

Bahasa R
# Mengimpor dataset
dataset = read.csv('Iklan_sosmed.csv')
dataset = dataset[3:5]
# Encode variabel Beli sebagai faktor
dataset$Beli = factor(dataset$Beli, levels = c(0, 1))
# Membagi data ke dalam Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Beli, SplitRatio = 0.75)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
training_set[, 1:2] = scale(training_set[, 1:2])
test_set[, 1:2] = scale(test_set[, 1:2])
# Membuat model Random Forest Classification ke Training Set
library(randomForest)
set.seed(123)
classifier = randomForest(x = training_set[1:2],
y = training_set$Beli,
ntree = 500)
# Memprediksi hasil Test Set
y_pred = predict(classifier, newdata = test_set[1:2])
# Membuat Confusion Matrix
cm = table(test_set[, 3], y_pred)
# Visualisasi hasil Training Set
library(ElemStatLearn)
set = training_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Usia', 'EstimasiGaji')
y_grid = predict(classifier, grid_set)
plot(set[, 1:2],
main = 'Random Forest Classification (Training set)',
xlab = 'Usia', ylab = 'Estimasi Gaji',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '19', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
# Visualisasi hasil Test Set
library(ElemStatLearn)
set = test_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Usia', 'EstimasiGaji')
y_grid = predict(classifier, grid_set)
plot(set[, 1:2], main = 'Random Forest Classification (Test set)',
xlab = 'Usia', ylab = 'Estimasi Gaji',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '19', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))
Penjelasan:
- Line 2 mengimpor datasetnya.
- Line 3 melakukan slicing. Kita hanya butuh kolom Usia, Gaji dan Beli.
- Line 6 mengonversi kolom Beli sebagai faktor (categorical).
- Line 9 menginstall library caTools. Jika pembaca belum menginstallnya, maka cukup hilangkan tanda pagar.
- Line 10 menjalankan library caTools.
- Line 11 menentukan random number generator (RNG) 123, sehingga jika pembaca ingin menduplikasikan hasil olah data akan selalu sama hasilnya untuk RNG yang sama.
- Line 12-14 membagi data ke training set dan test set.
- Line 17-18 melakukan feature scaling.
- Line 21 menjalankan library randomForest.
- Line 22 menentukan random number generator (RNG) 123 untuk
randomForest (angka set.seed bisa dirubah terserah). - Line 23 mendefinisikan objek classifier untuk model random forest, dengan variabel X adalah kolom usia dan gaji, sementara y aalah kolom keputusan beli/tidak. parameter lain yang dipilih adalah ntree dan kita isi 500. Artinya kita membuat 500 decision tree untuk mengelompokkan dataset ke keputusan beli/tidak.
- Line 28 mendefinisikan y_pred untuk memprediksi hasil modelnya ke test set.
- Line 31 mendefinisikan confusion matrix-nya(cm). Jika dijalankan maka tampak sebagai berikut:
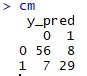
Tabel confusion matrix di atas menunjukkan bahwa prediksi kita cukup baik. Dari 100 prediksi test set, kita salah sebanyak 15 kali, sehingga akurasinya adalah 85%. Akurasinya jauh lebih baik jika dibanding decision tree classification yaitu 83%.
- Line 34 menjalankan library ElemStatLearn untuk visualisasi hasil model.
- Line 35-47 adalah perintah untuk visualisasi hasil model terhadap training set. Jika dieksekusi maka tampak sebagai berikut:

Hasil random forest classification untuk training set
Zona merah adalah zona di mana data pelanggan memutuskan untuk tidak membeli. Sementara zona hijau adalah zona di mana pelanggan memutuskan untuk membeli. Dua zona ini adalah hasil dari model random forest yang dibuat.
Titik-titik adalah data pelanggan. Titik merah adalah data pelanggan yang memutuskan untuk tidak membeli, sementara titik hijau adalah data pelanggan memutuskan untuk membeli mobil.
Titik merah yang berada di zona hijau adalah prediksi yang salah. Begitu juga dengan titik hijau yang berada di zona merah juga merupakan prediksi yang salah.
- Line 50-62 adalah perintah untuk visualisasi hasil model terhadap test set. Jika dieksekusi maka tampak sebagai berikut:

Hasil random forest classification untuk test set
Hasil visualisasi test set cukup baik. Seperti yang di bahas di bagian confusion matrix di atas, terlihat bahwa dari 100 prediksi, model ini hanya meleset sebanyak 15 titik. Dengan begitu, akurasinya 85%. Nilai akurasi ini juga bisa dilihat di confusion matrix di line sebelumnya.
Saya harap pembaca bisa memahami teknik random forest classification ini dan tentunya bisa mengaplikasikannya untuk memecahkan persoalan nyata.
Terus kunjungi web saya untuk belajar bersama teknik AI lainnya.
Terima kasih.
Penjelasannya jelas sekali.. terima kasih Mas Herlambang