

Menjalankan Script Keseluruhan
Sekarang kita akan menjalankan pemainannya dengan AI yang akan memulai langkah pertama.
Jika semua script digabungkan, maka akan tampak seperti berikut:
import numpy as np
dimensi = 3
class Environment:
def __init__(self):
self.board = np.zeros((dimensi, dimensi))
self.x = -1
self.o = 1
self.winner = None
self.ended = False
self.num_states = 3**(dimensi*dimensi)
def kosong(self, i, j):
return self.board[i,j] == 0
def reward(self, sym):
if not self.game_over():
return 0
return 1 if self.winner == sym else 0
def akses_state(self):
k = 0
h = 0
for i in range(dimensi):
for j in range(dimensi):
if self.board[i,j] == 0:
v = 0
elif self.board[i,j] == self.x:
v = 1
elif self.board[i,j] == self.o:
v = 2
h += (3**k) * v
k += 1
return h
def game_over(self, proses_rekalkulasi=False):
if not proses_rekalkulasi and self.ended:
return self.ended
for i in range(dimensi):
for player in (self.x, self.o):
if self.board[i].sum() == player*dimensi:
self.winner = player
self.ended = True
return True
for j in range(dimensi):
for player in (self.x, self.o):
if self.board[:,j].sum() == player*dimensi:
self.winner = player
self.ended = True
return True
for player in (self.x, self.o):
if self.board.trace() == player*dimensi:
self.winner = player
self.ended = True
return True
if np.fliplr(self.board).trace() == player*dimensi:
self.winner = player
self.ended = True
return True
if np.all((self.board == 0) == False):
self.winner = None
self.ended = True
return True
self.winner = None
return False
def is_draw(self):
return self.ended and self.winner is None
# Contoh papan TTT
# -------------
# | x | | |
# -------------
# | | | |
# -------------
# | | | o |
# -------------
def menampilkan_board(self):
for i in range(dimensi):
print("-------------")
for j in range(dimensi):
print(" ", end="")
if self.board[i,j] == self.x:
print("x ", end="")
elif self.board[i,j] == self.o:
print("o ", end="")
else:
print(" ", end="")
print("")
print("-------------")
class Agent:
def __init__(self, eps=0.1, alpha=0.5):
self.eps = eps
self.alpha = alpha
self.verbose = False
self.state_history = []
def setV(self, V):
self.V = V
def set_symbol(self, sym):
self.sym = sym
def set_verbose(self, v):
self.verbose = v
def reset_history(self):
self.state_history = []
def mulai_jalan(self, env):
r = np.random.rand()
best_state = None
if r < self.eps:
if self.verbose:
print("Memilih action secara random")
kemungkinan_pergerakan = []
for i in range(dimensi):
for j in range(dimensi):
if env.kosong(i, j):
kemungkinan_pergerakan.append((i, j))
idx = np.random.choice(len(kemungkinan_pergerakan))
pergerakan_selanjutnya = kemungkinan_pergerakan[idx]
else:
pos2value = {}
pergerakan_selanjutnya = None
best_value = -1
for i in range(dimensi):
for j in range(dimensi):
if env.kosong(i, j):
env.board[i,j] = self.sym
state = env.akses_state()
env.board[i,j] = 0
pos2value[(i,j)] = self.V[state]
if self.V[state] > best_value:
best_value = self.V[state]
best_state = state
pergerakan_selanjutnya = (i, j)
if self.verbose:
print("Memilih action berdasarkan epsilon greedy")
for i in range(dimensi):
print("------------------")
for j in range(dimensi):
if env.kosong(i, j):
print(" %.2f|" % pos2value[(i,j)], end="")
else:
print(" ", end="")
if env.board[i,j] == env.x:
print("x |", end="")
elif env.board[i,j] == env.o:
print("o |", end="")
else:
print(" |", end="")
print("")
print("------------------")
env.board[pergerakan_selanjutnya[0], pergerakan_selanjutnya[1]] = self.sym
def update_state(self, s):
self.state_history.append(s)
def update(self, env):
reward = env.reward(self.sym)
target = reward
for prev in reversed(self.state_history):
value = self.V[prev] + self.alpha*(target - self.V[prev])
self.V[prev] = value
target = value
self.reset_history()
class Human:
def __init__(self):
pass
def set_symbol(self, sym):
self.sym = sym
def mulai_jalan(self, env):
while True:
move = input("Masukkan koordinat di papan i,j untuk pergerakan selanjutnya (i,j=0-2): ")
i, j = move.split(',')
i = int(i)
j = int(j)
if env.kosong(i, j):
env.board[i,j] = self.sym
break
def update(self, env):
pass
def update_state(self, s):
pass
def akses_state_end_winner(env, i=0, j=0):
results = []
for v in (0, env.x, env.o):
env.board[i,j] = v
if j == 2:
if i == 2:
state = env.akses_state()
ended = env.game_over(proses_rekalkulasi=True)
winner = env.winner
results.append((state, winner, ended))
else:
results += akses_state_end_winner(env, i + 1, 0)
else:
results += akses_state_end_winner(env, i, j + 1)
return results
def awal_V_x(env, state_winner_triples):
V = np.zeros(env.num_states)
for state, winner, ended in state_winner_triples:
if ended:
if winner == env.x:
v = 1
else:
v = 0
else:
v = 0.5
V[state] = v
return V
def awal_V_o(env, state_winner_triples):
V = np.zeros(env.num_states)
for state, winner, ended in state_winner_triples:
if ended:
if winner == env.o:
v = 1
else:
v = 0
else:
v = 0.5
V[state] = v
return V
def bermain(p1, p2, env, draw=False):
pemain_saat_ini = None
while not env.game_over():
if pemain_saat_ini == p1:
pemain_saat_ini = p2
else:
pemain_saat_ini = p1
if draw:
if draw == 1 and pemain_saat_ini == p1:
env.menampilkan_board()
if draw == 2 and pemain_saat_ini == p2:
env.menampilkan_board()
pemain_saat_ini.mulai_jalan(env)
state = env.akses_state()
p1.update_state(state)
p2.update_state(state)
if draw:
env.menampilkan_board()
p1.update(env)
p2.update(env)
if __name__ == '__main__':
p1 = Agent()
p2 = Agent()
env = Environment()
state_winner_triples = akses_state_end_winner(env)
Vx = awal_V_x(env, state_winner_triples)
p1.setV(Vx)
Vo = awal_V_o(env, state_winner_triples)
p2.setV(Vo)
p1.set_symbol(env.x)
p2.set_symbol(env.o)
T = 20000
for t in range(T):
if t % 200 == 0:
print(t)
bermain(p1, p2, Environment())
human = Human()
human.set_symbol(env.o)
while True:
p1.set_verbose(True)
bermain(p1, human, Environment(), draw=2)
jawaban = input("Ingin bermain lagi? [Y/n]: ")
if jawaban and jawaban.lower()[0] == 'n':
break
Pembaca bisa menentukan jumlah kotak TTT. Misal jika ingin ukuran 4×4 maka line 2 cukup ubah dimensi menjadi 4. Kemudian cukup sesuaikan environmentnya agar tampilan di layar menyesuaikan untuk 4 cells.
Jika dijalankan semuanya, tampilannya akan seperti berikut:
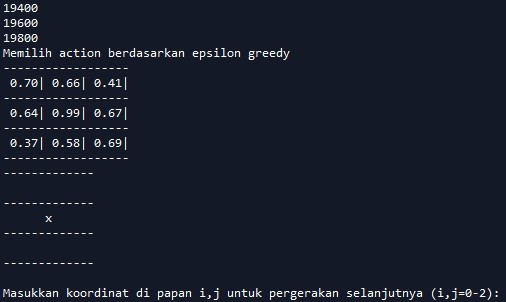
Kita bisa melihat bahwa Agent sudah berlatih sebanyak 20 ribu kali. Kemudian AI bergerak berdasarkan epsilon greedy dan memilih untuk mengisi kotak tengah (koordinat 1,1) berdasarkan skor value terbesar (0.99).
Sekarang giliran kita (simbol O) mau mengisi kotak yang mana. Anggap kita ingin mengisi kotak (0,0), maka cukup ketikkan di layar 0,0. Hasilnya tampak sebagai berikut:
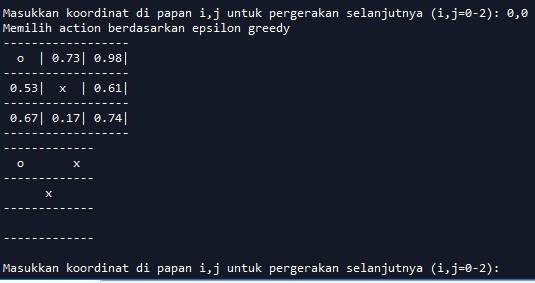
Setelah kita memberikan respon koordinat (0,0) di mana muncul simbol O di kiri paling atas, AI langsung mengambil langkah untuk mengisi koordinat (0,2) berdasarkan nilai value terbesar.
Sekarang kita coba melangkah lagi. Agar AI tidak menang kita harus pilih (2,0) atau kiri bawah. Maka hasilnya tampak sebagai berikut:
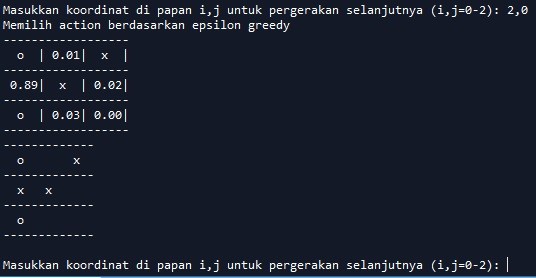
Ternyata AI langsung mengisi koordinat (1,0) kiri tengah. Kali ini kita akan membiarkan ia menang. Kita cukup mengisi koordinat (0,1) atau atas tengah. Hasilnya tampak sebagai berikut:
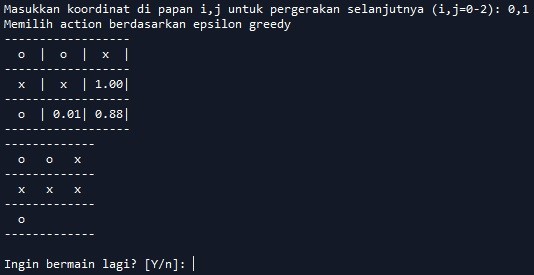
Sesuai dugaan, AI akan langsung memilih koordinat (1,2) atau kanan tengah. Dan akhirnya ia memenangkan permainan!
Jika ingin melanjutkan bermain cukup ketikkan Y di layar, atau jika ingin berhenti ketikkan n.
Pembaca juga bisa mencoba melawan AI dengan cara memulai lebih dahulu, dan hasilnya pasti akan menarik. Jika ingin menantang lagi, pembaca juga bisa merubah ukuran papannya, menjadi 4×4, 5×5 dan terserah pembaca.
Silakan berkreasi sendiri, dan bisa saja pembaca merubah cara Agent AI mengambil langkah dengan memodifikasi script ini.
Sampai di sini saya harap pembaca bisa terbayang seperti apa reinforcement learning, bagaimana membuatnya dan tentunya memahami konsep dasar hingga hasil jadinya.
Dengan memahami konsep dasarnya, pembaca bisa terus mengembangkan aplikasinya sendiri. Dengan terus berlatih, maka pembaca bisa saja membuat agent yang benar-benar hidup dan berperilaku seperti manusia sungguhan.
Di kesempatan lain kita akan membahas aplikasi-aplikasi AI yang lainnya.
Jika ada pertanyaan silakan tulis di bagian komentar.
Tetap semangat belajar AI!
mantapppp… Langsung praktekin.!!
kayaknya tic tac toe dengan AI menjadi pembahasan mata kuliah ya bapak mega di kampus2 luar negeri, soalnya permasalahan seperti ini juga pernah di bahas di youtubenya Kylie Ying alumni harvard di https://www.youtube.com/watch?v=8ext9G7xspg&t=4832s
hanya saja menurut saya, penyampaian pak mega paling top..
dulu pernah utak atik python dengan NLTK, setelah lihat web dan youtube pak mega, semangat itu tumbuh kembali, tapi takuuut..
semoga terus bisa mengikuti perkembangan web dan youtube pak mega, terima kasih telah berkontribusi keilmuan untuk indonesai.
Ayo bermain tic tac