
")
Catatan penting : Jika pembaca benar-benar awam tentang apa itu Python, silakan klik artikel saya ini. Jika pembaca belum mengerti konsep dasar deep learning / neural networks, alangkah baiknya baca dulu artikel saya yang membahas tentang konsepnya di link ini.
Kali ini kita akan membuat sebuah recommender system menggunakan teknik Boltzmann Machines. Sebelum kita bahas lebih lanjut, silakan pembaca install dulu PyTorch di Anaconda, karena kita akan melakukannya di platform PyTorch. Pembaca juga sangat dianjurkan untuk memahami teori Boltmann Machines di artikel saya sebelumnya di link ini.
Untuk mengetahui apa itu Pytorch dan bagaimana cara instalasinya di Anaconda, silakan baca artikel saya di link ini.
Recommender system (RS) yang bisa kita buat ada dua jenis:
- Memprediksi pelanggan kita apakah akan menyukai sebuah produk tertentu atau tidak. Output dari prediksi ini adalah binary (Yes/No). Caranya adalah dengan menggunakan Boltzmann Machines.
- Memprediksi rating yang akan diberikan oleh pelanggan terhadap sebuah produk tertentu. Output dari prediksi ini adalah angka numerik mulai dari 1-5. Caranya adalah dengan menggunakan Autoencoders.
Pada dasarnya dua jenis RS di atas adalah RS yang paling sering digunakan di industri. Seperti misalnya di toko online, maka biasanya website akan menawarkan produk baru ke kita. Penawaran ini sebenarnya didasarkan dari history kita di masa lalu. Produk-produk yang ditawarkan tentunya produk yang memiliki kecenderungan paling tinggi untuk kita sukai.
Tanpa berpanjang lebar, silakan pembaca buka dulu datasetnya dengan mengklik link ini. Tampilan dari website yang akan kita bukan adalah seperti berikut:

Dataset yang kita gunakan adalah dataset nyata yang merupakan kumpulan rating dari ratusan ribu hingga jutaan film. Dataset ini adalah hasil dari GroupLens Research.
Dataset yang akan kita gunakan adalah yang sederhana yang terdiri dari 100.000 rating dari 1000 pengguna unuk 1700 film. Pembaca bisa mendownload sesuai dengan tampilan di bawah ini:

Pembaca cukup klik link sesuai ilustrasi gambar di atas. Jika sudah silakan extract filenya dan tempatkan di folder yang diinginkan (working directory kita nantinya).
Sebagai review, bahwa file ini (folder 100k rating) akan kita gunakan untuk sebagai training set dan test set untuk membangun model Restricted Boltzmann Machines (RBM).
Untuk membantu pemahaman kita dalam membuat model RMB, sangat dianjurkan pembaca untuk mengunduh dan membaca referensi utamanya di link ini.
Bahasa Python
# Mengimpor library yang diperlukan
import numpy as np
import pandas as pd
import torch
import torch.utils.data
from torch import Tensor as tt
# Menyiapkan training set dan test set
training_set = pd.read_csv('ml-100k/u1.base',sep = '\t', header = None)
training_set = np.array(training_set, dtype = 'int')
test_set = pd.read_csv('ml-100k/u1.test', sep = '\t', header = None)
test_set = np.array(test_set, dtype = 'int')
# Menentukan jumlah maksimum pengguna (users) dan film untuk dibuat matriks
nb_users = int(max(max(training_set[:,0]), max(test_set[:,0])))
nb_movies = int(max(max(training_set[:,1]), max(test_set[:,1])))
# Merubah data menjadi sebuah array (matriks) di mana baris adalah users dan kolom adalah film
def konversi_matriks(data):
data_baru = []
for id_users in range(1, nb_users+1):
id_movies = data[:,1][data[:,0] == id_users]
id_ratings = data[:,2][data[:,0] == id_users]
ratings = np.zeros(nb_movies)
ratings[id_movies - 1] = id_ratings
data_baru.append(list(ratings))
return data_baru
# Mengaplikasikan fungsi konversi_matriks ke training set dan test set
training_set = konversi_matriks(training_set)
test_set = konversi_matriks(test_set)
# Mengubah training_set dan test_set ke dalam Torch Tensor
training_set = torch.FloatTensor(training_set)
test_set = torch.FloatTensor(test_set)
# Merubah rating menjadi binary = 1 (suka) dan 0 (tidak suka)
training_set[training_set == 0] = -1
training_set[training_set == 1] = 0
training_set[training_set == 2] = 0
training_set[training_set >= 3] = 1
test_set[test_set == 0] = -1
test_set[test_set == 1] = 0
test_set[test_set == 2] = 0
test_set[test_set >= 3] = 1
# Membuat rancangan arsitektur neural networks RBM
class RBM():
def __init__(self, nv, nh):
self.W = torch.randn(nh, nv)
self.a = torch.randn(1, nh)
self.b = torch.randn(1, nv)
def sample_h(self, x):
wx = torch.mm(x, self.W.t())
activation = wx + self.a.expand_as(wx)
p_h_untuk_v = torch.sigmoid(activation)
return p_h_untuk_v, torch.bernoulli(p_h_untuk_v)
def sample_v(self, y):
wy = torch.mm(y, self.W)
activation = wy + self.b.expand_as(wy)
p_v_untuk_h = torch.sigmoid(activation)
return p_v_untuk_h, torch.bernoulli(p_v_untuk_h)
def train(self, v0, vk, ph0, phk):
self.W += (torch.mm(v0.t(),ph0) - torch.mm(vk.t(),phk)).t()
self.b += torch.sum((v0 - vk), 0)
self.a += torch.sum((ph0 - phk), 0)
def predict(self, x):
_,h = self.sample_h(x)
_,v = self.sample_v(h)
return v
# Menentukan jumlah nv, nh dan batch_size
nv = 1682
nh = 100
batch_size = 100
rbm = RBM(nv, nh)
nb_epoch = 10
# Proses training RBM
for epoch in range(1, nb_epoch + 1):
train_loss = 0
s = 0.
for id_user in range(0, nb_users + 1, batch_size):
vk = training_set[id_user:id_user+batch_size]
v0 = training_set[id_user:id_user+batch_size]
ph0,_ = rbm.sample_h(v0)
for k in range(10):
_,hk = rbm.sample_h(vk)
_,vk = rbm.sample_v(hk)
vk[v0<0] = v0[v0<0]
phk,_ = rbm.sample_h(vk)
rbm.train(v0, vk, ph0, phk)
train_loss += torch.mean(torch.abs(v0[v0>=0] - vk[v0>=0]))
s += 1.
print('epoch: '+str(epoch)+' loss: '+str(train_loss/s))
# Proses testing RBM
test_loss = 0
s = 0.
for id_user in range(nb_users + 1):
v = training_set[id_user:id_user+1]
vt = test_set[id_user:id_user+1]
if len(vt[vt>=0]) > 0:
_,h = rbm.sample_h(v)
_,v = rbm.sample_v(h)
test_loss += torch.mean(torch.abs(vt[vt>=0] - v[vt>=0]))
s += 1.
print('test loss: '+str(test_loss/s))
# Mengambil contoh id_user untuk diprediksi perilakunya
user_id = 0
while (user_id<=0 or user_id>=944):
user_id = int(input('masukkan user_id yang diinginkan (antara 1-943) = '))
if(user_id<=0 or user_id>=944):
print('Masukkan angka antara 1-943')
user_input_training = tt(training_set[user_id-1]).unsqueeze(0)
user_input_test = tt(test_set[user_id-1]).unsqueeze(0)
# Membuat prediksi untuk training set
prediksi_training = rbm.predict(user_input_training)
prediksi_training = prediksi_training.data.numpy()
prediksi_film_training = np.vstack([user_input_training, prediksi_training])
# Membuat prediksi untuk test set
prediksi_test = rbm.predict(user_input_test)
prediksi_test = prediksi_test.data.numpy()
prediksi_film_test = np.vstack([user_input_test, prediksi_test])
Penjelasan:
- Line 2-6 mengimpor library yang diperlukan. Perlu diperhatikan bahwa line 4-6 kita menggunakan PyTorch, jadi pastikan pembaca sudah menginstall PyTorch di Anaconda. Penjelasan line 4-6 akan dijelaskan sambil jalan.
- Line 9-12 mendefinisikan training set dan test set.
Line 9 mendefinisikan training set di mana file yang akan kita gunakan berada di folder ‘m1-100k‘. Bisa dilihat di dalam folder ini sebagian besar file nya terdiri atas 2 ekstensi yaitu ‘.base‘ dan ‘.test‘ sebanyak 5 buah pasang. Jadi ada file ‘u1.base’ dan ‘u1.test‘ sebagai 1 pasang file. Sebagai ringkasan base=training set dan test=test set.
Pertanyaannya mengapa di folder ini ada banyak file berpasangan untuk training set dan test set? Jawabannya adalah untuk melakukan K-Fold Cross Validation yang merupakan sebuah teknik untuk memvalidasi model AI kita nantinya. Karena ada 5 pasang file, maka kita bisa melakukan 5-fold cross validation.
Walau demikian, karena pembahasan kali ini adalah tentang RBM, maka kita hanya bermain dengan file pasangan pertama saja yaitu u1.base dan u1.test. Kita mulai dari yang sederhana.
Jika kita cek file u1.base di notepad maka akan tampak sebagai berikut:

Untuk mengimpor u1.base ke python kita cukup gunakan import csv dengan library pandas.
Kita belum selesai, karena jika sudah mengimpor filenya menggunakan library pandas, maka kita akan mendapat file berformat data frame, sementara yang kita inginkan adalah format array. Oleh karena itu, di line 10 kita convert training_set tadi menjadi sebuah array bertipe integer dengan library numpy.
Di line 9 kita gunakan argumen sep = ‘\t’, artinya kita menginginkan setiap ada tab di fiile u1.base maka kita membentuk kolom yang baru.
Jika line 9-12 sudah dieksekusi, maka tampilan training set dan test set adalah sebagai berikut:
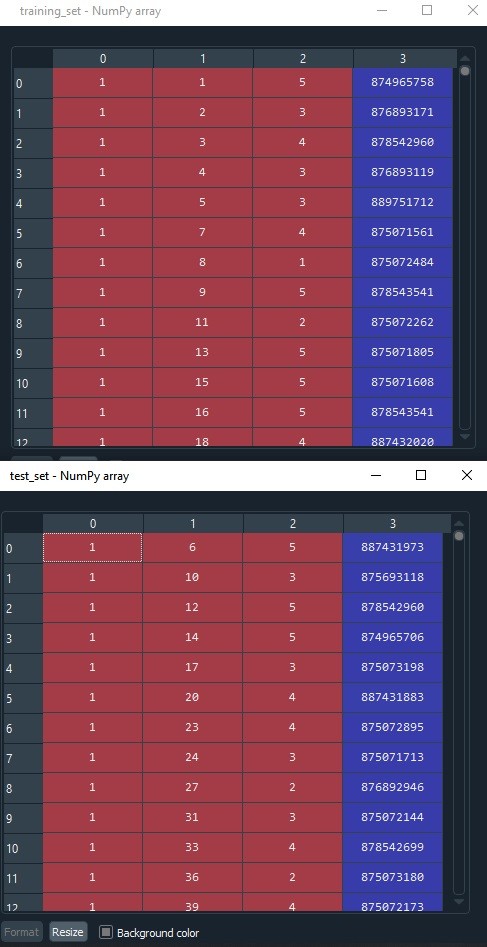
Proporsi training set : test set yang kita miliki adalah 80:20 dengan total 80 ribu untuk training set dan 20 ribu untuk test set. Angka ini bisa dilihat di variable exporer di spyder.
Pelabelan kolom adalah sebagai berikut. Kolom pertama adalah urutan user (ID_user), kolom kedua adalah ID film yang diberikan rating, kolom ketiga adalah nilai ratingnya (1-5 dengan skor 5 adalah yang paling tinggi), dan kolom keempat adalah waktu pemberian rating (timestamp).
- Line 15 dan 16 menentukan jumlah maksimum users dan film yang nantinya akan digunakan untuk membuat matriks. Kita ingin membuat matriks di mana barisnya adalah users, kolom adalah film dan tiap cell nya adalah rating film. Kurang lebih seperti inilah tampilan matriks yang kita inginkan:
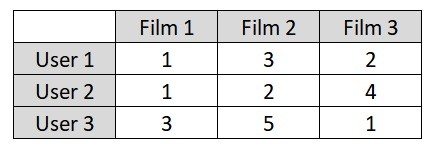
- Line 15 adalah untuk menentukan jumlah maksimal users (kolom indeks ke-0).
- Line 16 adalah maksimal jumlah film (kolom indeks ke-1). Kita akan mengambil jumlah maksimum baik users atau film di training set dan test set.
Jika sudah dieksekusi, kita akan mendapatkan jumlah users maksimalnya adalah 943 dan jumlah film 1682. Tampilannya di variabel explorer tampak sebagai berikut:

- Line 19-27 mendefinisikan fungsi dengan nama konversi_matriks. Di fungsi ini kita ingin membuat list of list, di mana di dalam list ada list.
- Line 19 mendefinisikan nama fungsinya dan menggunakan nama variabel data sebagai objek fungsinya.
- Line 20 mendefinisikan variabel baru dengan nama data_baru sebagai sebuah list kosong. Nantinya hasil dari fungsi konversi_matriks akan diisikan ke variabel ini.
- Line 21 melakukan for loop dengan menggunakan fungsi range dan nama indentor-nya adalah id_users (penentuan nama indentor ini bebas). Perlu diingat bahwa fungsi range tidak mengikutsertakan batas akhirnya. Oleh karena itu agar batas akhirnya (dalam hal ini adalah nb_users) diikutkan, maka kita tambahkan satu.
- Line 22 mendefinisikan variabel di dalam fungsi dengan nama id_movies, di mana ia akan memilih kolom indeks ke-1 di data (nanti nama data ini diganti dengan training_set atau test_set) dan kolom indeks ke-0 yang sesuai dengan indentor-nya (id_users). Intinya adalah kita mengisikan semua id_movies yang sudah ada di training maupun test set di variabel ini.
- Line 23 sama seperti line 30 hanya saja namanya adalah id_ratings. Kita memilih kolom indeks ke-2 di data (kolom ratings). Intinya kita mengisikan semua id_ratings di variabel ini.
- Line 24 kita buat variabel dengan nama ratings. Kita isikan nilai ratings=0 jika diasumsikan users belum mengisikan rating untuk baris tersebut. Caranya adalah dengan menggunakan fungsi numpy.zeros sebanyak jumlah nb_movies.
- Line 25 mengisikan ratings yang merupakan id_ratings. Hal ini berbeda dengan line 23. Jika ratings untuk film tersebut memang sudah ada, maka kita isikan ratingnya. Bagaimana caranya? Dengan menggantikan nilai 0 di rating id_movies dan id_users tersebut untuk id_ratings yang ada. Hal yang perlu diperhatikan adalah di Python indeks dimulai dari nol, sementara id_movies yang kita miliki dimulai dari 1. Agar sama maka dalam penulisan kita tuliskan ratings[id_movies -1].
- Line 26 adalah menambahkan isi variabel ratings ke variabel data_baru. Caranya adalah kita gunakan fungsi append. Perlu diperhatikan juga sebelum kita gunakan append, kita rubah dulu formatnya ke dalam bentuk list.
- Line 27 adalah penggunakan fungsi return. Hal ini agar nanti hasil dari fungsi konversi_matriks bisa digunakan.
- Line 30 dan 31 adalah mengaplikasikan fungsi konversi_matriks ke training_set dan test_set. Hasil eksekusinya adalah sebagai berikut:

Sekarang jika kita perhatikan struktur dari training_set dan test_set di atas maka kita memiliki users sebagai baris, movies sebagai kolom dan rating sebagai isi antara baris dan kolom. Ini adalah struktur yang akan kita gunakan di lines selanjutnya.
- Line 34 dan 35 mengubah training_set dan test_set kita ke dalam Torch Tensor. Caranya adalah dengan menggunakan fungsi torch.FloatTensor(). Variabel yang diperlukan oleh FloatTensor adalah list of list. Dengan demikian cukup masukkan saja training_set dan test_set sebagai objek FloatTensor.
Apa itu tensor? Tensor adalah sebuah array multidimensional yang terdiri dari sau jenis tipe data.
Mengapa line 34 dan 35 diperlukan? Bukankah kia juga bisa menggunakan numpy array untuk membuat model RBM? Ya itu benar, namun array versi PyTorch jauh lebih efisien dalam hal ini. Oleh karena itu, tipe array yang kita gunakan adalah array versi PyTorch, disebut dengan PyTorch Tensors.
Ilustrasi training_set yang sudah dirubah menjadi PyTorch Tensor adalah sebagai berikut:

Dalam Restricted Botzmann Machines (RBM) kita akan memprediksi apakah user akan menyukai sebuah film atau tidak. Dengan demikian output yang diinginkan adalah berupa binary (0 atau 1). Oleh karena itu, kita harus merubah nilai ratingnya menjadi binary. Alasan utamanya adalah format output (binary) harus sama dengan format input (binary) di neural networks RBM kita.
- Line 38-45 merubah ratings menjadi binary.
- Line 38 merubah nilai training_set nilai 0 (nilai 0 artinya memang tidak ada rating/belum sempat dirating oleh user) menjadi -1. Nilai -1 adalah tanda khusus yang kita berikan yang bernilai bahwa film ini belum ada ratingnya.
- Line 39 merubah nilai training_set nilai 1 (hanya 1 bintang) menjadi 0 (tidak disukai).
Pada dasarnya kita ingin merubah nilai rating 1-2 menjadi 0 (tidak disukai), dan nilai di atas 2 (3,4,5) menjadi 1 (disukai). Tentu saja pemilihan rating 3,4,5 menjadi 1 sangat subjektif, dan pembaca bebas melakukannya dengan cara berbeda.
- Line 40 merubah rating training_set 2 menjadi 0.
- Line 41 merubah rating training_set 3, 4, dan 5 menjadi 1.
- Line 42-45 kita lakukan hal yang sama untuk test_set.
Sekarang kita sudah selesai menyiapkan input nodes untuk RBM kita. Langkah selanjutnya adalah mulai membangun neural networks RBM yang kita inginkan.
- Line 48-70 membuat class untuk mendefinisikan arsitektur RBM kita. Jika pembaca belum memahami tentang konsep Object Oriented Programming (OOP), silakan baca artikel saya tentang OOP di link ini.
- Line 48 mendefinisikan nama class-nya adaah RBM.
- Line 49 mendefinisikan method __init__ dengan argumen yang diperlukan adalah nv dan nh. Argumen nv adalah number of visible nodes (jumlah nodes yang terlihat) dan nh adalah number of hidden nodes (jumlah nodes yang tidak terlihat).
- Line 50 mendefinisikan (initialize) parameter W sebagai weights (bobot) di mana secara teori ukurannya adalah random berdasarkan jumlah nv, dan nh. Cara mendefinisikannya sangat mudah, cukup gunakan fungsi torch.randn (mendefinisikan bilangan random berdasarkan distribusi normal).
- Line 51 mendefinisikan bias (parameter untuk menghasilkan error di model). Kita sebut saja namanya adalah a. Dimensi pertama adalah ukuran kolom = 1, dan ukuran kedua adalah jumlah nh. Jadi dimensinya adalah 1xnh (1 kolom dengan baris sebanyak nh).
- Line 52 sama seperti line 51, namun kali ini untuk nv dan kita berikan nama parameternya adalah b.
Langkah selanjutnya adalah mendefinisikan method baru di class RBM di mana method ini akan menginisiasi (generate secara random) hidden nodes di RBM kita.
- Line 53-57 mendefinisikan method dengan nama sample_h untuk menginisiasi hidden nodes.
- Line 53 mendefinisikan method sample_h dengan argumen x, di mana x ini merujuk pada visible neurons v dengan probabilitas h untuk v yang ada (secara matematis ditulis P(h|v)). Maksud dari P(h|v) adalah probabilitas hidden nodes bernilai satu di mana ia didasarkan pada nilai probabilitas visible nodes.
Jika pembaca bingung, pada dasarnya kita berada di tahap 5 dari algoritma berikut:

Algoritma di atas bisa dilihat di paper yang saya tautkan di link ini.
- Line 54 kita mendefinisikan objek wx yang merupakan perkalian antara neurons dengan bobotnya (w). Untuk bisa melakukannya kita bangkitkan dua tensors terlebih dahulu dengan fungsi torch.mm. Argumen yang diperlukan adalah x (visible neurons) dan W (merujuk ke self.W. Kemudian kita perlu melakukan transpose terhadap objek W ini, maka ditulis W.t().
- Line 55 kita mendefinisikan activation function dari neuron x ini. Isinya adalah objek wx di atasnya ditambahkan dengan bias a. Hal yang perlu diperhatikan bahwa agar bias a bisa diaplikasikan untuk setiap baris di wx, maka dibutuhkan fungsi tambhana dari PyTorch yaitu expand_as(). Untuk melihat dokumentasi expand_as bisa dilihat di link ini.
- Line 56 kita mendefinisikan P(h|v) ditulis sebagai variabel dengan nama p_h_untuk_v. Ia merupakan sigmoin function dari nilai aktivasi yang sudah didefinisikan di line 63. Karena kita menggunakan PyTorch, maka cara pengaplikasiannya cukup gunakan fungsi torch.sigmoid() dan di dalamnya cukup masukkan objek variabel activation.
- Line 57 adalah fungsi return di mana kita ingin menggunakan hasil p_h_untuk_v dan beberapa sample dari hidden neurons yang merupakan hasil dari P(h|v). Untuk bisa melakukan yang kedua ini, kita gunakan fungsi torch.bernoulli() yang merupakan fungsi untuk bernoulli sampling dan di dalamnya kita masukkan objek p_h_untuk_v.
Sedikit saya jelaskan tentang hubungan antara P(h|v) dan bernoulli sampling. Jadi p_h_untuk_v yang kita miliki adalah sebuah vektor dari beberapa elemen sebanyak nh, misal terdiri dari 100 elemen. Jadi setiap elemen merepresentasikan sebuahprobabilitas hidden neuron (nh) tersebut aktif (nyala). Perlu diperhatikan bahwa nilainya tergantung dari nilai visible nodes, artinya berdasarkan pada nilai rating yang diberikan oleh user (nilai rating dalam konteks ini adalah visible nodes karena kita tahu nilainya. Sekarang idenya adalah menggunakan nilai probabilitas ini (P(h|v)) untuk melakukan sampling hidden nodes, apakah sebuah nh akan aktif atau tidak. Bagaimana caranya, misal jika probabilitasnya adalah 0.8, maka kita bangkitkan bilangan random dengan bernoulli sampling antara 0-1. Jika nilainya di bawah 0.8 maka kita nyalakan neuron nya (bernilai 1), namun jika di atas 0.8 kita aktifkan neuronnya (bernilai 0). Jadi semoga bisa dipahami.
- Line 58-62 kita lakukan mirip seperti line 53-57 tapi kali ini untuk visible nodes. Semua lines mirip kecuali line 59 (dijelaskan kemudian). Sekarang kita berada di langkah ke-6 dari algoritma contrastive divergence seperti di gambar sebelumnya.
- Line 58 kita definisikan nama method nya yaitu sample_v dengan argumen kita beri nama y. Argumen y di sini merepresentasikan hidden nodes.
- Line 59 berbeda dari line 54 karena kali ini kita tidak melakukan proses transpose dan wx kita ganti menjadi wy. Mengapa kita tidak memerlukan transpose? Karena nilai W itu sendiri adalah hasil dari matriks (nh x nv). Karena sekarang kita menghitung P(v|h) maka tidak diperlukan transpose. Jika kita menghitung P(h|v) seperti di line 58-62 maka kita perlu melakukan transpose.
- Line 63-66 mendefinsikan method train untuk melakukan proses training. Kita saat ini fokus di langkah 7-10 dari algoritma contrastive divergence seperti di gambar sebelumnya.
Pada dasarnya yang kita lakukan sekarang adalah mengupdate nilai bobot, nilai bias b dan bias a. Sesuai dengan algoritma langkah 7-10 di bawah ini. Jadi cukup kita buat bahasa Python untuk algoritmanya.

- Line 71 mendefinisikan nama method nya yaitu train dengan 4 argumen.
Argumen yang pertama adalah input vector yang kita sebut namanya adalah v0 (tentu saja penamaan ini bebas, namun v0 sudah menjadi nama umum di RBM). Parameter v0 ini adalah nilai rating yang sudah kita siapkan untuk semua users. Argumen kedua adalah visible nodes yang sudah didapatkan setelah iterasi sebanyak k sampling (baca tentang k–contrastive divergence). Kemudian argumen ketiga adalah ph0 yang merupakan vektor probabilitas iterasi pertama di mana nilai hidden nodes adalah 1 di mana nilainya ditentukan oleh nilai v0. Kemudian argumen terakhir adalah phk yang merupakan probabilitas hidden nodes setelah k-sampling di mana nilainya ditentukan oleh vk.
- Line 64 mengupdate nilai W dengan menggunakan fungsi torch.mm. Formulanya bisa dilihat di algoritma, jadi kita cukup tuliskan bahwa ia merupakan hasil pengurangan antara matriks v0 dikalikan matriks ph0 dengan matriks vk dikalikan matriks phk. Penentuan nilai v0, vk, ph0 dan phk akan dilakukan nanti saat melakukan training RBM beberapa kali epoch. Perlu diperhatikan bahwa matriks v0 dan vk harus ditranspose terlebih dahulu agar bisa dikalikan. Hasil akhir dari semuanya juga harus ditranspose agar tidak error nantinya saat dilakukan proses training epoch mengingat dimensi tensor harus sama.
- Line 65 mengupdate bias b yang merupakan selisih antara v0 dengan vk. Untuk melakukannya kita gunakan fungsi torch.sum(). Argmen yang kita masukkan adalah input vektor yang diinginkan (selisih v0-vk) dan tambahan 0 untuk memastikan dimensinya menjadi 2 dimensi.
- Line 66 mengupdate bias a di mana kali ini adalah tensor sum dari ph0-phk.
- Line 67-70 adalah melakukan prediksi setelah kita berhasil melakukan training RBM melalui beberapa epoch. Argumen yang diperlukan adalah x, di mana x ini adalah visible neurons sama seperti di line 53. Line68-70 saya rasa mudah dipahami dari penjelasan-penjelasan sebelumnya. Penjelasan detailnya ada di bagian prediksi di line bawahnya nanti.
Sekarang kita sudah berhasil membangun arsitektur RBM kita. Langkah selanjutnya adalah melakukan proses training RBM kita selama beberapa kali epoch. Namun sebelum kita melakukan proses training, kita definisikan dulu jumlah nv, nh dan jumlah training epoch yang kita inginkan.
- Line 73 menentukan jumlah visible nodes yang merupakan jumlah film yang ada yaitu 1682.
- Line 74 menentukan jumlah hidden nodes. Silakan pembaca memilih sendiri angka yang diinginkan. Aturan umumnya hidden nodes akan menentukan jumlah feature yang ingin ditangkap oleh model kita. Anggap saja kali ini kita tetapkan 100 hidden nodes.
- Line 75 menentukan jumlah batch size yaitu 100. Tentu saja angka ini bebas, dan pembaca bisa berkreasi dan membandingkannya untuk bebagai batch_size.
- Line 76 mendefinisikan variabel rbm yang merupakan model RBM itu sendiri. Kita cukup panggil class RBM yang sudah kita definisikan di line 56 lengkap dengan 2 argumennya yaitu nv dan nh.
- Line 77 kita menentukan jumlah epoch-nya (tentu saja ini bebas). Dalam hal ini kita memilih angka 10. Mengapa hanya angka 10? Karena data kita tidak cukup banyak (hanya 100 ribu) sehingga lebih cepat converge. Jadi tidak perlu banyak-banyak jumlah epoch nya.
Jika kita sudah menentukan semua parameter ini, sekarang saatnya kita melakukan proses training.
- Line 80-95 adalah proses training RBM.
- Line 80 kita melakukan for loop dengan nama iteratornya kita sebut saja nb_epoch. Perlu diingat bahwa jika menggunakan fungsi range maka batas atas tidak diikutkan. Oleh karena itu kita tambahkan 1 sehingga ditulis range(1, nb_epoch+1).
- Line 81 kita mendefinisikan variabel dengan nama train_loss. Variabel ini nanti akan menjadi alat ukur seberapa akurat hasil training kita. Kita nanti akan membandingkan hasil prediksi di training_set dengan rating asli di test_set. Algoritma train_loss yang akan kita gunakan adalah simple distance, jadi kita menghitung jarak absolut (abs) selisih antara prediksi dengan rating sesungguhnya. Kita set nilainya adalah 0, dan setiap menemukan kesalahan prediksi maka nilainya akan mulai bertambah secara akumulatif.
- Line 82 adalah counter dengan nama s untuk menormalisasi nilai train_loss. Jadi nilai train_loss ini akan dibagi dengan s, di mana s sesuai dengan jumlah epoch. Kita gunakan nilai 0. (0 koma) agar formatnya menjadi float.
- Line 83 kita gunakan for loop dengan nama iterator-nya adalah id_user. For loop di mulai dari 0 hingga nb_users+1. Tapi karena kita menggunakan batch_size maka lompatan for loop nya diberi selang sebesar batch size. Jika pembaca masih bingung bisa baca lagi manual Python di salah satu artikel saya.
- Line 84-85 adalah mengisikan vk dan v0 sesuai urutan id_user nya. Karena rentang for loop nya berjarak sesuai batch_size maka kita pilih mulai dari id_user sesuai iterator hingga id_user ditambahkan dengan ukuran batch_size.
Sebagai review, vk adalah rating hasil prediksi model kita, dan v0 adalah input rating yang sudah ada. Jadi intinya kita akan membandingkan v0 dengan vk.
- Line 86 adalah mengisikan variabel ph0 dengan memanggil method sample_h. Perlu diperhatikan jika kita panggil method sample_h maka ia akan mengembalikan (return) 2 nilai yaitu p_v_untuk_h dan torch.sigmoid(activation). Karena kita hanya memerlukan item yang pertama saja (item kedua digunakan untuk line selanjutnya), maka di Python kita cukup tuliskan ph0,_ (gunakan tanda _).
- Line 87 melakukan for loop sebanyak 10 kali (10 langkah contrastive divergence) dengan nama iterator nya adalah k.
- Line 88 kita mengisikan nilai variabel hk. Karena kita hanya menginginkan item kedua dari method sample_h, maka item pertama cukup tuliskan underscore (tanda _). Parameter hk di sini merepresentasikan sample pertama dari hidden nodes. Argumen yang kita masukkan di method sample_h adalah vk, karena ini yang ingin kita prediksi.
- Line 89 adalah untuk melakukan update nilai vk. Harus selalu diingat bahwa setelah diupdate maka vk ini nanti adalah berupa probabilitas. Kita gunakan method sample_v (untuk visible nodes) untuk hk.
Line 88 dan 89 akan terus diupdate melalui for loop sebanyak 10 kali. Jadi intinya melakukan looping berkali-kali melalui Gibbs sampling dari hidden nodes-visible nodes-hidden nodes-visible nodes dan seterusnya,
- Line 90 digunakan untuk tidak mengikutkan rating yang bernilai -1. Artinya belum ada rating untuk film tersebut. Jika v0 aslinya adalah -1, maka vk juga akan menjadi -1 juga. Dengan demikian, proses updating vk hanya terjadi jika memang ia memiliki rating sebelumnya.
- Line 91 mirip dengan line 86, namun kali ini kita menghitung phk dan menggunakan objek vk.
- Line 92 melakukan proses training dengan memanggil method train dari class RBM yang sudah dijalankan di variabel rbm. Kita cukup memasukkan semua argumen yang dibutuhkan dan sudah kita hitung di line-line sebelumnya.
- Line 93 digunakan untuk mengupdate variabel train_loss. Kita menghitung dengan menggunakan fungsi torch.mean (menghitung nilai rataan) dan torch.abs (membuat nilainya menjadi absolut) dengan mengurangkan v0 dengan vk. Perlu diperhatikan bahwa kita hanya tidak mengikutkan nilai -1 untuk v0 maupun vk.
- Line 94 mengupdate nilai s sebagai counter berapa kali batch_size sudah dijalankan.
- Line 95 mencetak di layar kita sudah berada di epoch ke berapa dan melihat nilai train_loss nya.
Jika kita eksekusi line 80-95 maka tampilannya adalah sebagai berikut:

Bisa dilihat bahwa kita mendapatkan kesalahan prediksi sekitar 24% di mana ini cukup baik. Pembaca bisa saja mendapatkan hasil yang berbeda namun tidak akan terpaut jauh dari yang saya tulis di sini jika melakukan hal yang sama persis. Pembaca tentu saja bisa menaikkan akurasinya dengan menambah epoch misalnya, menambah learning rate atau apapun. Tapi ingat, jangan terlalu banyak tuning (penguatan akurasi melalui perubahan nilai parameter) karena jika terlalu banyak bisa mengarah ke overfitting.
- Line 98-108 adalah menguji test set. Kita ingin melihat apakah hasil pembelajaran model RBM kita dari training set tadi cukup akurat untuk diaplikasikan ke test set.
- Line 98 mendefinisikan variabel dengan nama test_loss. Variabel ini mirip training_loss tapi kali ini untuk test set sehingga namanya test_loss.
- Line 99 mendefinsikan variabel s untuk counter frekuensi epoch dalam proses pengujian test set. Kegunaannya sama persis seperti line 82.
- Line 100 melakukan for loop. Tapi berbeda dengan line 83, kita tidak memerlukan batch size, karena memang ukuran test setnya jauh lebih kecil dan biasanya batch size hanya dipakai saat proses training di training set. Dengan demikian, for loop nya untuk semua jumlah users (jangan lupa untuk ditambahkan 1 untuk fungsi range)
- Line 101 mendefinisikan variabel dengan nama v sebagai input prediksi untuk test set. Variabel v ini sama seperti vk pada line 84, tapi kita beri nama yang berbeda. Kita melakukan update satu demi satu maka kita tuliskan [id_user:id_user+1]. Untuk v kita masih menggunakan training set. Mengapa? Karena kita mengaktifkan modelnya (mengaktifkan neurons di dalam model RBM kita) menggunakan data-data yang berasal dari training set.
- Line 102 mendefinisikan variabel vt (v target) di mana ia mirip dengan v tapi kita gunakan test set. Nantinya perhitungan test_loss adalah selisih antara v dengan vt.
Di dalam test set ini kita tidak memerlukan variabel seperti ph0 dan phk seperti di line 86 dan 91.
- Line 103 kita tidak melakukan for loop sebanyak 10 kali seperti di line 87, tapi cukup 1 kali saja (1 langkah gibbs sampling) khusus untuk test set. Caranya cukup memastikan bahwa posisi id_user yang kita update memang sudah diberikan rating (nilainya lebih dari 0, atau dengan kata lain bukan -1).
- Line 104-105 mendefinisikan variabel h dan v yang sangat mirip dengan line 88 dan 89. Namun kali ini kita hilangkan k-nya, sehingga hk menjadi h dan vk menjadi v.
Karena kita sudah melakukan pengujian logic (vt > 0) di line 103, maka line 90 tidak diperlukan lagi untuk test set.
- Line 106 mengupdate nilai test_loss. Formulanya sangat mirip seperti line 93.
- Line 107 sama seperti line 94.
- Line 108 mencetak hasilnya. Jika kita eksekusi maka tampialnnya sebagai berikut:

Bisa dilihat bahwa hasil dari pengujian test set di atas menghasilkan kesalahan prediksi (loss) sekitar 22%. Tentunya hasil yang didapat pembaca bisa saja berbeda tapi tidak akan terpaut jauh.
Hasil ini cukup baik, dan tidak melenceng jauh dari loss yang dimiliki training set. Ini menunjukkan bahwa model RBM kita bisa cukup memprediksi rating suka tidaknya users terhadap sebuah film tertentu.
Memprediksi Kesukaan Terhadap Film
Kita sudah membuat model RBM kita dengan akurasi cukup baik sekitar 78% (100%-22% = 78%). Kita belum selesai, karena tujuan kita yang sebenarnya adalah melihat hasil prediksi users.
Sekarang kita akan melihat bagaimana model kita bisa memprediksi sebuah film apakah akan disukai user tertentu atau tidak. Kita akan melakukannya baik untuk training set maupun test set.
- Line 111-115 memasukkan nilai user_id yang ingin diperiksa.
- Line 111 kita menginisiasi (set awal) nilai user_id adalah 0.
- Line 112-115 menggunakan while loop agar pengguna (atau kita sendiri) memasukkan angka antara 1-944. Mengapa 944 dan bukan 943 (nilai id_user terbesar adalah 943), karena nanti akan kita kurangkan 1 di line 116. Selain itu di Python user_id dimulai dari 0 dan bukan 1.
- Line 116 dan 117 kita gunakan library torch.Tensor yang sudah didefinisikan di line 6. Library ini digunakan untuk menciptakan tensor. Selain itu kita juga gunakan method unsqueeze untuk memasukkan dimensi tensor bernilai 1 ke indeks ke-0. Dokumentasinya silakan dibaca di link ini,
- Line 120-122 adalah untuk memprediksi training_set. Line 120 adalah eksekusi dari method di class RBM line 67-70. Line 122 adalah penggunaan fungsi np.vstack untuk menumpuk array numpy secara vertikal.
- Line 125-127 adalah untuk test set.
Sekarang kita coba masukkan user_id = 1. Jika dieksekusi hasilnya adalah sebagai berikut:

Gambar di atas menunjukkan dua tabel yang berbeda. Bagian atas aalah training set dan bawah adalah test set.
Baris pertama untuk masing-masing tabel adalah rating yang diberikan. Bernilai 1 jika user dengan id tersebut menyukainya, bernilai 0 jika tidak suka, dan -1 jika ia belum sempat memberikan rating. Sementara baris di bawahnya adalah prediksi dari model RBM kita. Label baris paling atas menyatakan nomor ID dari movies.
Sekarang kita lihat bahwa film dengan ID 5 bernilai -1, artinya film ini belum sempat diberikan rating oleh user ini, dan model kita memprediksi bahwa user ini tidak akan menyukainya (nilainya 0).
Film no 6 sudah dinilai 1 (suka) dan model kita jugra memprediksi hal yang sama.
Film no 7 ia tidak menyukainya (sudah memberikan rating bernilai 0), dan model kita memprediksi bahwa ia akan menyukainya. Tentu saja ini adalah kesalahan prediksi, dan memang kesalahan prediksi training set kita tadi sekitar 24%. Jadi ya wajar saja kadang terjadi kesalahan prediksi, namun masih kecil.
Jika prediksi training set ini kita bandingkan dengan data aslinya, maka ini masih sesuai. Berikut adalah data asli training set (u1.base):
Bisa kita lihat bahwa user_id=1 memang sudah memberikan rating untuk film dengan ID 1,2,3,4,5,7,8, dst. Hal ini sama seperti prediksi model RBM kita di training set bahwa film dengan ID 5 (didapat dari ID 6-1) memang belum diberikan rating dan model kita memprediksi bahwa ia tidak akan menyukainya.
Sekarang kita melihat test set. Di test set ini memang tidak terdapat rating untuk film mulai dari ID 0,1,2,3, dan 4 (di file asli sama dengan film dengan ID 1,2,3,4,5) karena data ratingnya ada di training set. Walau demikian, modelnya berhasil memprediksi dengan baik di mana user ini akan menyukainya. Ditunjukkan dengan data di file asli (u1.base) bahwa memang rating untuk film ID 0,1,2,3,4 adalah di atas 3 (dikonversi menjadi 1 di script python kita).
Jadi demikianlah aplikasi nyata dari Restricted Boltzmann Machines (RBM), di mana dengan RBM kita bisa memprediksi apakah user akan menyukai sebuah film atau tidak. Aplikasinya tidak hanya terbatas pada rating film saja. Jika kita kreatif, maka bisa kita aplikasikan di toko online, di mana kita hanya menawarkan produk-produk yang memang memiliki probabilitas tinggi bahwa ia akan disukai oleh user. Dengan demikian, ini akan bisa meningkatkan penjualan toko online kita.
Aplikasi dari RBM tidaklah dibatasi untuk film, maupun toko online. Masih bisa jauh lebih luas lagi. Selama kita memiliki data pelanggan (data behavior/perilaku), maka kita bisa mengolahnya menjadi sebuah recommender system yang sangat powerful.
Sampai di sini saya harap pembaca bisa memahami aplikasi dari teknik RBM. Jika ada pertanyaan silakan tulis di komentar.
Semoga tetap semangat untuk terus belajar AI bersama saya. Tetap terus kunjungi website maupun channel Youtube saya untuk belajar materi-materi terbaru!.
Mohon izin pak untuk belajar dari page ini tentang RBM. Saya ingin mencoba belajar codingan ini pak, apakah boleh kalau saya meminta data yang digunakan pada codingan ini pak? Terima kasih
Halo. Silakan saja dipakai. Link datasetnya juga sudah saya cantumkan di artikel.