

Bahasa Python
# Mengimpor library
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Mengimpor dataset
dataset = pd.read_csv('Review_restoran.tsv', delimiter = '\t', quoting = 3)
# Line 10-34 adalah proses yang dilakukan setahap demi setahap (agar mudah dipahami)
# Melihat item pertama di dataset
dataset['Review'][0]
# Mengimpor library re dan NLTK
import re
import nltk
review = re.sub('[^a-zA-Z]', ' ', dataset['Review'][0])
review = review.lower()
review = review.split()
# Mendownload daftar kata yang ada (vocabulary)
nltk.download('stopwords')
from nltk.corpus import stopwords
# Memeriksa daftar kata di stopwords
inggris = stopwords.words('english')
indo = stopwords.words('indonesian')
# Menghilangkan kata yang tidak ada di stopwords
review = [word for word in review if not word in inggris]
# Melakukan proses stemming (penggunaan kata dasar)
from nltk.stem.porter import PorterStemmer
ps = PorterStemmer()
# Membersihkan kalimat dari kata yang ada di stopwords
review = [ps.stem(word) for word in review if not word in inggris]
review = ' '.join(review)
# Melakukan proses cleaning pada teks
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
corpus = []
for i in range(0, len(dataset)):
review = re.sub('[^a-zA-Z]', ' ', dataset['Review'][i])
review = review.lower()
review = review.split()
ps = PorterStemmer()
review = [ps.stem(word) for word in review if not word in inggris]
review = ' '.join(review)
corpus.append(review)
# Membuat model Bag of Words
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
X = cv.fit_transform(corpus).toarray()
y = dataset.iloc[:, 1].values
# Membagi dataset ke dalam Training dan Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
# Menggunakan beberapa teknik klasifikasi untuk membandingkan akurasinya
# Metode Logistic Regression
from sklearn.linear_model import LogisticRegression
classifierLR = LogisticRegression(random_state = 0)
classifierLR.fit(X_train, y_train)
# Metode K-nearest Neighbors
from sklearn.neighbors import KNeighborsClassifier
classifierKNN = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski', p = 2)
classifierKNN.fit(X_train, y_train)
# Metode SVM
from sklearn.svm import SVC
classifierSVM = SVC(kernel = 'linear', random_state = 0)
classifierSVM.fit(X_train, y_train)
# Metode Naive Bayes
from sklearn.naive_bayes import GaussianNB
classifierNB = GaussianNB()
classifierNB.fit(X_train, y_train)
# Metode Decision Tree
from sklearn.tree import DecisionTreeClassifier
classifierDT = DecisionTreeClassifier(criterion = 'entropy', random_state = 0)
classifierDT.fit(X_train, y_train)
# Metode Random Forest
from sklearn.ensemble import RandomForestClassifier
classifierRF = RandomForestClassifier(n_estimators = 500, criterion = 'entropy', random_state = 0)
classifierRF.fit(X_train, y_train)
# Memprediksi hasil Test Set
y_pred_LR = classifierLR.predict(X_test) # logistic Regression
y_pred_KNN = classifierKNN.predict(X_test) # K-nearest Neighbors
y_pred_SVM = classifierSVM.predict(X_test) # SVM
y_pred_NB = classifierNB.predict(X_test) # Naive Bayes
y_pred_DT = classifierDT.predict(X_test) # Decision Tree
y_pred_RF = classifierRF.predict(X_test) # Random Forest
# Membuat Confusion Matrix
from sklearn.metrics import confusion_matrix
cm_LR = confusion_matrix(y_test, y_pred_LR)
cm_KNN = confusion_matrix(y_test, y_pred_KNN)
cm_SVM = confusion_matrix(y_test, y_pred_SVM)
cm_NB = confusion_matrix(y_test, y_pred_NB)
cm_DT = confusion_matrix(y_test, y_pred_DT)
cm_RF = confusion_matrix(y_test, y_pred_RF)
# Menilai akurasi masing-masing metode
akurasi_LR = ((cm_LR[0][0]+cm_LR[1][1])/(cm_LR[0][0]+cm_LR[1][1]+cm_LR[0][1]+cm_LR[1][0]))*100
akurasi_KNN = ((cm_KNN[0][0]+cm_KNN[1][1])/(cm_KNN[0][0]+cm_KNN[1][1]+cm_KNN[0][1]+cm_KNN[1][0]))*100
akurasi_SVM = ((cm_SVM[0][0]+cm_SVM[1][1])/(cm_SVM[0][0]+cm_SVM[1][1]+cm_SVM[0][1]+cm_SVM[1][0]))*100
akurasi_NB = ((cm_NB[0][0]+cm_NB[1][1])/(cm_NB[0][0]+cm_NB[1][1]+cm_NB[0][1]+cm_NB[1][0]))*100
akurasi_DT = ((cm_DT[0][0]+cm_DT[1][1])/(cm_DT[0][0]+cm_DT[1][1]+cm_DT[0][1]+cm_DT[1][0]))*100
akurasi_RF = ((cm_RF[0][0]+cm_RF[1][1])/(cm_RF[0][0]+cm_RF[1][1]+cm_RF[0][1]+cm_RF[1][0]))*100
Penjelasan:
- Line 2-5 mengimpor library yang diperlukan.
- Line 7 mengimpor datasetnya. Kita masih menggunakan perintah pd.read_csv, namun kali ini kita pakai delimiter=’\t’ agar memisahkan data berdasarkan tab (menggunakan format tsv). Kemudian kita buat parameter quoting=3 agar tidak mengikutkan kuotasi (“”). Untuk melihat parameter read_csv, arahkan kursor di read_csv kemudian ketik CTRL+i di keyboard, maka tampilannya sebagai berikut:

Sekarang coba klik 2x pada dataset di Variable explorer di spyder. Tampilannya tampak sebagai berikut:
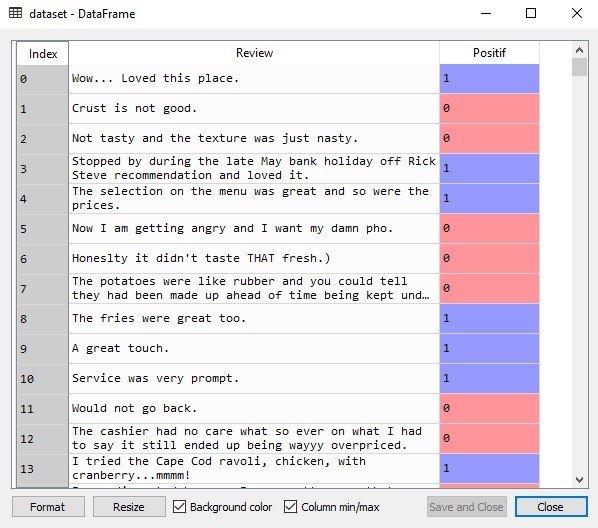
Bisa dilihat bahwa kolom pertama (yaitu Review) berisi komentar para pelanggan. Sementara kolom selanjutnya (yaitu Positif) berisi angka 0/1 (0 artinya negatif-komentar jelek, dan 1 artinya positif-komentar baik).
- Line 9 adalah keterangan bahwa line 10-34 adalah beberapa perintah untuk melakukan proses Bag of Words setahap demi setahap agar pembaca bisa memahaminya dengan baik.
- Line 11 melihat komentar pertama, dengan melihat kolom ‘Review’ , kemudian diikuti [0] yang artinya melihat item pertama (indeks python dimulai dari nol).
- Line 14 mengimpor library re yang merupakan regular expression. Info lengkap tentang regular expression bisa diklik di link ini. Library ini digunakan untuk melakukan cleaning pada teks. Tips: arahkan kursor pada perintah re lalu ketik CTRL+i pada keyboard, maka parameter yang diperlukan adalah sebagai berikut:
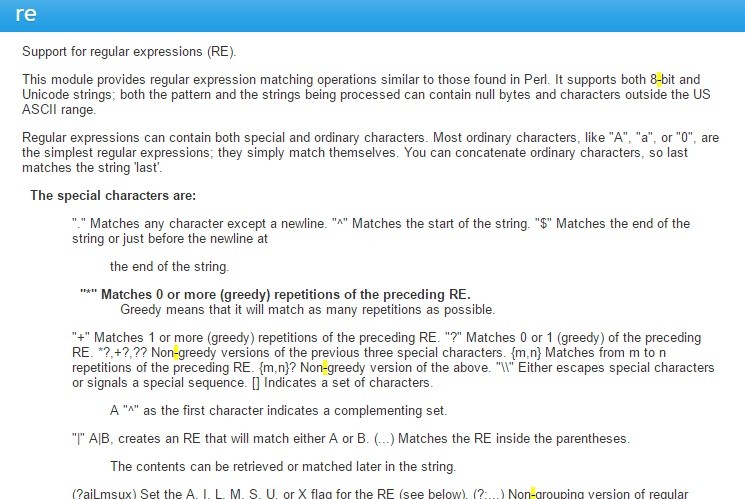
- Line 15 mengimpor library NLTK. Ini adalah library untuk membersihkan teks (cleaning).
- Line 16 mendefinisikan variabel review dengan menggunakan perintah re dan metode sub (ditulis re.sub).
Kita ingin melakukan proses cleaning. Maksudnya adalah kita membuang karakter yang tidak relevan, misalnya titik, articles (a/an/the) dan sebagainya. Sehingga nanti yang tersisa hanya yang relevan saja misalnya kata like yang artinya review positif, atau kata angry yang artinya review negatif. Selain itu kata yang sama misal loved, love dan loving akan menjadi satu kata saja. Proses cleaning ini disebut dengan stemming.
Untuk diperhatikan, dari line 9-37 adalah untuk mengolah 1 komentar saja, yaitu ‘Wow… Loved this place.’. Saya akan menunjukkan tahap demi tahap proses cleaning-nya.
Berikut tampilan komentar pertama sebelum proses cleaning.

Perintah yang digunakan untuk re.sub adalah '[^a-zA-Z]', ' ', dataset['Review'][0]
Arti dari perintah di atas adalah:
- Kita tidak membuang komentar yang dimulai dari huruf a hingga z, begitu juga dari A-Z (untuk kapital). Untuk memilih agar tidak dibuang, maka kita tambahkan tanda topi (^) di depannya.
- Setelah itu diikuti dengan koma dan spasi yang diapit oleh petik 1 (‘ ‘). Artinya setiap huruf selain a-zA-Z maka diganti (ditukar) dengan spasi kosong.
- Diikuti dengan koma dan kita jelaskan data mana yang mau diolah. Dalam hal ini adalah kolom Review dari dataset, dan item pertama.
Jika sudah dieksekusi, maka di Variable explorer spyder akan tampak 2 data sebagai berikut:

Terlihat pada gambar di atas pada variabel ‘review’ hanya memiliki satu item, yaitu ‘Wow Loved this place’.
- Line 17 mengolah lagi variabel review sehingga semua huruf kapital menjadi huruf kecil. Dengan demikian, tampilan di Variable explorer menjadi seperti ini:

Tampilan Variable explorer setelah merubah kapital menjadi huruf kecil
- Line 18 mengolah lagi variabel review sehingga setiap kata terpisah dari kata yang lain. Dengan demikian, variabel ‘review’ akan menjadi sebuah list yang memiliki item berupa kata yang dipisah-pisah tadi. Tampilannya menjadi sebagai berikut:

- Line 21 mendownload ‘stopwords’ dari package nltk. Stopwords adalah istilah lain untuk vocabulary. Di dalamnya adalah kata-kata yang dikenal dalam sebuah bahasa. Intinya kita nanti akan mengeluarkan kata-kata yang termasuk di dalam stopwords.
- Line 22 mengaktifkan stopwords yang sudah didownload di line 21.
- Line 25 mendefinisikan variabel inggris untuk melihat vocabulary yang sudah ada di nltk. Kurang lebih ada 179 kosakata yang ada. Di dalamnya termasuk artikel seperti ‘a’, ‘an’, dan ‘the’, termasuk juga determiner seperti ‘this’, ‘that’ dan lain-lain. Tampilannya sebagai berikut:
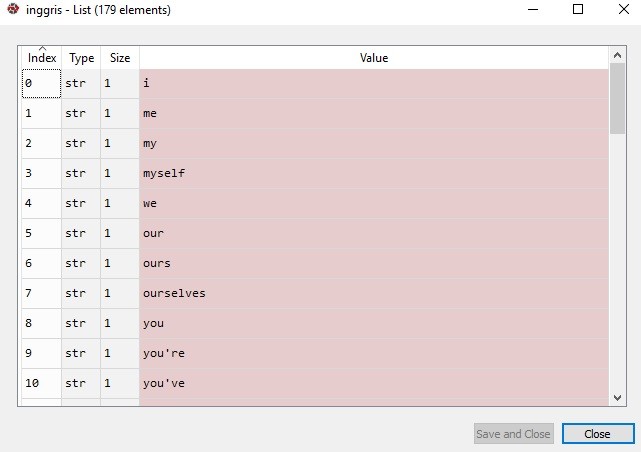
- Line 26 mendefinisikan variabel indo untuk melihat vocabulary yang sudah ada di nltk. Kurang lebih ada 758 kosakata yang ada. Tampilannya sebagai berikut:
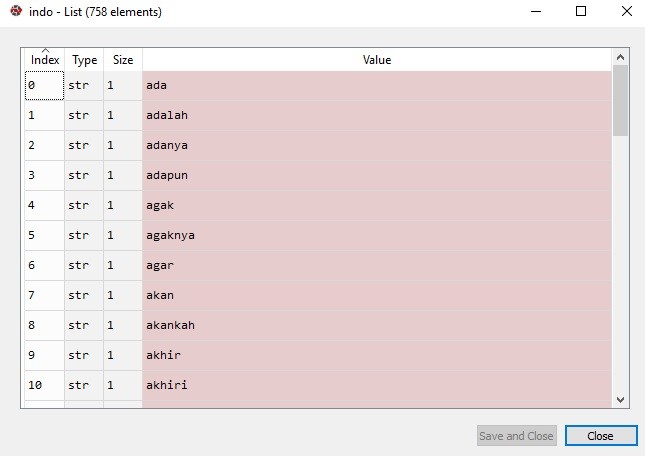
- Line 29 adalah mengaplikasikan fungsi stopwords. Kita akan meng-exclude (mengeluarkan) kata-kata yang termasuk di dalam stopwords.
review = [word for word in review if not word in inggris]
Cara membaca perintah di atas adalah sebagai berikut:
review = [word
for word in review
if not word in inggris]
- Kita mendefinisikan variabel review, dengan menuliskan review =
- Kita mengisi variabel ini berupa variabel lain yaitu word. Apa itu word? Dijelaskan di bawahnya.
- Perintah for word in review adalah sebuah looping iterasi. Artinya dia akan melakukan iterasi dari semua item (dalam hal ini dipilih kata word) yang ada di list review.
- Ini adalah lanjutan dari argumen di atasnya. Hanya memilih setiap item di review jika ia tidak termasuk di dalam variabel inggris yang kita definisikan di line 25.
- Buka dan akhiri perintah review dengan brackets (kurung kotak buka dan tutup) karena kita melakukan proses seleksi item dari sebuah list.
Jika dieksekusi, hasilnya adalah sebagai berikut:
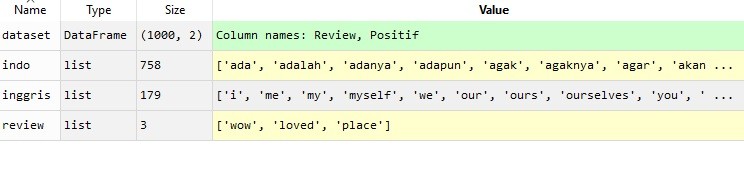
Dapat dilihat sekarang variabel ‘review’ tidak memasukkan kata ‘this’ karena ia termasuk ke dalam variabel inggris (stopwords versi bahasa inggris) yang kita definisikan di line 25.
Langkah selanjutnya penting untuk bisa mengetahui kata dasar dari sebuah kata. Misal kalau dalam bahasa inggris, maka kata ‘need’ dan ‘needed’ sebenarnya berasal dari satu kata dasar yaitu ‘need’, sehingga melalui proses stemming di dalam NTLK hanya akan terdeteksi sebanyak 1 kata.
Untuk bahasa Indonesia juga sama. Kata ‘melakukan’, ‘lakukan’, ‘dilakukan’, ‘perilaku’, sebenarnya berasal dari satu kata dasar yaitu ‘laku’. Melalui proses stemming (artinya: pengakaran), semuanya akan dianggap satu kata.
- Line 32 mengimpor PorterStemmer untuk melakukan proses stemming.
- Line 33 mendefinisikan variabel ps untuk mengaktifkan PorterStemmer yang sudah diimpor di line 30.
Perlu diperhatikan bahwa PorterStemmer adalah proses untuk kata dasar berbahasa inggris. Untuk bahasa Indonesia akan saya jelaskan di bagian akhir pembahasan Python nanti.
- Line 36 adalah perintah yang mirip dengan line 29 hanya saja kita tambahkan ps (PorterStemmer). Hasilnya sebagai berikut:
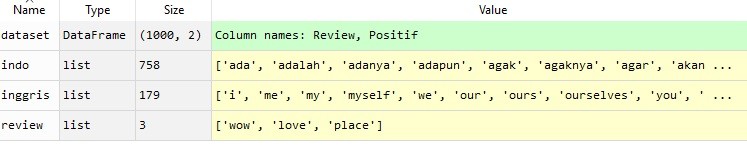
Bisa dilihat bahwa kata ‘loved’ berubah menjadi ‘love’ karena proses PorterStemmer.
- Line 37 menggabungkan item di dalam list menjadi satu kesatuan dalam format string. Hasilnya tampak sebagai berikut:

Bisa dilihat dari 3 item sebuah list (‘wow’, ‘love’, ‘place’) digabungkan menjadi satu kesatuan dengan format string (‘wow love place).
Sampai line 38 saya harap pembaca bisa memahami bagaimana memproses satu komentar melalui package NLTK.
- Line 40-53 adalah mengulangi perintah-perintah sebelumnya di line 10-37. Namun kali ini kita tidak melakukan hanya untuk 1 item saja, melainkan semua item yang ada di dataset.
- Line 45 kita definisikan sebuah list kosong bernama corpus. Corpus ini akan berisikan semua item yang terdeteksi oleh NLTK yang sudha melalui seleksi stopwords dan stemming.
- Line 46 adalah perintah looping untuk melakukan iterasi semua item di dataset. Kita menggunakan indeks i sebagai iteratornya. Indeks i ini juga kita gunakan di line 47.
- Line 53 adalah perintah untuk memasukkan setiap item yang melewati seleksi stopwords dan stemming ke dalam list corpus. Caranya adalah dengan metode append.
Jika dieksekusi, maka perbandingan antara dataset dan corpus adalah sebagai berikut:
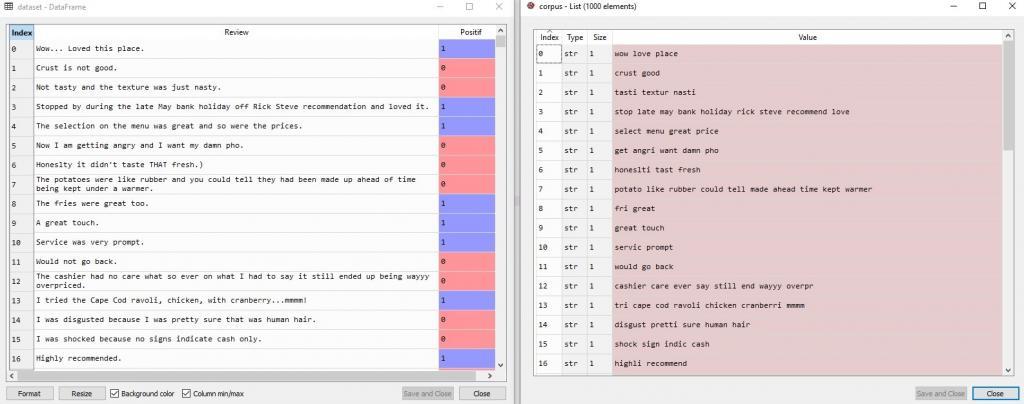
Masing-masing kolom adalah kalimat dengan format string yang sudah melalui seleksi stopwords dan stemming.
Setelah ini kita akan membuat matrix (atau matriks) untuk setiap kemunculan kata di tiap komentar. Kita akan banyak mendapatkan sparse matrix, yaitu matriks yang kebanyakan berisi angka nol. Saya akan menjelaskannya melalui sebuah tabel berikut:

Tabel di atas terdiri dari beberapa kolom dan baris. Masing-masing kolom berisi kata dari sebuah kata dari semua komentar, di mana kata ini tidak ada yang sama. Kolom pertama adalah ‘wow’, kemudian ‘love’ dan seterusnya. Sementara baris berisi dengan jumlah komentar, dalam hal ini ada 1000 baris.
Jika kata ‘wow’ muncul di komentar ‘wow love place’ maka ia memiliki skor 1. Jika kita lihat kolom ‘wow’ untuk baris kedua, maka nilainya 0, karena kata ‘wow’ tidak muncul di komentar ‘crust good’. Begitu seterusnya sampai kita bisa memasukkan semua baris dan kolom yang tentunya tabel ini akan berukuran besar sekali. Tabel yang kita buat ini sebenarnya adalah sebuah sparse matrix (matriks yang memiliki banyak nilai nol). Proses membuat matriks ini dalam NLP disebut dengan istilah tokenization (tokenisasi).
Membuat satu persatu (satu kolom satu kata, hingga semua kata untuk semua komentar) tentunya sangat melelahkan jika dilakukan secara manual. Namun dengan Python dan R semuanya menjadi mudah.
- Line 56 mengimpor CountVectorizer dari sklearn.feature_extraction.text untuk membuat model bag of words.
- Line 57 mendefinisikan variabel cv untuk mengaktifkan CountVectorizer. Untuk melihat parameter apa saja yang diperlukan arahkan kursor pada CountVectorizer lalu ketik CTRL+i pada keyboard.
- Line 58 mendefinisikan variabel independen X kita dengan melakukan proses cv dan fit_transform variabel corpus yang sudah kita buat. Metode .toarray() adalah untuk menjadikan variabel X yang sebelumnya adalah matriks dari corpus menjadi sebuah array.
Sekarang mari kita lihat variabel X yang sudah kita definisikan. Tampilannya adalah sebagai berikut:
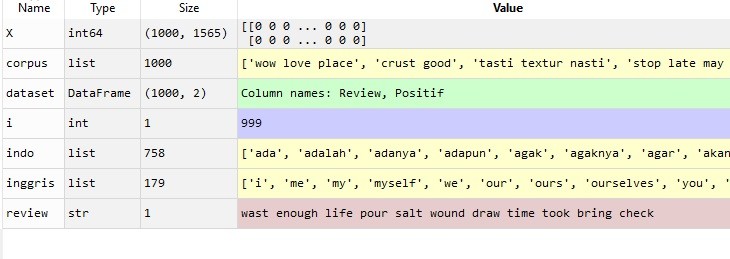
Variabel X memiliki 1000 baris (1000 komentar) dan 1565 kolom (1565 kata). Ternyata setelah melalui proses seleksi stopwords dan stemming, kata yang tersisa melebihi jumlah komentarnya, banyak juga.
Walau demikian, untuk aplikasi lain misal web analysis, jumlah kolomnya bisa mencapai ratusan ribu bahkan jutaan. Butuh komputer yang sangat powerful untuk mengolah datanya.
Jika kita memiliki jumlah kata yang banyak, bisa disiasati dengan parameter CountVectorizer(max_features=x), di mana nilai x adalah jumlah kolom yang diinginkan. Dengan demikian, maka yang ditampilkan adalah kata-kata yang paling banyak muncul, sehingga perhitungan juga semakin cepat.
- Line 59 mendefinisikan variabel dependen, dengan memilih semua baris dan hanya kolom kedua saja (apakah ia masuk ke komentar positif atau negatif).
Di pembahasan kali ini kita ingin memprediksi apakah kata-kata di model bag of words yang sudah kita buat sebelumnya, bisa memprediksi apakah ia masuk ke komentar positif atau negatif. Untuk memperjelasnya lagi, mari kita lihat variabel independen (X) dan dependen (y) nya.
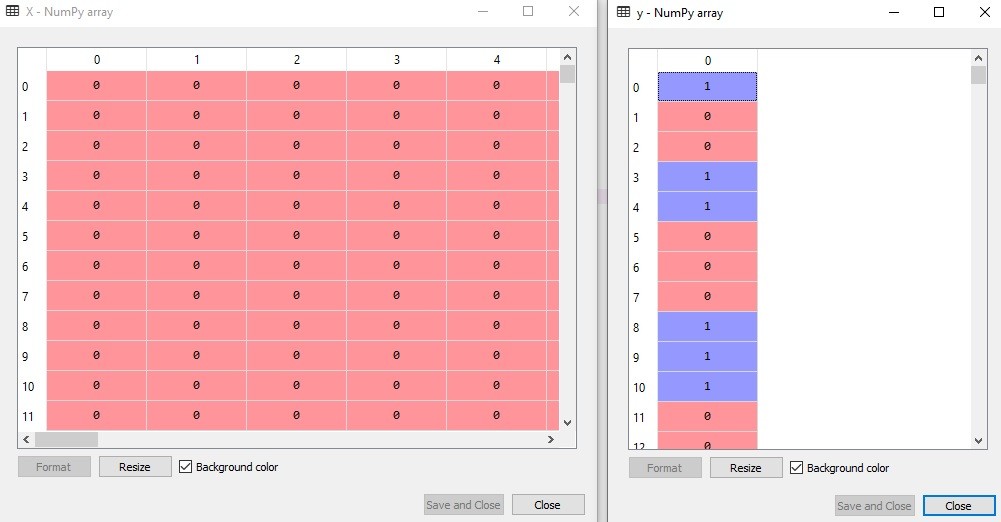
Di sebelah kiri kita memiliki variabel independen X, di mana setiap baris adalah komentar, dan setiap kolom mewakili satu kata (tidak ada kata yang muncul 2x). Jika kata itu muncul di komentar maka ia bernilai satu, jika tidak ia bernilai nol.
Di sebelah kanan kita memiliki variabel dependen y. Intinya adalah kita ingin melatih agar mesin bisa mencari hubungan antara kata-kata di dalam komentar dengan responnya apakah ia termasuk kata yang bermakna positif atau negatif.
Jika sudah dilatih, kita akan menggunakan model latihan ini untuk memprediksi nilai y_test dengan menggunakan X_test. Hasil prediksi kita sebut y_pred. Nantinya y_pred akan kita bandingkan dengan y_test yang sesungguhnya. Jika sangat mirip, maka ditunjukkan dengan nilai akurasi tinggi. Sebaliknya jika tidak mirip, akurasinya rendah.
- Line 62-63 membagi data ke dalam training set dan test set.
- Line 67-94 adalah teknik klasifikasi untuk masing-masing metode. Kita menggunakan logistic regression, K-nearest Neighbors, SVM, Naive Bayes, Decision Tree, dan Random Forest. Semua algoritmanya sudah saya jelaskan di bab-nya masing-masing. Pembaca hanya cukup copy-paste saja scriptnya.
- Line 97-102 kita memprediksi test set dari masing-masing model klasifikasi yang kita lakukan di line 67-94. Masing-masing model memiliki nama yang berbeda.
- Line 105-111 kita membuat confusion matrixnya sehingga kita bisa bandingkan akurasinya nanti.
- Line 114-119 menghitung akurasi dari masing-masing metode.
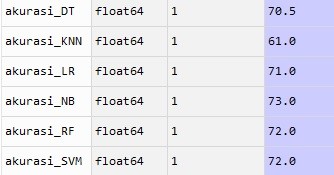
Kita bisa melihat bahwa metode Naive Bayes adalah metode yang memiiki akurasi yang paling tinggi. Namun perlu diperhatikan bahwa bukan perbandingan akurasi tujuan kita, namun model bag of words kita mampu memprediksi review positif/negatif berdasarkan kata-kata yang ia (model) tangkap.
Untuk tambahan bahwa metode Naive Bayes adalah metode klasifikasi yang paling banyak dipakai untuk analisis NLP (Natural Language Processing).
Setiap algoritma klasifikasi di atas masih bisa ditingkatkan akurasinya. Silakan pembaca bermain-main (memodifikasi) parameter dari masing-masing algoritmanya.
Apakah bag of words hanya untuk mereview komentar saja? Tentu tidak. Contoh di atas hanya menunjukkan cara kerjanya saja. Tentu bisa digunakan untuk banyak hal. Misal untuk analisis konten berita, sosial media, dan masih banyak lagi. Hanya tinggal gunakan intuisi pembaca untuk sedikit memodif script di atas.
PROSES STEMMING UNTUK BAHASA INDONESIA
Sesuai janji saya di atas, saya akan berikan cara melakukan proses stemming (penggunaan kata dasar) untuk bahasa Indonesia. Sehingga pembaca bisa menganalisis semua tulisan berbahasa Indonesia. Kita akan gunakan stemmer yang sering dipakai yang disebut dengan Sastrawi.
from Sastrawi.Stemmer.StemmerFactory import StemmerFactory psi = StemmerFactory() stemmer = psi.create_stemmer()
Kalau di script utuh di atas kita gunakan variabel ps untuk PorterStemmer, untuk bahasa Indonesia kita gunakan variabel stemmer.
Untuk melanjutkan membaca dan belajar penggunaan NLP menggunakan bahasa R, silakan klik lanjut ke halaman selanjutnya di bawah ini.
Selamat pagi.
Gini mas, saya sedang mencoba menjalankan tutorial ini menggunakan jupyter notebook python. nah sekarag saya mau liat autput dari aplikasi ini apa yah? dan yg bahasa R itu gk kaitannya dgn source pytonnya? Terima kasih sebelumnya.
Halo Alexander, terima kasih komentarnya.
Aplikasi NLP banyak sekali, salah satu yang saya bahas adalah sentiment analysis.
Untuk output dan source code nya bisa dibaca di halaman selanjutnya (total ada 4 halaman).
Semoga membantu
Selamat malam.
kalau mau menambahkan Pembobotan TF-IDF, seperti gimana ya? trimakasih
Halo, TF adalah term frequency yang merupakan frekuensi kemunculan sebuah kata tertentu. Misal kita ingin mencari kata ‘makan’ di dalam sebuah dokumen dengan total 1000 kata, di mana kata ‘makan’ muncul 50 kali, maka TF = 50/1000 = 0,05. IDF adalah inverse document frequency, yang merupakan frekuensi kemunculan kata dalam a bank of words (kumpulan beberapa dokumen) dalam skala logaritmik. Misal kata ‘makan’ muncul 100 kali dari 10rb dokumen, maka TDF = log(10000/100) = 2. TF-IDF adalah perkalian antara TF dan IDF = 0,05 * 2 = 0,1 Untuk menghitung keduanya di Python maupun R, cukup pakai operasi matematika sederhana.… Read more »
jadi kalo saya mengganti line 57 dengan
“cv =TfidfVectorizer (analyzer=’word’,
ngram_range=(1, 1),
min_df=1,
max_df=0.95,
sublinear_tf=True,
use_idf=True)”
apakah itu sudah menggunakan tf-idf?
Saya belum pernah mencoba fungsi bawaan itu.
Silakan dicoba sendiri dan bandingkan hasilnya, apakah sesuai dengan tujuan awal.
Semoga menjawab.
Permisi Pak, salam hangat dari saya boleh saya minta tolong jika berkenan di jelaskan mengenai NLP dalam teknologi Chatbot secara detail mulai dari konsep, teori dan studi kasusnya. soalnya saya masih belum memahami
terima kasih
sukses selalu
Panjang ini penjelasannya seperti materi kuliah.
Nanti ya kapan-kapan saya bahas, ini sedang menyelesaikan keperluan S3 dulu.
Harap bersabar.
Halo Pak
Sebelumnya saya sedang mempelajari face detection menggunakan opencv di spyder, namun saya melihat byk contoh program yang menggunakan library argparse, kira-kira plus minus nya apa yah pak? saya coba jalankan program sederhana menggunakan argparse di spyder tapi hasil outputnya tidak ada? apakah ada alternatif lain pak?
Terima kasih
Salam
Selamat pagi
selamat pagi maaf mas mohon petujuknya saya sedang menggunkan jupyter notebook tolong pada saat kita Run muncul error seperti ini : SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape dan AttributeError: module ‘pandas’ has no attribute ‘read_cs’ tolong penjelasanya..
read_csv bukan read_cs
Hallo mas, kalo untuk yang stemming bahasa indonesia yang diubah itu di line berapa ya?
terimakasih pak, ini dapat membantu saya untuk mengerjakan skripsi untuk sentimen rewnable energi, boleh konsul secara pribadi ga pak untuk sripsi saya?
Bisa ikut member platinum via channel Youtube saya.