

Aturan Dalam Pemberian Reward
Ada beberapa hal yang perlu diperhatikan ketika kita mendesain sistem pemberian reward kepada agent. Mengapa hal ini penting? Karena sistem reward yang berbeda akan menghasilkan perilaku agent yang berbeda pula.
Anggap kita memiliki sebuah maze, atau kita kenal dengan istilah labirin. Kita bisa saja memberikan reward = +1 hanya jika agent berhasil mencapai garis finish, dan reward = 0 untuk state selainnya. Dengan sistem seperti ini akan menghasilkan perilaku agent yang random (acak), karena ia bisa berjalan ke mana saja di labirin, mengingat setiap langkah yang ia ambil tidak memberikan apapun (reward = 0).
Berbeda hasilnya jika kita buat sistem reward yang berbeda, yaitu kita berikan hukuman untuk setiap langkah (reward = -1), dan netral (reward = 0) jika ia mencapai garis finish. Dengan cara ini, maka agent akan begerak untuk mempersingkat waktu, dan secepat mungkin akan mencari jalur terpendek untuk mencapai garis finish, mengingat setiap langkah justru akan mengurangi akumulasi reward-nya.
Hal lain yang harus diperhatikan adalah kita tidak boleh memberi tahu agent cara bermain layaknya kita yang sudah mengetahui sistemnya. Biarkan agent belajar sendiri mencari solusinya. Dengan kata lain, beritahu ke agent apa yang kita ingin ia raih, namun jangan beritahu caranya.
Memahami Value Function
Sebelum kita mulai programming, maka kita harus memahami istilah value funtion (fungsi nilai). Mengapa hal ini penting? Karena ini akan menjadi kerangka berpikir saat kita membuat program RL untuk TTT,
Untuk bisa memahami apa itu value function, mari kita ilustrasikan melalui seorang remaja yang sedang kasmaran. Ia bingung terhadap 2 pilihan:
- Pergi ke rumah pacarnya dan memberikan kado ulang tahun malam ini
- Belajar karena besoknya ujian
Remaja ini ketika memikirkan untuk pergi ke rumah pacarnya ia merasa sangat bahagia, namun ketika berpikir untuk belajar ia merasa sangat malas. Akhirnya ia memilih untuk pergi ke rumah pacarnya, karena baginya ini lebih menguntungkan di masa depan (kita tidak melihat apakah ini positif atau tidak, ini hanya ilustrasi saja).
Ilustrasi di atas memberikan gambaran bahwa ia melakukan perencanaan di masa mendatang (planning) dengan melihat nilai keuntungan yang ia dapatkan di masa depan. Jika ia datang ke rumah pacarnya maka di masa depan ia membayangkan dirinya bahagia, namun jika ia memilih untuk belajar, ia merasa malas dan kalaupun ia tidak bisa mengerjakan ujian, ia tidak merasa ini akan menjadi masalah baginya di masa depan.
Kita sedang membicarakan gambaran nilai di masa depan (apa saja hal yang bisa kita dapat) akibat aktivitas yang kita lakukan saat ini. Ini adalah definisi dari value function. Jadi kata kuncinya adalah present –> future.
Konsep value function (VF) juga sering disebut dengan istilah lain yaitu credit assignment problem (CAP). Mirip dengan VF, namun CAP berbicara bahwa apa yang kita dapatkan saat ini adalah hasil dari perilaku di masa depan. Jadi kata kuncinya adalah past –> present. Mirip memang, tapi sedikit berbeda.
Ilustrasi sederhana dari CAP adalah seseorang yang ingin diterima bekerja di sebuah perusahaan besar. Ia berpikir tentang hal-hal apa saja yang pernah ia lalui di masa lalu, seperti skills yang ia dapat saat sekolah, pelajaran apa saja yang sudah ia pelajari, ilmu apa saja yang sudah ia dapat, dan lain-lain sehingga ia bisa dianggap pantas diterima di perusahaan tersebut. Itu semua adalah contoh dari CAP.
Mengapa VP atau CAP penting? Karena ketika kita membuat program RL nanti, kita akan bergerak menggunakan fungsi ini. Ilustrasi mudahnya bisa digambarkan melalui contoh berikut:
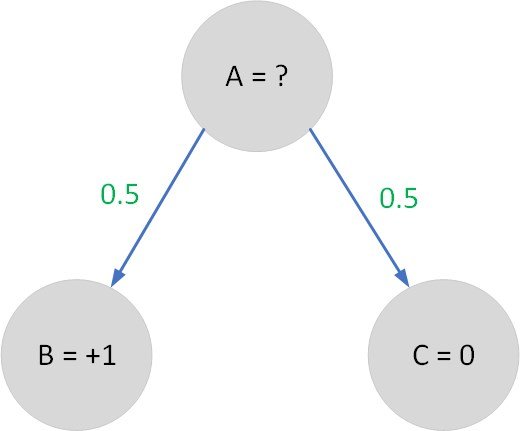
Sekarang kita berada di state A di mana ia belum memiliki nilai (value). States B dan C adalah terminal states, yang artinya jika kita berada di B atau C maka 1 episode telah berakhir (B dan C adlah kondisi terakhir). Jika kita ke B, maka kita akan mendapat reward sebesar 1, dan jika ke C maka netral. Probabilitas dari A ke B maupun ke C adalah sama yaitu 50:50.
Lalu berapa nilai yang dimiliki state A? Caranya adalah cukup mencari expected value dari A yaitu:
Value(A) = 0.5*1 + 0.5*0 = 0.5
Jadi nilai (value) yang dimiliki oleh state A saat ini adalah 0.5. Artinya state A memiliki peluang besaran nilai sebesar 0.5. Semakin besar nilai (value) sebuah state, maka ia akan lebih diprioritaskan oleh program RL kita nantinya.
Sekarang mari kita buat ilustrasi lain di mana tujuan kita hanyalah B, maka:
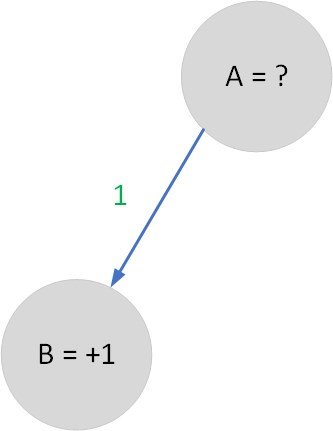
Value(A) = 1*1 = 1
Sekarang value dari state A adalah 1, karena memang itu satu-satunya state yang bisa diraih setelah state A.
Dengan demikian, bisa disimpulkan bahwa value adalah peluang nilai (future goodness) yang bisa didapat oleh state tersebut di masa depan.
Perbedaan Value dan Reward
Semoga pembaca tidak bingung dan bisa membedakan mana value dan mana reward. Value adalah potensi pendapatan nilai di masa depan yang dimiliki oleh sebuah state, sementara reward adalah nilai yang didapatkan oleh sebuah state saat ini.
Kita akan mendesain agar sistem RL kita bergerak berdasarkan value dan bukan reward. Mengapa? Karena reward adalah nilai yang didapatkan saat ini, dan ia tidak bisa memberitahu informasi lain selain itu. Dengan kata lain, reward tidak bisa memberitahu kita baik tidaknya sebuah state. Sementara jika menggunakan value, kita bisa tahu state mana saja yang memiliki potensi besar. Dengan demikian kita bisa mengarahkan agent agar selalu memilih state yang memiliki future value terbesar. Bisa dipahami ya sampai sini.
Formula Value Function
Sudah kita bicarakan di atas tentang cara perhitungan value, namun secara singkat bisa dituliskan:
V(s) = E [semua future rewards | S(t) = s)
Jadi value sebuah state s adalah expected value dari semua future rewards (given) dengan state saat ini adalah s.
Nilai (value) yang mungkin didapatkan oleh agent berada di rentang antara 0-1, dengan 0 adalah minimum dan 1 adalah maximum. Secara umum bisa kita tuliskan:
- V(s) = 1, jika agent menang
- V(s) = 0, jika agent kalah atau menang
- V(s) = 0.5, selain keduanya di atas
Tapi saat kita menjalankan RL nantinya, tidak akan sekaku seperti ilustrasi di atas (mengisi value dengan 0, 0.5 atau 1. Tapi yang kita lakukan adalah dengan menggunakan formula di bawah ini untuk melakukan update nilai V:
V(s) <– V(s) + α * (V(s′) − V(s))
di mana,
- s = state saat ini
- s’ = state selanjutnya
- α = tingkatan seberapa cepat agent kita belajar, atau sering disebut dengan istilah learning rate.
Perlu dicatat bahwa terminal state tidak akan bisa diupdate nilai V nya karena ia adalah state terakhir untuk setiap episodenya.
Proses Update Setiap States
Di formula atas kita tahu bahwa s merepresentasikan setiap states yang ada. s adalah state saat ini dan s’ adalah state di masa depan. Dengan demikian, ketika agent bermain TTT, maka ia juga harus mengingat semua states yang sudah ia lalui, dan terus mengupdate nilai value-nya.
Untuk lebih mudah memahaminya, mari kita lihat pseudocode berikut:
for i in range (iterasi_maksimum):
state_history = bermain_TTT
for (s, s') in state_history from akhir to awal:
V(s) = V(s) + learning_rate*(V(s') - V(s))
Penjelasan:
- Line 1 adalah iterasi untuk semua kemungkinan state yang bisa dilalui. Oleh karenanya dituliskan iterasi dari i sampai iterasi_maksimum.
- Line 2 adalah melakukan update variabel state_history. Di mana setiap agent bermain TTT maka ia akan menjadi bagian dari state_history. State_history yang dimaksud di sini adalah seperti list di Python. Di dalam state_history kita simpan semua nilai s dan s’ termasuk reward yang didapat.
- Line 3 melakukan looping untuk setiap s dan s’ yang ada di state_history kita lakukan iterasi dari belakang ke depan. Mengapa dari depan ke belakang, dan bukan sebaliknya? Akan dijelaskan nanti di pembahasan palingbawah di halaman ini.
Bagaimana Agent Memilih Action?
Jika sekarang kita sudah mengetahui bahwa agent akan selalu memilih state yang memberikan reward maksimum, maka bisa kita tuliskan pseudocode-nya:
max_V = 0
choice_A = None
for a, s' in states_yang_mungkin:
if V(s') &amp;amp;amp;amp;amp;amp;amp;amp;amp;gt; max_V:
max_V = V(s') // Nilai value maksimum
choice_A = a // Langkah (action) yang dipilih agar valuenya maksimum
jalankan action choice_A
Penjelasan:
- Line 1 kita set variabel max_V = 0. Nantinya variabel ini akan selalu diisi oleh nilai value yang paling besar dari state di depannya (s’).
- Line 2 kita set variabel choice_A adalah kosong (None). Nantinya variabel ini kita isi oleh action (a) yang kita pilih untuk menuju state dengan nilai maksimum tadi.
- Line 3 adalah looping untuk melakukan iterasi untuk setiap action (a) dan state baru (s’) yang mungkin dari list dengan nama states_yang_mungkin.
- Line 4 menyatakan bahwa jika nilai value sebuah state baru lebih besar dari nilai macimum value (max_V) nya saat ini, maka ia akan memilih state tersebut yang dijelaskan oleh line 5 dan 6.
- Line 5 menjelaskan bahwa kita isikan nilai value yang baru yang memberikan nilai maksimum tadi ke variabel max_V.
- Line 6 menjelaskan bahwa kita isikan action (a) yang kita pilih ke variabel choice_A.
- Line 7 melakukan eksekusi untuk menjalankan action choice_a yang sudah diupdate di line 6.
Saya harap pembaca sudah memahami pseudocode di atas. Karena jika sudah memahaminya, akan sangat mudah merubahnya ke bahasa Python nanti.
Update Secara Mundur
Hal yang penting adalah kita melakukan update secara mundur (dijelaskan sebelumnya di. Mengapa demikian? Coba kita lihat lagi formula update value function ini:
V(s) <– V(s) + α * (V(s′) − V(s))
Formula di atas mengasumsikan bahwa V(s’) selalu lebih baik dari V(s) untuk semua states yang mungkin (s’). Bisa juga dikatakan bahwa nilai V(s) selalu mendekati V(s’), karena ia selalu mencari nilai (value) yang lebih besar.
Permasalahannya adalah bagaimana jika V(s) dan V(s’) nilainya sama? Maka formula di atas tidak akan membantu banyak, karena pergerakan (action) agent akan random. Oleh karena itu solusinya adalah proses update V harus dilakukan secara mundur dengan melihat state_history dari state terminal (state akhir) ke kondisi awal.
Sekarang kita akan mulai masuk ke tahap programming di Python.
Untuk melanjutkan membaca silakan klik tombol halaman selanjutnya di bawah ini.
mantapppp… Langsung praktekin.!!
kayaknya tic tac toe dengan AI menjadi pembahasan mata kuliah ya bapak mega di kampus2 luar negeri, soalnya permasalahan seperti ini juga pernah di bahas di youtubenya Kylie Ying alumni harvard di https://www.youtube.com/watch?v=8ext9G7xspg&t=4832s
hanya saja menurut saya, penyampaian pak mega paling top..
dulu pernah utak atik python dengan NLTK, setelah lihat web dan youtube pak mega, semangat itu tumbuh kembali, tapi takuuut..
semoga terus bisa mengikuti perkembangan web dan youtube pak mega, terima kasih telah berkontribusi keilmuan untuk indonesai.
Ayo bermain tic tac