

Bahasa R
# Mengimpor dataset
dataset = read.delim('Review_restoran.tsv', quote = '', stringsAsFactors = FALSE)
# Melakukan proses cleaning pada teks
install.packages('tm')
library(tm)
corpus = VCorpus(VectorSource(dataset$Review))
corpus = tm_map(corpus, content_transformer(tolower))
corpus = tm_map(corpus, removeNumbers)
corpus = tm_map(corpus, removePunctuation)
corpus = tm_map(corpus, removeWords, stopwords())
install.packages('SnowballC')
library(SnowballC)
corpus = tm_map(corpus, stemDocument)
corpus = tm_map(corpus, stripWhitespace)
# Creating the Bag of Words model
dtm = DocumentTermMatrix(corpus)
dtm = removeSparseTerms(dtm, 0.999)
dataset2 = as.data.frame(as.matrix(dtm))
dataset2$Positif = dataset$Positif
# Encoding the target feature as factor
dataset2$Positif = factor(dataset2$Positif, levels = c(0, 1))
# Splitting the dataset into the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset2$Positif, SplitRatio = 0.8)
training_set = subset(dataset2, split == TRUE)
test_set = subset(dataset2, split == FALSE)
# Fitting Random Forest Classification to the Training set
# install.packages('randomForest')
library(randomForest)
classifier = randomForest(x = training_set[-692],
y = training_set$Positif,
ntree = 10)
# Predicting the Test set results
y_pred = predict(classifier, newdata = test_set[-692])
# Making the Confusion Matrix
cm = table(test_set[, 692], y_pred)
Penjelasan:
- Line 2 mengimpor datasetnya. Karena datasetnya berformat tsv (tab separated values) maka kita gunakan perintah read.delim. Selain itu kita juga gunakan parameter quote=” artinya kita menghilangkan tanda petik yang terdeteksi. Kita juga menggunakan parameter stringsAsFactors yang artinya karakter berformat string tetaplah bersifat string dan jangan berubah menjadi factor (kategori).
Tampilan datasetnya tampak sebagai berikut:
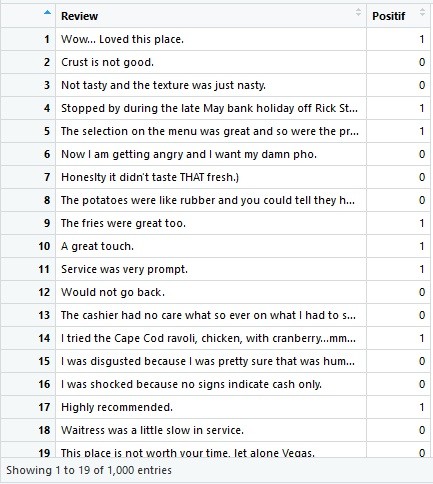
Setelah ini kita ingin melakukan proses cleaning. Maksudnya adalah kita membuang karakter yang tidak relevan, misalnya titik, articles (a/an/the) dan sebagainya. Sehingga nanti yang tersisa hanya yang relevan saja misalnya kata like yang artinya review positif, atau kata angry yang artinya review negatif. Selain itu kata yang sama misal loved, love dan loving akan menjadi satu kata saja. Proses cleaning ini disebut dengan stemming.
- Line 5 menginstall package tm. Package ini adalah package khusus untuk teknik NLP di R.
- Line 6 mengaktifkan library tm.
- Line 7 mendefinisikan variabel corpus. Kemudian menggunakan perintah VCorpus yang artinya Volatile Corpus yaitu membaca corpus yang bersifat tidak permanen (kebalikan dari Permanent Corpus). Kemudian agar bisa membaca, VCorpus harus membaca file berupa vektor (vectors). Oleh karena itu kita gunakan perintah VectorSource. Data yang dibaca adalah kolom Review pada dataset.
- Line 8 mengolah kembali variabel corpus. Kali ini semua huruf kapital kita ubah menjadi huruf kecil. Perintah yang digunakan adalah
content_transformer(tolower). - Line 9 adalah perintah menghilangkan angka (dalam hal ini kita tidak perlu angka, karena kita menganalisis komentar.
- Line 10 menghilangkan tanda baca seperti titik, koma, dan lain-lain.
- Line 11 membuang kata yang tidak relevan seperti artikel ‘a’, ‘an’, dan ‘the’ dalam bahasa inggris. Begitu pula dengan kata ‘this’, ‘that’, dan sejenisnya. Untuk bisa melakukannya gunakan perintah
removeWords, stopwords().
Untuk bahasa Indonesia kita bisa menggunakan library UDPipe. Bisa di download dulu dengan cara:
install.packages('udpipe')
library(udpipe)
- Line 12 menginstall library SnowballC yang diperlukan untuk proses stemming (pemakaian kata dasar).
Untuk proses stemming kalimat yang berbahasa Indonesia, gunakan library udpipe dengan merujuk pada halaman berikut dan ini. Untuk bahasa Indonesia akan saya kupas lebih detail di pembahasan lainnya.
- Line 13 mengaktifkan library SnowballC.
- Line 14 melakukan proses stemming, yaitu mencari kata dasarnya, sehingga kata loved, loving, dan love memiliki kata dasar yang sama yaitu love.
- Line 15 menghilangkan spasi berlebih, sehingga setiap kata dipisahkan oleh satu spasi saja.
- Line 18 mendefinisikan variabel dtm yang merupakan singkatan dari DocumentTermMatrix. Untuk membuat model bag of words kita memerlukan matriks. Dengan perintah DocumentTermMatrix maka tabel corpus (format data frame) akan berubah menjadi matriks.
- Line 19 mengolah lagi variabel dtm. Kali ini kita gunakan perintah removeSparseTerms untuk membuang kata-kata yang kemunculannya hanya sekali. Mengapa ini penting? Pertama kita cek dulu dtm. Ketikkan saja dtm di console Rstudio, maka tampak sebagai berikut:
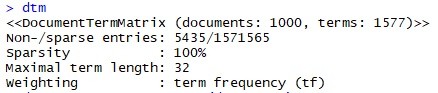
dtm adalah sebuah sparse matrix, yaitu sebuah matriks yang memiliki banyak nilai nolnya. Karena tidak setiap kata (misal: delicious) muncul di setiap komentar. Kita juga bisa lihat bahwa Sparsity nya masih 100% (artinya masih 100% data utuh), karena belum kita seleksi.
Kita juga bisa melihat bahwa di gambar atas kita memiliki 1000 baris dan 1577 kolom. Artinya kita memiliki 1000 komentar dan 1577 kata yang diekstrak dari semua komentar ini, dan tidak ada satupun kata yang sama.
Agar memahami seperti apa bentuk matriks yang kita buat, saya buat ilustrasinya ke dalam tabel berikut ini:

Sekarang kita akan menyeleksi datanya sehingga kata-kata yang tidak sering muncul kita buang saja. Mengapa harus dibuang? Sebenarnya tidak harus, karena data kita belum cukup besar (hanya 1000 komentar dan 1577 kata kali ini). Namun saya memberikan gambaran ke pembaca jika kita memiliki data puluhan ribu, hingga jutaan, maka dnegan mengurangi kata yang tidak relevan akan sangat membantu.
- Line 19 mengurangi 0.001% data yang ada dengan perintah
removeSparseTerms(dtm, 0.999). Jika kita cek lagi dtm di console maka tampak sebagai berikut:
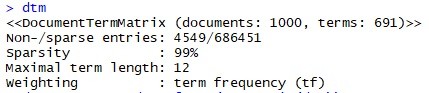
Sekarang kita hanya memiliki 691 kata, dari yang sebelumnya 1577 kata. Sparsity juga menunjukkan kita mengurangi sparsity dari 100% menjadi 99%.
- LIne 20 mendefinisikan dataset2 sebagai variabel yang merupakan perubahan dari dtm (dengan format matriks) menjadi format data frame. Mengapa diberi nama dataframe2? Agar tidak sama dengan nama dataset yang sudah kita definisikan di line 2.
- Line 21 mendefinisikan variabel dataset2$Positif (dibaca variabel dataset2 pada kolom bernama Positif) dari variabel dataset kolom Positif. Ini adalah langkah mendefinisikan variabel dependen (y) nya.
- Line 24 memastikan bahwa variabel dependen kita adalah format kategori (factor) caranya dengan men settingnya sebagai factor dengan level 0 dan 1.
Line 26-45 sama dengan pembahasan di bab klasifikasi sebelumnya. Kita cukup memodifikasinya sedikit saja, seperti menyesuaikan nama variabelnya, urutan kolomnya dan sebagainya.
Metode yang digunakan di R kali ini adalah random forest. Saya hanya memilih acak saja. Pembaca bisa mencobanya dengan menggunakan metode lain misal Naive Bayes, SVM, dan lain-lain.
- Line 27-32 adalah membagi data ke dalam training dan test set.
- Line 35-39 adalah teknik klasifikasi random forest.
- Line 42 memprediksi test set dari data training set yang kita definisikan di line 31.
- Line 45 membuat confusion matrix. Jika diketik cm di console, maka tampilannya sebagai berikut:
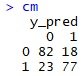
Ternyata model NLP kita cukup baik memprediksi test set dengan akurasi 79.5%. Cara perhitungan akurasi adalah (82+77)/200 = 0.795.
Dengan demikian kita bisa katakan bahwa model kita bisa memprediksi sebuah kata yang muncul di setiap komentar restoran, apakah ia bermakna positif atau negatif. Ke depannya pemilik restoran akan bisa menggunakan model ini untuk mengembangkan pelayanan restorannya ke pelanggan, dan tentunya mempermudah proses evaluasi kinerja usahanya ke depan.
Penting untuk diketahui bahwa teknik bag of words tidak hanya digunakan untuk mereview komentar saja. Yang kita bahas di atas hanya menunjukkan cara kerjanya saja. Tentu bisa digunakan untuk banyak hal. Misal untuk analisis konten berita, sosial media, dan masih banyak lagi. Hanya tinggal gunakan intuisi pembaca untuk sedikit memodifikasi script di atas.
Saya harap sampai di sini pembaca bisa mengerti konsep dari NLP (Natural Language Processing). Aplikasinya sangat luas! Asal pembaca bisa mengetahui konsepnya dan bisa menggunakan library yang ada di Python dan R, maka pembaca bisa menganalisis semua data tulisan yang ada di luar sana!
Terima kasih sudah belajar NLP bersama saya.
Terus kunjungi web saya untuk belajar teknik dan aplikasi AI lainnya.
Semoga bermanfaat.
Selamat pagi.
Gini mas, saya sedang mencoba menjalankan tutorial ini menggunakan jupyter notebook python. nah sekarag saya mau liat autput dari aplikasi ini apa yah? dan yg bahasa R itu gk kaitannya dgn source pytonnya? Terima kasih sebelumnya.
Halo Alexander, terima kasih komentarnya.
Aplikasi NLP banyak sekali, salah satu yang saya bahas adalah sentiment analysis.
Untuk output dan source code nya bisa dibaca di halaman selanjutnya (total ada 4 halaman).
Semoga membantu
Selamat malam.
kalau mau menambahkan Pembobotan TF-IDF, seperti gimana ya? trimakasih
Halo, TF adalah term frequency yang merupakan frekuensi kemunculan sebuah kata tertentu. Misal kita ingin mencari kata ‘makan’ di dalam sebuah dokumen dengan total 1000 kata, di mana kata ‘makan’ muncul 50 kali, maka TF = 50/1000 = 0,05. IDF adalah inverse document frequency, yang merupakan frekuensi kemunculan kata dalam a bank of words (kumpulan beberapa dokumen) dalam skala logaritmik. Misal kata ‘makan’ muncul 100 kali dari 10rb dokumen, maka TDF = log(10000/100) = 2. TF-IDF adalah perkalian antara TF dan IDF = 0,05 * 2 = 0,1 Untuk menghitung keduanya di Python maupun R, cukup pakai operasi matematika sederhana.… Read more »
jadi kalo saya mengganti line 57 dengan
“cv =TfidfVectorizer (analyzer=’word’,
ngram_range=(1, 1),
min_df=1,
max_df=0.95,
sublinear_tf=True,
use_idf=True)”
apakah itu sudah menggunakan tf-idf?
Saya belum pernah mencoba fungsi bawaan itu.
Silakan dicoba sendiri dan bandingkan hasilnya, apakah sesuai dengan tujuan awal.
Semoga menjawab.
Permisi Pak, salam hangat dari saya boleh saya minta tolong jika berkenan di jelaskan mengenai NLP dalam teknologi Chatbot secara detail mulai dari konsep, teori dan studi kasusnya. soalnya saya masih belum memahami
terima kasih
sukses selalu
Panjang ini penjelasannya seperti materi kuliah.
Nanti ya kapan-kapan saya bahas, ini sedang menyelesaikan keperluan S3 dulu.
Harap bersabar.
Halo Pak
Sebelumnya saya sedang mempelajari face detection menggunakan opencv di spyder, namun saya melihat byk contoh program yang menggunakan library argparse, kira-kira plus minus nya apa yah pak? saya coba jalankan program sederhana menggunakan argparse di spyder tapi hasil outputnya tidak ada? apakah ada alternatif lain pak?
Terima kasih
Salam
Selamat pagi
selamat pagi maaf mas mohon petujuknya saya sedang menggunkan jupyter notebook tolong pada saat kita Run muncul error seperti ini : SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape dan AttributeError: module ‘pandas’ has no attribute ‘read_cs’ tolong penjelasanya..
read_csv bukan read_cs
Hallo mas, kalo untuk yang stemming bahasa indonesia yang diubah itu di line berapa ya?
terimakasih pak, ini dapat membantu saya untuk mengerjakan skripsi untuk sentimen rewnable energi, boleh konsul secara pribadi ga pak untuk sripsi saya?
Bisa ikut member platinum via channel Youtube saya.