

Sebelum melakukan sesuatu yang besar, ada baiknya kita harus melakukan persiapan terlebih dahulu. Semakin baik persiapannya, hasilnya juga akan semakin baik. Setidaknya hasil yang didapat tidak melenceng jauh dari tujuan awal. Oleh karena itu, untuk melakukan analisis sebuah data, atau dalam istilah lain disebut dengan istilah big data analysis, maka beberapa persiapan harus dilakukan. Dalam kaitan dengan pemrograman machine learning, maka persiapan ini juga adalah hal yang sebaiknya dilakukan. Persiapan ini saya namakan dengan istilah data preparation.
Beberapa alasan mengapa data preparation ini harus dilakukan:
- Data yang dimiliki tidak ideal, misal ada bagian data yang hilang (missing values)
- Format data tidak sama
- Datanya tidak cukup
- Variabel dependen dan variabel independen belum jelas
Semisal, kita memiliki data pelanggan dari beberapa negara (France, Spain, Germany), usia mereka, gaji mereka per tahun (dalam euro) dan keputusan membeli produk atau tidak:

Anggap data di atas adalah data apa adanya. Dapat dilihat pada kolom Usia dan Gaji, ada data yang hilang. Lalu apa langkah-langkah apa saja yang harus dilakukan?
- Langkah pertama adalah tentukan dulu apa tujuan yang diinginkan. Tujuan yang dimaksud adalah variabel dependen (dependent variable). Pada data di atas, kita ingin menentukan apakah seorang calon pelanggan akan memutuskan membeli produk atau tidak. Maka, kolom ‘Beli’ merupakan variabel dependennya.
- Langkah selanjutnya adalah menginput data ke Python atau R. Anda bisa mendownloadnya dengan klik link ini.
- Kemudian kita proses untuk data yang hilang dengan cara mencari nilai rataan data-data di sekitarnya sebagai pengisi data yang hilang dengan menggunakan Imputer (untuk python saja, R tidak perlu)
- Mendefinsikan data independen dan dependen variabel ke dalam program
Bahasa Python
Jika Anda belum mengerti sama sekali apa itu Python, silakan buka artikel saya ini.
Script python nya dapat dilihat sebagai berikut:
# Mengimpor library yang diperlukan
import numpy as np
import pandas as pd
# Import data ke python
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
# Memproses data yang hilang (missing)
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values= np.nan, strategy = 'mean')
imputer = imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
# Encoding data kategori dan variabel independen
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
labelencoder_X = LabelEncoder() # Bisa dihilangkan, baca pembahasan di bawahnya
X[:, 0] = labelencoder_X.fit_transform(X[:, 0]) # Bisa dihilangkan, baca pembahasan di bawahnya
transformer = ColumnTransformer(
[('Negara', OneHotEncoder(), [0])],
remainder='passthrough')
X = np.array(transformer.fit_transform(X), dtype=np.float)
# Encode variabel dependen
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
Penjelasan:
- Line 2 adalah proses import library numpy. Numpy adalah library python yang sangat populer untuk melakukan proses aritmatika. Karena ML (machine learning) selalu berhubungan dengan proses aritmatika, maka library ini akan selalu dipakai. Perintah import numpy as np, digunakan untuk mempermudah penulisan. Sehingga kelak, jika ingin memanggil numpy cukup menulis np saja.
- Line 3 adalah proses import library panda. Kita memberi perintah dengan menulis import panda as pd. Panda adalah library yang sangat populer untuk mengimpor dataset, dan memanage dataset. Untuk mempermudah penulisan, kita singkat sebagai pd.
- Sebelum mengimport dataset (Data.csv) yang sudah Anda download, pastikan folder di mana Anda menyimpan dataset ini sudah disetting sebagai working directory. Caranya mudah, cukup buka spyder, dan lihat icon bagian kanan atas, bentuknya seperti sebuah folder. Klik foder ini, kemudian pastikan Anda memilih folder di mana Anda menyimpat datasetnya. Jika berhasil, coba eksekusi line 6. Jika berhasil maka di bagian Variable explorer, Anda bisa melihat dataset Anda (double click untuk melihat isinya). Jika berhasil, tampilannya akan seperti ini

- Line 6 merupakan perintah untuk mengimpor variabel (Data.csv) dan mendefinisikannya sebagai dataset. Tentu nama variabelnya bebas, namun kali ini kita menamainya sebagai dataset.
Langkah selanjutnya adalah mendefinisikan mana variabel dependen dan independen. Karena kita ingin memprediksi keputusan apakah calon pelanggan akan membeli atau tidak, maka kolom ‘Beli’ akan menjadi variabel dependen. Keputusan ini ditentukan oleh 3 variabel independen, sehingga ketiga variabel ‘Negara’, ‘Usia’, dan ‘Gaji’ menjadi variabel independen.
- Line 7 dan 8 adalah perintah untuk menentukan X sebagai variabel dependen, dan Y sebagai variabel independen. Kita akan melakukan teknik slicing untuk memilih kolom yang tepat.
Langkah selanjutnya adalah mengatasi data yang hilang. Dalam dataset yang kita miliki pada kolom ‘Usia’ dan ‘Gaji’ ada baris yang kosong (nan). Bisa saja kita membuang baris yang memiliki data kosong, namun akan ada argumen muncul, bagaimana jika baris yang hilang sebenarnya memiliki data atau nilai yang sangat berguna? Maka, solusi bijaknya (dari berbagai sumber) adalah mengisinya dengan nilai rataan dalam satu kolom. Misal data hilang pada kolom ‘Usia’ diisi dengan rataan dari semua data pada kolom ‘Usia’.
- Line 11 mengimpor library scikit-learn dan menggunakan sublibrary impute dan menggunakan class SimpleImputer. Perlu diketahui bahwa library scikit-learn adalah library ML yang populer di python.
- Line 12 adalah menentukan parameter yang tepat. Tips: arahkan kursor pada Imputer lalu ketik bersamaan ‘CTRL+i’ maka akan memunculkan tampilan help. Di situ kita bisa melihat parameter apa saja yang diperlukan untuk mengeksekusi Imputer. Dalam pembelajaran kali ini kita memilih parameter missing_values diisi dengan np.nan karena dataset yang kosong merupakan nan dlam format numpy, strategy kita pilih mean (rataan) karena kita ingin mengisinya dengan nilai rata-rata. Kita mendefinisikan objeknya juga dengan nama imputer (huruf depan i kecil). Tentu saja pemilihan nama ini bebas.
- Line 13 adalah mempersiapkan pengisian baris yang hilang. Kita memilih metode fit (metode adalah syntax di belakang titik dari sebuah variabel atau argumen, misal imputer.fit. Perhatikan bahwa kolom yang ingin kita isi hanya ‘Usia’ dan ‘Gaji’, sehingga kita memilih kolom X index 1 dan 2 saja. Perhatikan penulisannya adalah menggunakan i kecil (imputer dan bukan Imputer. Imputer adalah perintah dari sklearn, namun imputer adalah nama variabel hasil Imputer).
- Line 14 adalah mengimplementasikan baris yang hilang. Kita lakukan dengan mendefinisikan baris dan kolom X, diisi dengan imputer.transform(X[:, 1:3]). Perhatikan bahwa X semua baris dan kolom 1 sampai 2, diisi oleh imputer X semua baris kolom 1 sampai 2 juga. Jika ingin melihat apakah proses ini berhasil, ketikkan X di bagian console. Hasilnya akan tampak seperti ini:
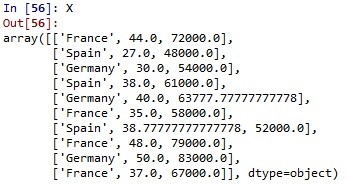
Kemudian, kita ingin melakukan proses encode untuk data kategori. Perlu diketahui, dataset yang kita miliki memiliki 2 kolom yang sifatnya kategori (categorical) yaitu kolom ‘Negara’ dan ‘Beli’. Kolom ‘Negara’ memiliki 3 kategori yaitu France, Spain dan Germany, sementara kolom ‘Beli’ memiliki 2 kategori yaitu Yes atau No.
Pertanyaannya, mengapa encoding kategori ini penting? Hal ini karena proses machine learning merupakan proses matematis, sehingga tidak mungkin data kategori diproses dengan cara matematis juga bukan? Oleh karena itu, data jenis kategori ini kita konversi (encode) menjadi sebuah format angka agar bisa dilakukan proses matematis.
- Baris 17 adalah proses import class LabelEncoder dan OneHotEncoder dari sub library sklearn.preprocessing. LabelEncoder digunakan untuk merubah nama
- Baris 18 mengimpor class ColumnTransformer dari sub library sklearn.compose. Sebelum ada update sklearn ke versi terbaru, sebelumnya kita menggunakan parameter categorical_features pada saat menggunakan perintah OneHotEncoder. Namun di versi terbaru, parameter ini sudah tidak bisa dipakai. Oleh karena itu kita gunakan ColumnTransformer.
- Mirip dengan proses sebelumnya, baris ke 19 adalah proses LabelEncoder yang kita namai Labelencoder_X. Kita namai demikian karena kita ingin menkonversi independen variabel X (‘Beli’). Cukup mengetik LabelEncoder() tanpa parameter apapun di dalamnya.
- Baris ke 20 adalah implementasi LabelEncoder dengan metode fit_transform. Mengapa bukan fit namun justru fit_transform? Secara gampang, metode fit adalah proses perhitungannya, sementara transform adalah proses pengisiannya (implementasi hasilnya ke dalam variabel yang diinginkan), dan fit_transform adalah penggabungan keduanya. Sehingga setelah melakukan proses encoding kita juga ingin menginputkannya sekaligus. Kita memilih kolom ‘Negara’, oleh karena itu index nya semua baris dan kolom ke nol. Sekarang, coba eksekusi X di console, maka akan tampak sebagai berikut:

France dikonversi menjadi 0, Spain menjadi 2 dan Germany menjadi 1.
Proses konversi ini berhasil mengonversi data kategori menjadi angka. Namun muncul masalah baru, apakah angka 2 (Spain) berarti lebih besar dari 1 (Germany) dan 0 (France)? Tentu saja kita tidak menginkan demikian. Tujuan awal kita hanya mengonversi ke angka saja. Namun jika hanya sampai di sini, maka python akan menganggap 2 lebih besar 1, 100 lebih besar dari 50 dst. Oleh karena itu kita memerlukan apa yang disebut dengan dummy variable.
Ide dari dummy variable ini adalah karena ‘Negara’ memiliki 3 jenis kategori (0,1 dan 2), maka kita butuh 3 kolom. Ilustrasinya dapat dilihat sebagai berikut:

Jadi kolom France hanya memiliki nilai 1 jika nama negaranya memang France, begitu pula Spain dan Germany. Di balik layar, sebenarnya apa yang dilakukan adalah membuat matrix [jumlah data x jumlah kategori].
- Baris ke 21-23 adalah perintah untuk mendefinisikan objek dengan nama transformer (pemilihan nama ini bebas). ColumnTransformer Parameternya adalah sebagai berikut:
– Parameter pertama adalah nama kolom yang ingin dibuat dummy variabel nya. Dalam hal ini adalah kolom negara.
-Parameter kedua adalah perintah yang ingin diaplikasikan kepada kolom tersebut. Dalam hal ini kita ingin menggunakan OneHotEncoder untuk membuat dummy variable.
-Parameter ketiga adalah urutan kolomnya. Karena kolom yang kita inginkan adalah kolom ‘Negara’, maka kita pilih kolom ke nol (0).
Setelah itu diikuti dengan parameter remainder:’passthrough’. Artinya kita biarkan kolom-kolom yang lain seperti itu apa adanya.
Jika kita eksekusi, mungkin kita akan mendapatkan peringatan seperti ini:
FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values.
If you want the future behaviour and silence this warning, you can specify “categories=’auto'”.
In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly.
Tenang saja, hal ini terjadi karena di versi sklearn yang baru, kita tidak perlu lagi melakukan LabelEncoder jika menggunakan ColumnTransformer. Maka untuk menghilangkan warning ini, cukup hilangkan 19 dan 20.
Saya harap pembaca memahami prosesnya, bahwa kita ingin merubah nama negara menjadi angka (dengan menggunakan LabelEncoder), kemudian membuat angkanya menjadi dummy variable (dengan menggunakan OneHotEncoder). Di library sklearn yang baru, semuanya disingkat jadi satu dengan menggunakan ColumnTransformer.
- Baris ke 24 kita mengaplikasikan objek transformer yang didefinisikan di line 21 untuk merubah kolom ke nol (kolom ‘negara’) menjadi dummy variabel untuk variabel X. Perintahnya adalah dimulai dengan np.array, karena hasil dari ColumnTransformer mengharuskan objeknya berbentuk array. Kemudian kita isikan parameter di dalamnya transformer.fit_transform terhadap variabel X. Jangan lupa ditambahkan dtype=np.float (data tipe yang diinginkan untuk setiap kolomnya adalah adalah numpy, dan ditambahkan koma jika memang berupa desimal, karenanya berjenis float).
- Jika ingin melihat hasilnya, klik dua kali pada variabel X di tab Variable explorer. Hasilnya akan tampak seperti berikut:
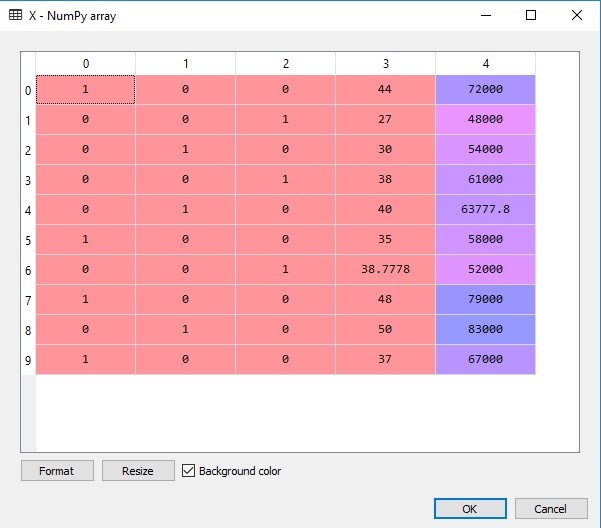
- Line 25 dan 26 adalah proses encoding untuk variabel dependen ‘Beli’. Karena ia hanya memiliki dua kategori yaitu Yes (1) dan No (0), maka tidak memerlukan OneHotEncoder. Mengingat kita hanya ingin memproses kategori Yes (1) saja.
Tips: Untuk menghilangkan warning karena adanya update sklearn ke versi terbaru, berikut saya tuliskan ulang dalam bahasa Python:
# Mengimpor library yang diperlukan
import numpy as np
import pandas as pd
# Import data ke python
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
# Memproses data yang hilang (missing)
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values= np.nan, strategy = 'mean')
imputer = imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
# Encoding data kategori dan variabel independen
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
transformer = ColumnTransformer(
[('Negara', OneHotEncoder(), [0])],
remainder='passthrough')
X = np.array(transformer.fit_transform(X), dtype=np.float)
# Encode variabel dependen
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
Bahasa R
# Mengimpor dataset
dataset = read.csv('Data.csv')
# Memproses data yang hilang
dataset$Usia = ifelse(is.na(dataset$Usia),
ave(dataset$Usia, FUN = function(x) mean(x, na.rm = TRUE)),
dataset$Usia)
dataset$Gaji = ifelse(is.na(dataset$Gaji),
ave(dataset$Gaji, FUN = function(x) mean(x, na.rm = TRUE)),
dataset$Gaji)
# Konversi data kategori
dataset$Negara = as.numeric(factor(dataset$Negara,
levels = c('France', 'Spain', 'Germany'),
labels = c(1, 2, 3)))
dataset$Beli = as.numeric(factor(dataset$Beli,
levels = c('No', 'Yes'),
labels = c(0, 1)))
Semua proses dalam bahasa python tadi juga sama persis dilakukan juga dalam penulisan bahasa R. Hanya saja beberapa proses dan teknisnya saja yang berbeda. Penulisan bahasa R memang lebih ringkas dan biasanya lebih sedikit dengan hasil yang sama persis. Itu semua tergantung preferensi Anda sebagai seorang pembuat program.
Jika sudah melakukan semua proses di atas (bahasa python ataupun R) maka proses persiapan selesai. Setelah preprocessing ini, maka langkah selanjutnya adalah membagi data menjadi dua bagian yaitu train set dan test set.
bang saya mengalami kendala untuk line 22 dan 23 untuk sklearn yang versi terbaru
Terima kasih masukannya. Benar, semenjak ada upgrade sklearn, maka ada beberapa parameter yang deprecated (tidak bisa dipakai lagi).
Saya sudah update sehingga tidak akan muncul warning lagi, dan tentunya berlaku untuk versi sklearn yang terbaru. Semoga bermanfaat 🙂
Sebelumnya terimakasih sudah berbagi Pak, sangat membantu saya.
Saya memiliki pertanyaan untuk bahasa R line 15, labels=c(1,2,3), apakah tidak menimbulkan masalah seperti bahasa python dimana 1 dipandang < dari 2 dst, sehingga kita harus membuat dummy variable?
Halo Edhi, pertanyaan yang bagus.
Di dalam R, dummy variable otomatis sudah diperhitungkan, sehingga ketika menjalankan line 15, maka R otomatis sudah membuatkan dummy variable-nya di balik layar.
Semoga menjawab 😀
Thanks bang
Assalamualaikim pak, saya ingin bertanya apakah tidak apa-apa jika variabel yang merupakan variabel diskrit seperti umur dibuat menjadi kontinyu mengingat karena diisi dengan rata-rata.?
Mohon pencerahannya pak
Wa’alaikumsalam. Umur adalah variabel kontinu, karena kita bisa bilang usia 17 tahun, 17.5 tahun dst. Tapi usia juga bisa menjadi diskrit, di mana variabel kontinu sebenarnya juga diskrit kalau dipecah kecil2. Jika dianggap diskrit maka gunakan distribusi poisson.
Semoga menjawab.
ini sangat luar biasa
Izin bertanya pak
Dalam kasus di atas kan missing valuenya terdapat 1 di setiap kolom sehingga bisa lgsung diisi misal dgn rata2. Jika kasus lain dalam 1 kolom terdapat beberapa missing value, aturan pengisian rata2nya bagaimana pak? Apakah semua missing value jadi bernilai sama (sebesar rata2) atau satu persatu dihitung lagi rata2nya, atau bagaimana pak?
Terima kasih
saya juga berfikiran sama, semoga nanti bisa di jawab
Maaf pak saya mau nanya, kok ketika saya eksekusi x hasilnya begini ya?
Out[2]:
array([[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.40000000e+01,
7.20000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 2.70000000e+01,
4.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.10000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.37777778e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.87777778e+01,
5.20000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
7.90000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 5.00000000e+01,
8.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
6.70000000e+04]])
Ini hanya masalah setting di Spyder yang menunjukkan angka koma secara berlebihan (kebanyakan).
Bisa diatur di bagian setting Spyder.
Kalo boleh tau setting preferences yang mana ya pak? saya cari di google kebanyakan bahasa inggris, saya kurang paham.
Pada variable explorer pilih X, kemudian di bagian kiri bawah ada ‘Format’.
Klik ‘Format’ lalu set float formatting menjadi ‘%.6g’
maaf pak saya mau nanya,saya juga mengalami hal seperti di atas,saya menggunakan jupyter notebook,apakah ada
solusinya pak ?
Diatur formatnya saja