
")
Catatan penting : Jika Anda benar-benar awam tentang apa itu Python, silakan klik artikel saya ini. Jika Anda awam tentang R, silakan klik artikel ini.
Di artikel kali ini, kita akan belajar bagaimana PCA (Principal Component Analysis) mampu digunakan untuk memecahkan persoalan nyata di dunia industri.
Dataset yang kita gunakan diambil dari database milik UCI (University of California, Irvine) melalui link ini. Dataset ini merupakan dataset yang cukup ternama di dunia machine learning, karena sudah disitasi oleh puluhan paper ilmiah (international journals).
Untuk pembelajaran kali ini, silakan pembaca unduh (download) datasetnya di link ini.
Mari kita lihat ilustrasi dari dataset yang kita miliki:

Kita memiliki 13 variabel independen (dimulai dari kolom ‘Alcohol’ hingga ‘Proline’) dan 1 variabel dependen, yaitu Customer_Segment. Dataset ini menceritakan bahwa perusahaan produsen wine ini telah berhasil membagi-bagi konsumennya ke dalam 3 segmen. Di masing-masing segmen ini konsumen memiliki karakteristik komposisi wine yang berbeda. Keuntungan dari pembagian segmen pelanggan ini memudahkan promosi perusahaan ke pelanggannya.
Permasalahan yang muncul adalah kita tidak mungkin bisa memvisualisasikan 13 variabel independen dalam sebuah grafik 2 dimensi. Jika kita paksakan untuk membuat ilustrasi visualnya, maka kita memerlukan 13 sumbu, di mana setiap sumbu mewakili setiap variabel independe. Solusinya adalah dengan menggunakan PCA, di mana kita memerlukan 2 PC (principal components) tertinggi yang bisa menjelaskan variasi (variance) terbesar dari datasetnya.
Jika pembaca bingung tentang apa itu PCA dan apa itu PC (principal component), silakan mereview materi PCA yang sudah saya bahas di link ini.
Kita akan menyelesaikan permasalahan ini dengan menggunakan bahasa Python dan R.
Bahasa Python
# Mengimpor library yang diperlukan
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Mengimpor datasetnya
dataset = pd.read_csv('Wine.csv')
X = dataset.iloc[:, 0:13].values
y = dataset.iloc[:, 13].values
# Membagi data ke dalam Training set dan Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Proses Feature Scaling
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# Menjalankan algoritma PCA
from sklearn.decomposition import PCA
pca = PCA(n_components = None)
X_train = pca.fit_transform(X_train)
X_test = pca.transform(X_test)
hasil_variance = pca.explained_variance_ratio_ # Proses pengecekan variance
# Proses pemilihan PCs
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
pca = PCA(n_components = 2)
X_train = pca.fit_transform(X_train)
X_test = pca.transform(X_test)
hasil_variance2 = pca.explained_variance_ratio_
# Menjalankan algoritma logistic regression ke training set
from sklearn.linear_model import LogisticRegression
mesin_klasifikasi = LogisticRegression(random_state = 0)
mesin_klasifikasi.fit(X_train, y_train)
# Memprediksi test set berdasakan model logistic regression
y_pred = mesin_klasifikasi.predict(X_test)
# Membuat confusion matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
# Visualisasi Training Set
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, mesin_klasifikasi.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green', 'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i), label = j)
plt.title('Logistic Regression (Training set)')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show()
# Visualisasi Test Set
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, mesin_klasifikasi.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green', 'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i), label = j)
plt.title('Logistic Regression (Test set)')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show()
Penjelasan:
- Line 2-4 mengimpor library apa saja yang diperlukan.
- Line 7 mengimpor datasetnya.
- Line 8 dan 9 membagi datasetnya ke variabel independen X dan variabel dependen y. Untuk variabel X kita memerlukan kolom ke 0-13, dan variabel y memerlukan kolom terakhir.
- Line 12 mengimpor library yang diperlukan untuk membagi data ke dalam training set dan test set.
- Line 13 membagi data ke X_train dan X_test untuk variabel X. Kemudian y_train dan y_test untuk variabel y. Pembagian dilakukan dengan membagi 20% sebagai test set dan 80% sebagai training set.
- Line 16 mengimpor library untuk proses feature scaling. Untuk mereview silakan klik artikel saya di link ini.
- Line 17 mendefinisikan variabel sc sebagai objek untuk proses normalisasi.
- Line 18 melakukan proses feature scaling terhadap variabel X_train dengan perintah fit_transform.
- Line 19 melakukan proses feature scaling terhadap X_test dengan perintah transform saja. Perlu diperhatikan kita tidak memakai fit_transform, melainkan cukup transform saja karena X_test secara otomatis sudah melalui proses fit terhadap X_train. Proses pertama yang kita lakukan adalah sc_X.fit_transform(X_train), maka secara otomatis sc_X sudah di fit-kan terhadap X_train.
- Line 22 dari library sklearn.decomposition kita import PCA untuk bisa melakukan proses PCA nantinya.
- Line 23 mendefinisikan variabel pca sebagai objek untuk PCA kita. Parameter yang diperlukan adalah n_components, di mana kita harus menentukan berapa banyak PC (principal component) yang diperlukan.
Karena kita ingin membuat visualisasi 2D (2 dimensi), maka kita hanya memerlukan 2 PC saja. Namun, sebelum kita tentukan jumlah PC nya sejumlah 2, kita harus cek dulu seberapa banyak variasi (variance) yang bisa dijelaskan oleh 2 PC ini. Jika cukup relevan maka kita pilih 2 yang terbesar. Sampai di sini saya rasa bisa dipahami. Oleh karena itu, saat ini kita cukup tuliskan n_components = None terlebih dahulu.
Tips: untuk bisa melihat parameter apa saja yang diperlukan, silakan arahkan kursor pada PCA kemudian ketik CTRL+i di keyboard. Maka tampilan parameternya adalah sebagai berikut:

- Line 24 mengaplikasikan hasil perhitungan algoritma PCA ke X_train. Untuk bisa melakukannya kita butuh perintah fit_transform (penjelasannya mirip feature scaling).
- Line 25 melakukan proses transform hasil perhitungan PCA ke X_test.
- Line 26 mendefinisikan variabel hasil_variance untuk bisa melihat berapa variance yang bisa dijelaskan oleh setiap PC (principal component). Untuk bisa melakukannya, kita menggunakan perintah explained_variance_ratio_ yang merupakan method dari objek pca. Jika kita lihat variabel hasil_variance, maka tampak sebagai berikut:
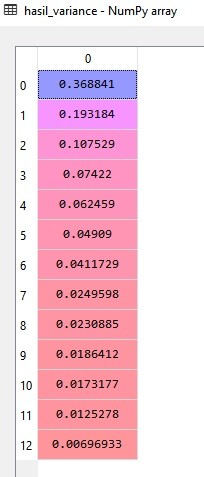
Bisa kita lihat bahwa kita memiliki 13 PCs yang merupakan hasil dari PCA. Mengapa hasilnya adalah 13 PCs? Karena kita memiliki 13 variabel independen.
Dari 13 PCs ini, kita bisa lihat juga 2 PC teratas, di mana jika kita jumlahkan (0.369 + 0.193) bisa menjelaskan variasi (variance) sebesar 0.562 (56.2%) dari total variasi di dataset dan ini cukup baik (>50%). Dengan demikian, 2 PCs teratas akan menjadi variabel independen yang baru.
Sekarang kita harus mengganti lagi nilai n_components yang ada di parameter PCA. Namun perlu diperhatikan bahwa X_train dan X_test adalah hasil dari feature scaling dengan n_components = None. Oleh karena itu kita harus mendefinisikan ulang X_train dan X_test kita.
- Line 29-36 mendefinsikan ulang X_train, X_test, y_train, dan y_test. Cukup menuliskan lagi perintah yang sama seperti line-line sebelumnya.
- Line 33 mendefinisikan pca dengan n_components = 2.
- Line 34 dan 35 proses PCA untuk X_train dan X_test. Jika kita lihat variabel X_train dan X_test sekarang, maka bisa dilihat bahwa ia hanya terdiri dari 2 variabel independen saja. Ilustrasinya adalah sebagai berikut:
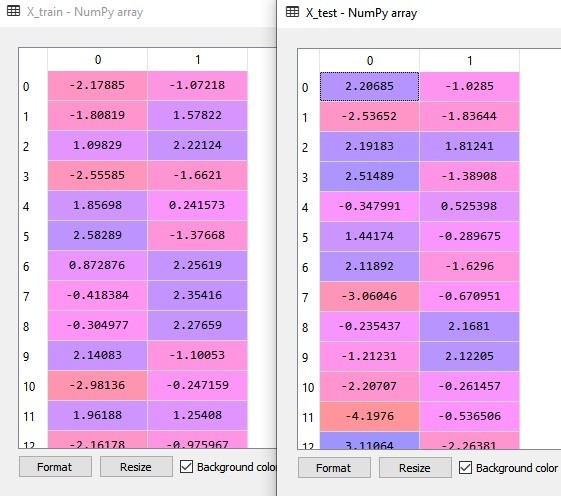
- Line 36 menunjukkan bahwa hasil_variance kedua PCs yang dihasilkan masih sama nilainya.
- Line 39 mengimpor library yang diperlukan untuk proses regresi logistik (logistic regression).
Tentu saja pembaca bisa menggunakan metode klasifikasi yang lain seperti misalnya SVM, KNN, random forest, dan seterusnya. Untuk bisa mengetahui jenis-jenis teknik klasifikasi yang sudah pernah dibahas, silakan klik link ini. Untuk pembahasan di bahasa Python kali ini, kita gunakan logistic regression.
- Line 40 mendefinisikan variabel dengan nama mesin_klasifikasi sebagai wadah dari hasil logistic regresion. Kita gunakan bilangan random 0, artinya jika pembaca juga menggunakan bilangan random yang sama, maka hasil yang didapatkan juga akan sama dengan apa yang saya tulis di sini.
- Line 41 mengaplikasikan logistic regression ke variabel X_train dan y_train kita. Intinya model mesin_klasifikasi akan mencari hubungan antara X_train dengan y_train melalui algoritma logistic regression.
- Line 44 mendefinisikan variabel y_pred, di mana kita mencoba memprediksi nilai y berdasarkan model yang sudah dipelajari oleh variabel mesin_klasifikasi. Kita mencoba memprediksi nilai y menggunakan nilai X_test. Kemudian kita bandingkan y_pred ini dengan nilai y yang sesungguhnya (y_test).
- Line 47 mengimpor library yang diperlukan untuk membuat confusion matrix.
- Line 48 mendefinisikan variabel cm untuk melihat hasil confusion matriksnya. Jika kita lihat variabel cm hasilnya tampak sebagai berikut:

Bisa kita lihat bahwa prediksi kita sangat baik. Model kita bisa memprediksi dengan tepat sebanyak 14 data di segmen 1, 15 data di segmen 2, dan 6 data di segmen 3. Sisanya hampir tidak ada kesalahan, kecuali hanya 1 data yang salah prediksi, di mana seharusnya ia berada di kelas 1, namun model kita memprediksi ia berada di kelas 2.
Jadi performa model logistic regression kita sangat baik dengan akurasi sebesar 97% (35/36).
Sekarang kita ingin melihat visualisasinya untuk training set dan test set, karena memang inilah tujuan mengapa kita menggunakan PCA. Kita akan gunakan warna merah untuk segmen 1, hijau untuk segmen 2, dan biru untuk segmen 3.
- Line 51 mengimpor library yang diperlukan untuk visualisasi.
- Line 52-66 adalah perintah untuk visualisasi. Jika dieksekusi maka tampilannya sebagai berikut:

Terlihat bahwa hasil dari training set cukup baik. Hanya ada sedikit titik-titik yang berada di warna yang salah, misal 2 titik hijau di zona merah, 1 titik hijau di zona biru dan 2 titik merah di zona hijau. Sekarang mari kita lihat visualisasi test set.
- Line 69-84 adalah perintah untuk visualisasi test set. Hasilnya tampak sebagai berikut:
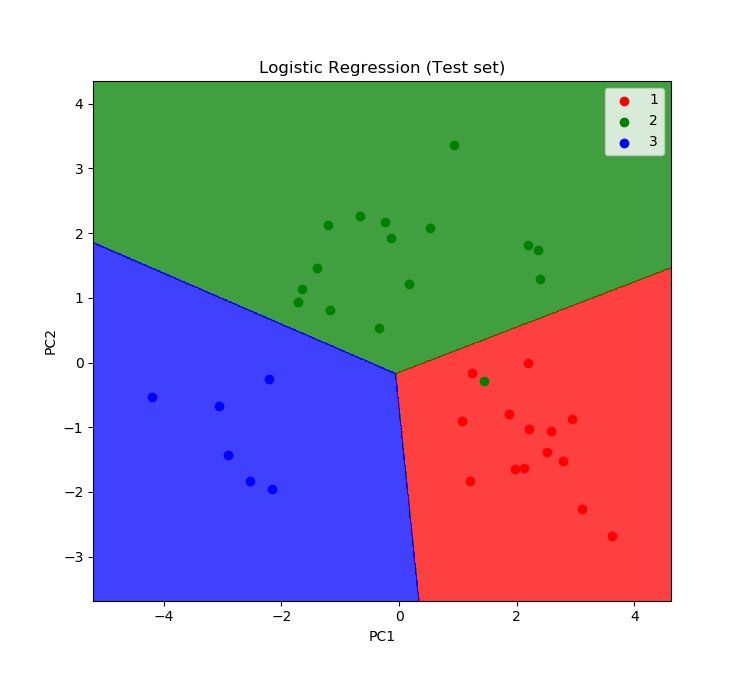
Melalui visualisasi ini kita bisa melihat bahwa hampir semua titik (komposisi wine) berada di zona (segmen customer) yang tepat. Sesuai dengan confusion matrix, bahwa hanya ada 1 kesalahan, yaitu 1 titik hijau di zona merah.
Kita sudah belajar bersama bagaimana memproses data dengan 13 variabel independen menjadi hanya 2 variabel independen (pilihan) saja. Dengan menggunakan teknik PCA, kita bisa dengan mudah melakukan visualisasi untuk kasus dengan variabel independen yang banyak.
Tentunya pembaca juga bisa melakukan hal yang sama. Cukup sesuaikan penulisan script di atas dengan dataset yang dimiliki.
Jika pembaca ingin belajar bagaimana menjalankan PCA di bahasa R, silakan klik tombol lanjut ke halaman selanjutnya di bawah ini.
Pages: 1 2
Apa sebenarnya itu Mechine Learning? Apakah coding diatas merupakan salah satu proses Mechine Learning
Halo, machine learning itu sebuah keilmuan, lebih detailnya silakan baca artikel saya tentang machine learning atau video Youtube saya membahas itu.
Programming (coding) adalah cara kita berkomunikasi dengan mesin/komputer. Jadi coding dan machine learning adalah 2 hal yang berbeda.
Salah satu cara agar komputer/mesin mau melakukan apa yang kita inginkan adalah melalui teknik machine learning. Implementasinya menggunakan programming.
Semoga menjawab.
Data wine.csv ada dimana ya?
Link dataset wine.csv ada di artikel bagian atas.
Ada tutorial menggunakan ICA di R bang ?
bang mau nanya , cara print nilai akuasi prediksi yang 97% itu gmana bang caranya?
mohon dbls bang…makasih
Tinggal gunakan fungsi print().
Jika bingung bisa tonton tutorialnya di Youtube saya.
Bang menyimpan file wine.csv nya di bagian file mana ya bang..agar dapat dibaca oleh mesin nya..letak simpannya
Tempatkan di satu folder yang sama dengan direktori yang sedang aktif.
bang mau nnya, cara saving model yang udah kita latih bagaimana ya bang ? soalnya mau saya jadiin sebagai model untukuntuk input file prediksi pembuatan web untuk interface nya ?