
")
Bahasa R
# Mengimpor dataset
dataset = read.csv('Wine.csv')
# Membagi dataset menjadi training set dan test set
# install.packages('caTools')
library(caTools)
set.seed(111)
split = sample.split(dataset$Customer_Segment, SplitRatio = 0.8)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Proses feature scaling
training_set[1:13] = scale(training_set[1:13])
test_set[1:13] = scale(test_set[1:13])
# Menjalankan algoritma PCA
# install.packages('caret')
library(caret)
# install.packages('e1071')
library(e1071)
pca = preProcess(x = training_set[1:13], method = 'pca', pcaComp = 2)
training_set_pca = predict(pca, training_set)
training_set_pca = training_set_pca[c(2, 3, 1)]
test_set_pca = predict(pca, test_set)
test_set_pca = test_set_pca[c(2, 3, 1)]
# Menjalankan support vector machine ke training set
mesin_klasifikasi = svm(formula = Customer_Segment ~ .,
data = training_set_pca,
type = 'C-classification',
kernel = 'linear')
# Memprediksi hasil test set
y_pred = predict(mesin_klasifikasi, newdata = test_set_pca[1:2])
# Membuat Confusion Matrix
cm = table(test_set_pca[, 3], y_pred)
# Visualisasi Training set
library(ElemStatLearn)
set = training_set_pca
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('PC1', 'PC2')
y_grid = predict(mesin_klasifikasi, newdata = grid_set)
plot(set[, -3],
main = 'SVM (Training set) - PCA',
xlab = 'PC1', ylab = 'PC2',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 2, 'deepskyblue', ifelse(y_grid == 1, 'springgreen3', 'tomato')))
points(set, pch = 21, bg = ifelse(set[, 3] == 2, 'blue3', ifelse(set[, 3] == 1, 'green4', 'red3')))
# Visualisasi Test set
set = test_set_pca
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('PC1', 'PC2')
y_grid = predict(mesin_klasifikasi, newdata = grid_set)
plot(set[, -3], main = 'SVM (Test set) - PCA',
xlab = 'PC1', ylab = 'PC2',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 2, 'deepskyblue', ifelse(y_grid == 1, 'springgreen3', 'tomato')))
points(set, pch = 21, bg = ifelse(set[, 3] == 2, 'blue3', ifelse(set[, 3] == 1, 'green4', 'red3')))
Penjelasan:
- Line 2 mengimpor dataset yang diperlukan.
- Line 5 menginstall package caTools. Jika pembaca belum memiliki package ini di RStudio, cukup hilangkan tanda pagar (#).
- Line 6 menjalankan library caTools.
- Line 7 menentukan bilangan random 111. Jika pembaca menggunakan bilagan randm yang sama, maka nanti pembagian dataset ke training dan test set akan mendapatkan hasil yang sama seperti yang kita bahas sekarang.
- Line 8 membagi dataset menjadi 2 yaitu training set dan test set, dengan kmposisi 80:20.
- Line 9-10 adalah pembagian untuk training set dan test set. Bernilai TRUE untuk mendapatkan komposisi 80% dan FALSE untuk 20%.
- Line 13 adalah proses feature scaling untuk training set, di mana yang diprses adalah kolom 1-13 saja.
- Line 14 adalah proses feature scaling untuk test set, di mana yang diproses juga kolom 1-13.
- Line 17 menginstall package caret. Jika belum terinstall cukup hilangkan tanda pagar. Jika tidak bisa terinstall dengan benar, pastikan R dan RStudi yang terinstall adalah versi terbaru semuanya. Package caret ini akan digunakan untuk menjalankan algoritma PCA.
- Line 18 menjalankan package caret.
- Line 19 menginstall package e1071. Jika belum terinstall cukup hilangkan tanda pagar.
- Line 20 menjalankan package e1071.
- Line 21 mendefinisikan variabel dengan nama pca untuk objek PCA kita. Perintah yang diperlukan adalah preProcess. Untuk bisa mengetahui parameter apa saja yang diperlukan, arahkan kursor pada preProcess kemudian ketik F1 di keyboard. Tampilannya adalah sebagai berikut:

Bisa kita lihat bahwa parameter yang diperlukan adalah x yang merupakan data training_set kita dari kolom 1-13. Kemudian method kita isikan pca, dan pcaComp kita isikan 2 karena kita hanya memerlukan 2 PC (principal component) saja untuk visualisasi 2 dimensi, di mana masing-masing PC mewakili masing-masing sumbu x dan y.
- Line 22 mendefinisikan variabel training_set_pca yang merupakan hasil dari algoritma pca. Kita gunakan perintah (fungsi) predict, diikuti dengan pca dan data yang ingin diproses (training_set). Jika dieksekusi maka tampilannya sebagai berikut:
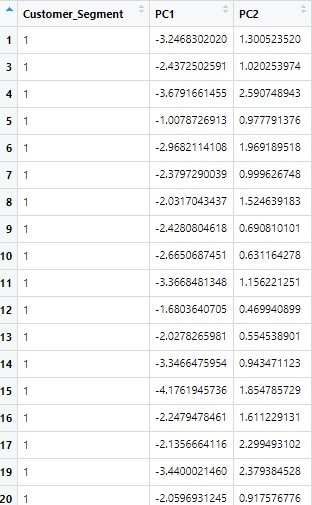
Sekarang kita memiliki hasil dari PCA, di mana kita mendapatkan 2 variabel independen yang baru (2 PCs). Kita ingin ubah pengaturan kolomnya melalui line selanjutnya.
- Line 23 merubah pengaturan kolom agar PC1 menjadi klom pertama, PC2 kolom kedua dan Custmer_Segment kolom ketiga. Tampilan training_set_pca sekarang menjadi seperti ini:
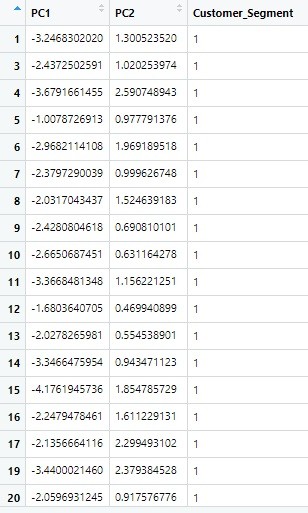
- Line 24-25 sama seperti line 22-23 namun kali ini untuk test set.
- Line 28 kita definisikan variabel mesin_klasifikasi sebagai objek bagi svm. Sebagai variabel dependen adalah Customer_Segment. Untuk menentukan semua variabel (selain Customer_Segment) sebagai independen variabel, maka cukup tuliskan ~. di R, secara otomatis R akan merangkum semua kolom sebagai variabel independen. Kemudian data yang diperlukan adalah training_set_pca, type kita isi C-classification, dan kernelnya adalah linear (tentu saja pembaca bebas memilih kernelnya). Pembahasan tentang kernel SVM silakan baca artikel saya di link ini.
Pembaca tentu saja bisa menggunakan teknik klasifikasi lainnya seperti logistic regression, random forest, decision tree dan lain sebagainya. Di pembahasan bahasa python kita sudah menggunakan logistic regression. Kali ini di bahasa R kita akan gunakan SVM (support vector machines).
- Line 34 mendefinisikan y_pred, di mana kita mencoba memprediksi klasifikasi pelanggan berdasarkan model mesin_klasifikasi yang sudah dibuat di line 28. Data yang digunakan adalah test_set_pca. Nantinya kita akan bandingkan y_pred dengan y sesungguhnya (test_set). Jika kita ketikkan y_pred di console RStudio, maka tampilannya sebagai berikut:

Sekarang kita ingin membandingkan y_pred dengan test_set melalui confusion matrix.
- Line 37 membuat confusion matrix dengan mendefinisikan variabel cm. Perbandingannya adalah test_set kolom ketiga dengan nilai y_pred. Jika kita ketikkan cm di console, maka tampilannya sebagai berikut:

Bisa kita lihat bahwa prediksi model mesin_klasifikasi kita sangat baik, dengan akurasi 100% (tidak ada kesalahan sedikitpun). Sekarang kita ingin melihat visualisasinya, karena memang inilah tujuan kita menggunakan PCA.
- Line 40 menjalankan library ElemStatLearn khusus untuk visualisasi.
- Line 41-53 adalah perintah untuk membuat visualisasi untuk training_set. Hasilnya tampak sebagai berikut:

Bisa dilihat bahwa pada hasil PCA kita hasilnya cukup baik. Terlihat ada 3 zona (segmen pelanggan) dengan warna merah (kelompok 1), hijau (kelompok 2) dan biru (kelompok 3). Masing-masing titik merepresentasikan data barisnya. Ada beberapa titik yang berada di zona yang salah, seperti 1 titik biru di zona merah, beberapa titik hijau di zona biru, dan beberapa titik biru di zona hijau, namun sangat sedikit sekali.
Sekarang mari kita lihat visualisasi prediksi model kita (mesin_klasifikasi) dalam memprediksi variabel dependen (test_set).
- Line 56-67 adalah perintah untuk membuat visualisasi untuk test_set. Hasilnya tampak sebagai berikut:

Kita bisa melihat bahwa visualisasinya sangat baik. Terlihat tidak ada kesalahan prediksi sedikit pun, sama seperti yang kita lihat di confusion matrix. Dengan demikian, akurasi model kita 100%.
Poin utama yang kita pelajari adalah untuk bisa melakukan visualisasi dengan banyak variabel (13 variabel independen) ke dalam 2 dimensi, maka harus melalui proses teknik PCA (principal component analysis) terlebih dahulu.
Dengan PCA, kita bisa mereduksi 13 variabel tadi menjadi 2 variabel baru, di mana 2 variabel baru ini bisa menjelaskan variasi (variance) terbesar yang dimiliki datasetnya. Dengan PCA, kita merubah variabelnya ke dalam bentuk lain, namun masih mempertahankan karakteristik datanya.
Sampai di sini saya harap pembaca mengerti fungsi dari PCA, khususnya dalam hal visualisasi data. Pembaca juga bisa mengaplikasikan PCA ini ke permasalahan lain yang sedang dihadapi. Cukup sesuaikan script yang ada di artikel ini dengan dataset yang dimiliki.
Jikapembaca memiliki pertanyan silakan tulis di kolom komentar.
Terus kunjungi website saya untuk selalu belajar teknik-teknik baru di dunia AI maupun machine learning.
Tetap semangat belajar AI!
Pages: 1 2
Apa sebenarnya itu Mechine Learning? Apakah coding diatas merupakan salah satu proses Mechine Learning
Halo, machine learning itu sebuah keilmuan, lebih detailnya silakan baca artikel saya tentang machine learning atau video Youtube saya membahas itu.
Programming (coding) adalah cara kita berkomunikasi dengan mesin/komputer. Jadi coding dan machine learning adalah 2 hal yang berbeda.
Salah satu cara agar komputer/mesin mau melakukan apa yang kita inginkan adalah melalui teknik machine learning. Implementasinya menggunakan programming.
Semoga menjawab.
Data wine.csv ada dimana ya?
Link dataset wine.csv ada di artikel bagian atas.
Ada tutorial menggunakan ICA di R bang ?
bang mau nanya , cara print nilai akuasi prediksi yang 97% itu gmana bang caranya?
mohon dbls bang…makasih
Tinggal gunakan fungsi print().
Jika bingung bisa tonton tutorialnya di Youtube saya.
Bang menyimpan file wine.csv nya di bagian file mana ya bang..agar dapat dibaca oleh mesin nya..letak simpannya
Tempatkan di satu folder yang sama dengan direktori yang sedang aktif.
bang mau nnya, cara saving model yang udah kita latih bagaimana ya bang ? soalnya mau saya jadiin sebagai model untukuntuk input file prediksi pembuatan web untuk interface nya ?