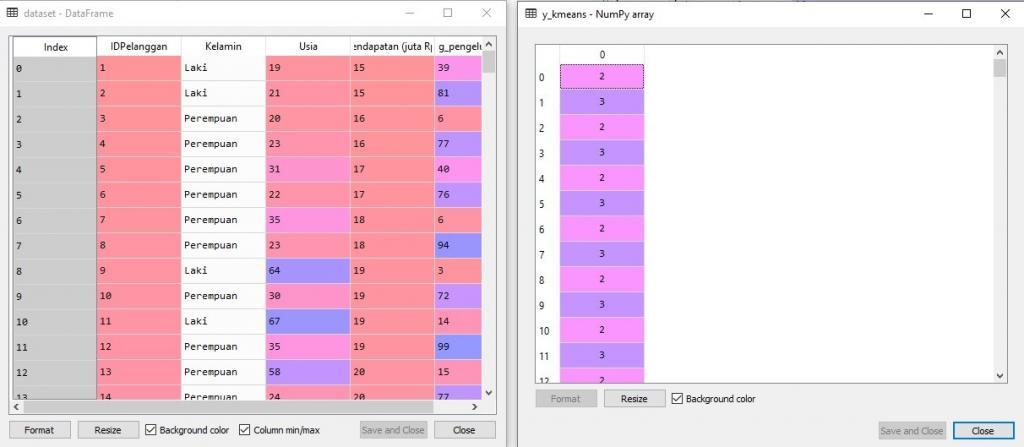
Jika kita bandingkan antara variable dataset dengan y_predict, maka kita bisa lihat bahwa id pelanggan 1 masuk ke kluster no 2, id pelanggan 13 masuk ke kluster no 13, dst. Sebagai catatan, kluster yang ada memiliki nomor urut 0 sampai 4, karena dalam python urutan dimulai dari nol.
- Line 28-38 menampilkan hasil clusteringnya.
- Line 28 adalah perintah untuk menampilkan semua data poin yang masuk ke cluster 1. Berikut penjelasan detailnya:
Kita ingin menampilkan scatter plot, sehingga perintahnya adalah plt.scatter. Parameter untuk plt.scatter adalah sumbu x, kemudian diikuti sumbu y nya. Sumbu x adalah pendapatan tahunan, dan sumbu y adalah rating pengeluaran. Sumbu x dan y nya dari objek X yang didefinisikan di line 8.
Kemudian untuk sumbu x nya ditulis X[y_kmeans == 0, 0] artinya data poin nya berasal dari objek X. Penulisan y_kmeans == 0 adalah untuk mewakili baris X yang dipilih, yaitu baris yang clusternya masuk ke cluster 1 (urutan dimulai dari nol).
Untuk kolomnya mudah saja, karena ia adalah data penghasilan tahunan, maka kolom 1 objek X yang kita pilih, sehingga penulisannya setelah y_kmeans == 0 adalah koma, kemudian diikuti nol.
Untuk sumbu y nya, ditulis X[y_kmeans == 0, 1] di mana bisa langsung dilihat bahwa kolom untuk rating pengeluaran rutin adalah kolom ke 2, ditulis 1 di python.
Begitu seterusnya sampai kluster kelima.
- Line 38 adalah perintah untuk menampilkan plotnya.
Jika benar, maka tampilan klusternya tampak sebagai berikut:

Melalui gambar di atas bisa dilihat pembagian data points ke dalam kluster yang sangat rapi, di mana terlihat semua data points masuk ke dalam kluster masing-masing. Selain itu pembagian kliusternya juga baik, tampak jarak yang tidak saling berdekatan.
Bahasa R
# Mengimpor dataset
dataset = read.csv('Pengunjung_mall.csv')
dataset = dataset[4:5]
# Menggunakan metode elbow untuk menemukan angka cluster yang optimal
set.seed(6)
wcss = vector()
for (i in 1:10){
wcss[i] = sum(kmeans(dataset, i)$withinss)
}
plot(1:10,
wcss,
type = 'b',
main = paste('The Elbow Method'),
xlab = 'Number of clusters',
ylab = 'WCSS')
# Menjalankan K-Means Clustering
set.seed(29)
kmeans = kmeans(x = dataset, centers = 5)
y_kmeans = kmeans$cluster
# Visualisasi hasil clusters
library(cluster)
clusplot(dataset,
y_kmeans,
lines = 0,
shade = TRUE,
color = TRUE,
labels = 2,
plotchar = FALSE,
span = TRUE,
main = 'Klusters pelanggan',
xlab = 'Pendapatan tahunan',
ylab = 'Rating pengeluaran')
Penjelasan:
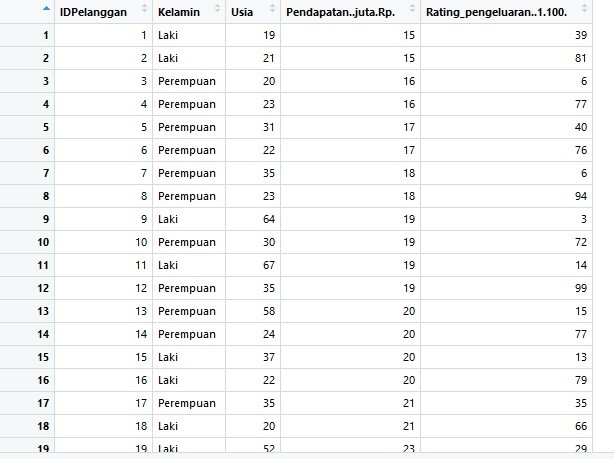
- Line 2 adalah mengimpor dataset
Jika benar, maka akan tampak sebagai berikut:
- Line 3 adalah melakukan slicing dataset. Kita hanya menginginkan kolom ke 4 (penghasilan tahunan) dan 5 (rating pengeluaran rutin) saja.
- Line 6 adalah menyiapkan random generatornya. Kali ini kita pilih 6 (tentu saja bebas).
- Line 7 adalah menyiapkan objek wcss untuk membandingkan jumlah kluster nantinya.
- Line 8-10 adalah looping untuk kalkulasi wcss. Perlu diperhatikan bahwa kita menggunakan tambahan $withinss. Mengapa? Coba arahkan kursor pada kmeans, kemudian ketik F1 maka akan muncul parameter kmeans. Kemudian lihat di bagian values, maka akan terlihat bahwa parameter yang diperlukan untuk menghitung within cluster adalah menggunakan parameter $withinss. Tampilan nya tampak sebagai berikut:

- Line 11-16 menampilkan plot skor wcss untuk setiap jumlah kluster. Tampilannya tampak sebagai berikut:
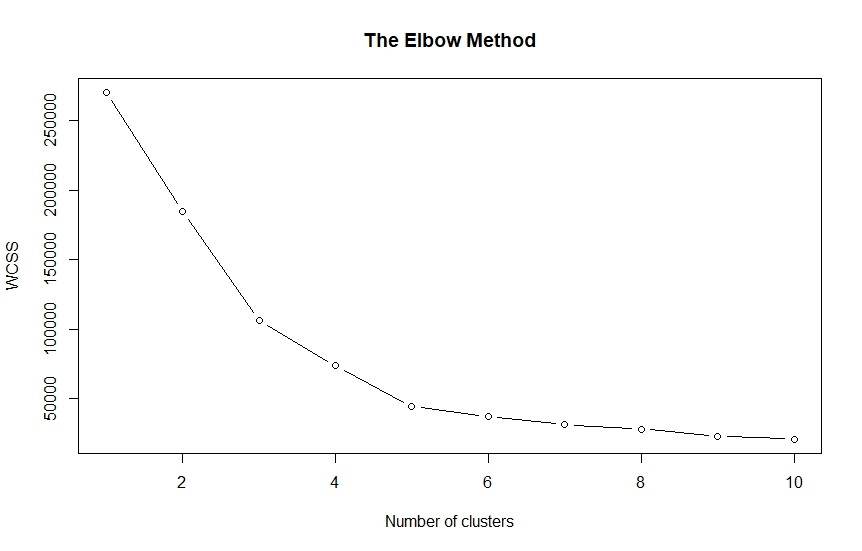
Bisa dilihat bahwa bentuk elbow (siku) terlihat saat jumlah kluster adalah 5 (K=5).
- Line 19 kita menentukan random number generator untuk kalkukasi data yang kita miliki.
- Line 20 melakukan perhitungan K-Means Clustering dengan jumlah kluster dari penilaian wcss yaitu 5 kluster.
- Line 21 adalah membuat objek y_kmeans sebagai hasil dari pembagian kluster di line 20. Perlu diperhatikan, tambahkan metode cluster di belakangnya.
- Line 24, mengimpor library cluster untuk menampilkan visualisasi K-Means nya.
- Line 25 sampai 35 adalah visualisasi nya. Jika benar, maka akan tampak sebagai berikut:

Terlihat ada 5 kluster yang berhasil memasukkan semua data points.
Untuk melanjutkan membaca, silakan klik halaman berikutnya di bawah ini.
makasih pak, sangat jelas detail dan bisa di jalankan tanpa adanya kesulitan
Sama-sama, semoga bermanfaat 🙂
Kalau mengacu pada formula machine learning (Tom M. Mitchell), Formula T,P,E (Task,Performance,Experience) untuk kasus clustering/unsupervised learning ini mengidentifikasinya bagaimana ya pak?
Definisi Mitchell sangat cocok jika ditempatkan untuk reinforcement learning, karena mudah sekali menentukan mana T, P, dan E. Definisi ini juga masih relevan untuk supervised learning, karena parameter untuk evaluasinya jelas seperti akurasi, confusion matrix, atau loss function (untuk deep learning). Berbeda dengan unsupervised learning, evaluasi parameternya tidak jelas (tidak baku), namun masih bisa sedikit dielaborasi: Task = Apa tugas algoritmanya = Membagi data ke dalam beberapa clusters Experience = Data apa saja yang harus dikumpulkan = Menggunakan data point di sekeliling cluster yang sudah ada untuk menentukan ia berada di cluster mana Performance = Bagaimana mengevaluasi hasilnya = Bisa… Read more »
cara menampilkan table dataset dan dataframe gimana? thanks
Halo, mungkin maksudnya cara melihat variabelnya ya?
Jika menggunakan spyder, cukup klik 2x di bagian dataset atau y_kmeans di ‘Variabel explorer’.
Nanti akan terlihat tabel yang menunjukkan dataset dan y_kmeans nya.
Jika menggunakan R solusinya juga sama, cukup klik 2x di variabel tersebut.
Semoga menjawab 😀
saya kurang paham spyder soalnya saya hanya menggunakan jupyter notebook yg muncul hanya gambar elbow dan hasil clustering nya saja apa ada cara lain jika menggunakan jupyter notebook? Terimakasih pak
Halo, untuk menampilkannya di jupyter notebook juga sangat mudah.
Misal jika ingin menampilkan tabel ‘dataset’ maka cukup ketikkan ‘dataset’ <-- tanpa tanda petik, lalu ketik ALT+ENTER di keyboard (atau tombol Run di Jupyter Notebook) maka akan muncul hasilnya di layar. Semoga membantu 😀
kalau tabel basil clustring (y_means) bisa? maaf banya tanya baru belajar? saya coba pake algoritma r sudah bisa cuman install spyder ada error saya ga tau kenapa jadi saya masih penasaran
Gunakan Anaconda saja saat menginstall spyder maupun jupyter notebook.
Bisa dilihat cara install Anaconda di artikel saya tentang ‘Belajar Python’.
supaya tahu id mana di cluster mana..karena di website bapak tidak ada keteranganya cluster merah itu id berapa saja dst..terimakasih pak
Untuk tahu id berapa masuk ke cluster berapa cukup ketikkan indeksnya di layar.
Misal ingin mengetahui ID ke 3 (indeks dimulai dari nol) ada di cluster mana, ketik ‘y_kmeans[2]’ kemudian ketik ALT+ENTER maka akan muncul di layar ia masuk di cluster 3 (indeks dimulai dari nol).
Atau jika ingin melihat pengelompokan cluster semua ID cukup lihat ‘y_kmeans’ nya.
Ada baiknya belajar dasar-dasar python untuk mempermudah (bisa dibaca di artikel saya juga).
Semoga membantu
terimakasih banyak pak infonya sangat membantu semoga ilmunya berkah ya pak 😀
halo pak, saya mau bertanya, dari sekian banyak kolom yang ada dalam dataset, bagaimana menentukan 2 kolom terakhir untuk digunakan dalam kmeans clustering?
Halo,
Tinggal dilihat saja permasalahannya, variabel apa saja yang dianggap penting oleh si pengambil keputusan.
Dalam hal ini kita memang ingin mengelompokkan berdasarkan besar pendapatan dan rating pengeluarannya.
Semoga menjawab.
misalnya pak, kita mengacu penggunaan data iris yang sering digunakan, nah dari kebanyakan pengaplikasian iris dataset pada kmeans clustering,variabel yang digunakan adalah petal width dan petal length. apakah ada teknik khusus pak? ataukah di kmeans itu sendiri, sudah memilih variabel mana yang cocok untuk dikelompokkan?
Tidak ada teknik khusus. Untuk solusi awal, cukup masukkan semua variabel dan gunakan elbow method nanti akan menunjukkan jumlah kluster yang terbaik berapa.
Bisa juga dicoba-coba hanya menggunakan beberapa variabel saja untuk klustering dan bandingkan hasilnya jika menggunakan semua variabel.
Silakan berkreasi 🙂
halo pak, mau bertanya lagi, bagaimana pengerjaan taknik elbow secara manual ya pak?
Elbow method sudah saya jelaskan di artikel ini. Formulanya ada, tinggal hitung saja secara manual.
terimakasih pak, saya sudah mencoba. Saya mau bertanya kembali, apakah bapak ada memuat artikel tentang k-means yang memakai trick kernel (kernel K-Means)? saya sudah mencari di website ini dan hasilnya not found.
Saya bary pertama kali memakai RStudio ini, mu tanya kalau muncul “Error : objeck ‘wcss’ not found’ itu kenapa ya?. Itu muncul nya setelah baris for di Run
Halo, kemungkinan objek wcss (line 7) belum dieksekusi.
Terimakasih Pak, yg itu sudah berhasil dan sudah muncul grafiknya. Cuman saya masih bingung dengan hasilnya, hasil bapak kenapa bisa 50000, 100000 dst…? Sedangkan grafik saya hasilnya 0e+00 dan 4e+10, itu kenapa ya? boleh dibantu lagi pak…
Hasil 50000 dan 100000 di bagian mananya? Apakah ini bahas K-Means?
Iya pak membahas k-means
yg bingung di eksekusi line ke berapa?
Sudah di eksekusi dan grafiknya sudah muncul. Kalau grafik bapak kan bagian wcss di grafiknya itu mucul angka 50000, 100000, 150000 dst. sedangkan saya muncul di bagian wcss grafiknya itu 0e+00, 4e+10. itu kenapa ya pak? apa itu karena pengaruh data yang dimasukkan?
Oh ini bahas grafik WCSS, saya pikir grafik K-Means nya.
Apakah ini pakai data yang sama persis seperti di website ini, atau pakai data sendiri?
Sepertinya pakai data sendiri ya.
Nilai WCSS adalah nilai sum of squares, tidak perlu khawatir. Nilai 4e+10 (setara dengan 40.000.000.000) disingkat oleh programnya karena memang terlalu panjang jika ditampilkan utuh.
Yang penting fokus saja dengan hasil grafiknya, dan gunakan metode elbow method, sehingga bisa dilihat jumlah kluster yang tepat.
Semoga menjawab.
Iya pak datanya menggunakan data sendiri, jadi tidak ada masalah berarti ya pak? saya kira itu ada error atau apa. Terimakasih banyak pak jawabannya sangat membantu sekali
caranya gimana pak? apa eksekusi perbaris? saya error terus
Error di baris ke berapa? Pakai Python atau R?
Aslm pak..mo tanya ttg k-means..
Jika data yg saya punya dlm bentuk data categorical sebanyak 7 fitur dan datanya sebanyak 100 baris..
Bagaimana cara mengubah data categorical ke dlm numeric?
Kl menggunakan python source code nya bagaimana?
Terima kasih..
Wlkmslm,
Saya asumsikan 7 fitur yang dimaksud adalah 7 kolom ya.
Jadi ada banyak kategori dan terdiri dari 7 fitur (kolom) dengan total 100 baris.
Di Python bisa gunakan library sklearn, lalu pakai method LabelEncoder.
Ini saya kasi link nya biar bisa belajar langsung dari sumbernya:
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
Semoga menjawab.
mas izin belajar dari code nya.
terima kasih buat ilmunya 🙂
pak saya mau bertanya kalo untuk data pekanggan hotel bisa di cluster?dan outputnya segementasi pelanggan bisa?saya masih kurang paham pak terimakasih
Jawabannya bisa.
selamat siang pak, mau bertanya saya punya data facebook untuk user yang melakukan penjualan online baik melalui vidio, status, photo dan link dengan feature status_publis yang berisi tanggal dan waktu publis, dan reaksi terhadap penjualan yakni berupa comment, likes, share. Kemudian setelah saya analisis ternyata status_publis tersebut bisa saya perlebar lagi menjadi hari publis jualan, waktu publis jualan, bulan publis jualan, dan tahun publis jualan dengan satuan yang berbeda-beda. Saya mau bertanya, apakah saya bisa mengelompokkan data saya tersebut menggunakan k-means walaupun satuannya berbeda-beda yakni ada yang satuan bulan, tahun, hari, dan jam serta untuk reaksi seperti commens, likes, shares… Read more »
K-Means bisa-bisa saja digunakan untuk membuat cluster. Tapi saya tidak paham mengapa berusaha mencampurkan data dengan satuan yang berbeda-beda?
Cari tujuan besarnya, lalu cari tools (metode) yang sesuai, dan jangan paksakan tools untuk tujuan tertentu karena bisa saja tidak pas.
oo begitu terimakasih pak. Mau bertanya kembali, apakah bapak pernah membahasa Kernel K-Means?
Pak kalau hasil uji k-means pakai silhuette coefficient dan purity measure itu bagaimana penerapannya pada python, mohon bantuanya pak
Hanya beda teknik perhitungannya saja.
Ini sama halnya di statistik untuk menentukan error bisa menggunakan MSE, SSE, RMSE dan banyak parameter lainnya.
Penerapannya bisa dilihat di web sklearn nya langsung. Cukup ketikkan di Google sklearn silhouette coefficient, dan dipelajari sendiri penerapanya.
Kunci penggunaannya adalah harus ada rujukannya, kenapa harus menggunakan parameter tersebut. Rujukan terbaik adalah jurnal internasional Q1 dalam rentang 5 tahun terakhir, dan text book adalah pilihan terakhir.
Hallo pak, Maaf sebelumnya pak, saya ingin bertanya untuk pengukuran kualitas dari clustering. sebenarnya saya sendiri masih bingung dalam hal penerapan Teknik Elbow, silhouette, dan DBI. dan jujur, saya sangat kurang paham dalam statistika karena memang diajarkan hanya untuk digunakan, menurut bapak, dari ketiga metoda diatas yang paling cocok untuk pengukuran clustering itu yang mana ya pak? selain itu untuk keyword dalam mencari di jurnal sekiranya apa ya pak? sudah beberapa belakangan ini saya sedikit buntu. sekian dan terima kasih pak
Hmm, kalau untuk keperluan riset, mas Ekki bisa buat riset sendiri. Bandingkan ketiga metode itu dan lihat performanya masing-masing.
Untuk pencarian riset di bidang clustering bisa mulai dari google scholar, lalu ketikkan ‘best method for clustering’. Nanti akan muncul banyak list, mulailah baca dari yang paling baru (mulai tahun 2020, 2019, dan mundur).
Kalau untuk keperluan sehari-hari (aplikasi) yang banyak dikenal orang adalah elbow method.
Semoga menjawab.
Terima kasih pak atas jawabannya. Saya ingin bertanya kembali. Sebelumnya, Saya sudah mencoba ketiganya pak, tapi hasilnya tidak bersinergi. Jika salah satunya hasilnya bagus, apakah saya perlu menggunakan salah satunya saja pak?
Misal, di dalam riset saya silhouette sangat bagus jika k = 2, sedangkan di elbow k=2 & k=3 termasuk, dan pada davies bouldin k=5 yang hasilnya bagus. Nah jika dilihat dari validasinya berarti lebih baik saya memasukkan sillhouette dan elbow ya pak?
Halo,
Iya silakan dipilih mana yang performanya paling baik sesuai dengan indikatornya.
Silakan ditentukan sendiri apa parameter (indikator) baik tidaknya performa dari ketiga metode tersebut.
Semoga menjawab.
mas saya mau bertanya tentang Mengimpor dataset dataset = pd.read_csv(‘Pengunjung_mall.csv’) seperti apa
Maaf mau tanya mengenai line 8 bagian python, kenapa ya harus ada proses slicing?
Sudah ada keterangan di penjelasan tiap barisnya.
baik pak, tapi bagaimana caranya misal kita memiliki variabel lebih dari 2, misal dengan 5 variabel? apakah masih bisa digambarkan plotnya?
terimakasih….
Banyak variabel tidak masalah, tapi tidak mungkin divisualisasikan jika lebih dari 3 variabel (3 dimensi).
lantas… bagaimana pak caranya mengetahui data kita telah diklasterkan dengan baik, seperti di line 38.
Line 38 adalah perintah untuk menunjukkan tampilan plot yang dibuat.
Untuk multidimensi bisa gunakan Self-Organizing Maps (SOM).
yaps, maaf pak mau tanya sekali lagi. apakah bapak ada rekomendasi buku mengenai python yg menjelaskan secara lengkap mengenai K-Means Elbow dan Machin learning lainnya? terimakasih pak…
Bisa dicari di google scholar untuk jurnal terbaru tentang machine learning.
yappps, terimakasih pak atas jawabannya.
sangat membantu🙂
cara menghiyung akurasi dari k means bagaimana pak ?
Clustering tidak punya akurasi, karena kita tidak pernah punya label (var dependen) aslinya.
Performa clustering bisa dievaluasi menggunakan nilai silhouette.
Halo pak saya mau bertanya pada line 8 melakukan slicing menggunakan python. Cara menampilkan kolom tabelnya bagaimana ya pak. Saya menggunakan jupyter kolom tersebut tidak tampil.
Di Jupyter memang tidak muncul. Saya menggunakan Spyder
mohon maaf pak. ini kan baru sampai mengelompokan data sesuai kedekatannya.
nah jika saya ingin memasukan data baru (setelah terbentuk klaster) untuk mengetahui, kira2 data yg saya input masuk ke klaster yg mana. apakah bisa?
jika ya… apakah bisa meng-share contoh codenya.. terimakasih
Ada 2 cara, cara yang pertama adalah lakukan clustering dari awal dengan data-data yang baru. Karena nanti centroidnya akan berubah dengan data-data yang baru dimasukkan.
Cara kedua adalah setelah ahsil cluster keluar, misal dipilih 3 cluster. Maka ubah datasetnya menjadi permasalahan klasifikasi, dengan cluster adalah labelnya.
Izin bertanya Pak, random_state=42 itu pakai default value ya?, darimana ya dapat 42 dan apakah pengaruh nya kalau kita salah dalam menentukan random_state Pak?, Terimakasih banyak Pak🙏🏻
Angka random state bebas. Ini untuk replikasi hasil saja. Jika ingin mendapatkan hasil yang sama, maka selalu gunakan angka random state yang sama juga.
cara memsukan dataset ke jupyternya gimana?
Tempatkan filenya di folder yang aktif saat menggunakan Jupyter
makasih ya… ini lagi cocok sambil skripsi :”)
Sama2, senang jika bermanfaat