

Catatan: Jika Anda belum mengerti dasar-dasar python silakan klik artikel saya ini. Jika Anda awam tentang R, silakan klik artikel ini.
Setelah memahami konsep regresi, langkah selanjutnya adalah membuat model ML untuk SLR (simple linear regression).
Pada contoh kali ini, kita ingin membuat sebuah model regresi, yaitu fungsi antara lamanya bekerja terhadap besarnya gaji yang didapat. Nantinya output model kita ini (prediksi gaji) akan kita bandingkan dengan gaji yang sebenarnya, sehingga dapat dilihat apakah model kita sudah cukup baik (prediksi sangat mendekati kenyataan) atau sebaliknya.
Pertama download dulu dataset yang ingin kita olah dengan klik link ini.
Bahasa Python
# Impor library yang dibutuhkan
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Impor dataset
dataset = pd.read_csv('Daftar_gaji.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 1].values
# Membagi data menjadi Training Set dan Test Set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 1/3, random_state = 0)
# Fitting Simple Linear Regression terhadap Training set
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, y_train)
# Memprediksi hasil Test Set
y_pred = regressor.predict(X_test)
# Visualisasi hasil Training Set
plt.scatter(X_train, y_train, color = 'red')
plt.plot(X_train, regressor.predict(X_train), color = 'blue')
plt.title('Gaji vs Pengalaman (Training set)')
plt.xlabel('Tahun bekerja')
plt.ylabel('Gaji')
plt.show()
# Visualisasi hasil Test Set
plt.scatter(X_test, y_test, color = 'red')
plt.plot(X_train, regressor.predict(X_train), color = 'blue')
plt.title('Gaji vs Pengalaman (Test set)')
plt.xlabel('Tahun bekerja')
plt.ylabel('Gaji')
plt.show()
Penjelasan:
- Line 2 sampai 4 adalah mengimpor library yang diperlukan.
- Line 7 mengimpor data ke python.
- Line 8 menentukan variabel independen (sumbu x) yaitu kolom ke 1 (Tahun_bekerja). Perlu diperhatikan, ketika melakukan slicing kita menggunakan method .values, hal ini hanya akan memotong data tanpa headernya. Jika tanpa .values maka header dari slicing akan diikutkan.
- Line 9 menentukan variabel dependen (xumbu y) yaitu kolom ke 2 (Gaji).
- Line 12 mengimpor library untuk memisahkan menjadi test dan train set.
- Line 13 membagi menjadi test dan train set, di mana train set adalah 2/3 dari dataset yang ada. Anda bisa klik bagian Variable explorer di spyder untuk melihat hasil pembagian train dan test set nya.
- Line 16 mengimpor class LinearRegression dari library sklearn.linear_model yang diperlukan untuk membuat model regresi.
- Line 17 membuat objek regressor sebagai fungsi dari LinearRegression. Cukup menulis LinearRegression() maka model regresi sudah disiapkan. Jika Anda arahkan kursor pada LinearRegression dan klik CTRL+i maka akan menampilkan object inspector untuk LinearRegression. Di sini Anda bisa melihat parameter apa saja yang diperlukan.
- Line 18 membuat model regresi untuk train set dengan menuliskan regressor.fit(X_train, y_train). Untuk melihat parameter apa saja yang diperlukan untuk metode fit(), cukup arahkan kursor pada .fit() kemudian klik CTRL+i.
Line ke 18 adalah proses di mana kita membuat model machine learning regresi. Artinya, model kita sedang belajar untuk mencari hubungan antara X_train dan y_train.
Output di python akan tampak sebagai berikut Out[12]: LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False).
Setelah machine learning kita belajar mencari tahu hubungan antara X_train dan y_train, maka langkah selanjutnya adalah kita mencoba membuat prediksi ke depan, di mana prediksi ini menggunakan hubungan yang sudah dipelajari oleh model kita. Perintah untuk melakukan prediksi ini dilakukan di line 21.
- Line 21 membuat prediksi dengan menggunakan metode .predict. Untuk menegtahui parameter apa saja, kita bisa melihatnya melalui object inspector. Parameter yang diperlukan adalah variabel independen, dalam hal ini adalah X_test dan bukan X_train. Mengapa demikian? Karena kita ingin memprediksi data baru. Jika menggunakan X_train maka kita membuat prediksi berdasarkan pemahaman X_train, padahal pemahaman itu sendiri dibuat berdasarkan X_train. Oleh karena itu, kita menggunakan X_test. Nantinya prediksi ini kita bandingkan dengan y_test. Jika hasilnya mendekati (jaraknya tidak terlalu jauh), maka model kita sudah baik.
Jika sudah, mari kita bandingkan hasil y_pred dengan y_test, di mana y_pred adalah prediksi model kita dan y_test adalah data yang sesungguhnya.
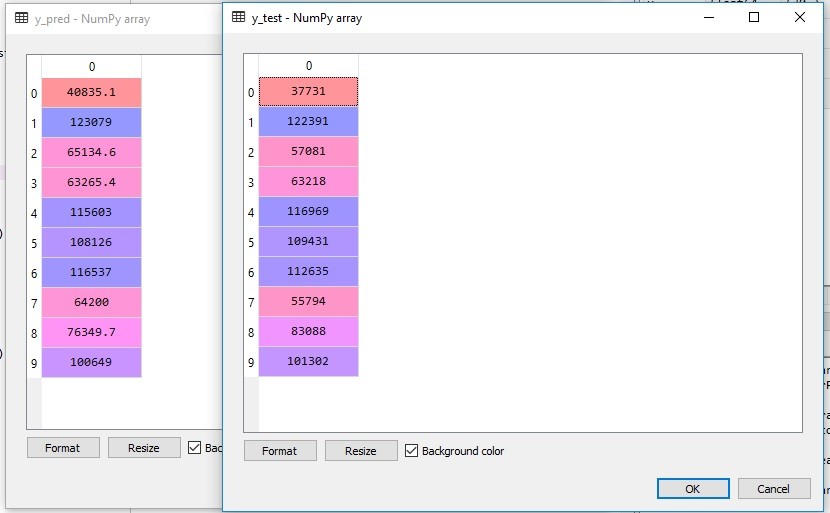
Untuk bisa membandingkan hasil antara y_pred dan y_test, akan sangat baik jika dibuat ilustrasi visualnya. Perlu diperhatikan, agar menampilkan visual yang baik di python, maka block semua line dari line 24 sampai line 29 kemudian klik CTRL+ENTER.
- Line 24 membuat scatter plot X_train dan y_train dengan warna merah untuk data poinnya. Tentu saja warnanya bisa dirubah sesuka hati.
- Line 25 membuat line plot nya (garis regresi) dengan warna biru. metode plot() membutuhkan parameter pertama yaitu data poin untuk sumbu x, dan parameter kedua adalah data poin untuk sumbu y. Data poin sumbu x adalah X_train karena kita ingin melihat model regresi dari training set, sementara data poin sumbu y adalah prediksi dari X_train dengan perintah regressor.predict(X_train). Perlu diingat, data poin sumbu y bukan y_predict atau regressor.predict(X_test), karena tujuan kita kali ini membuat plot regresi untuk X_train, bukan X_test. Semisal Anda salah, menggunakan regressor.predict(X_test), maka garis regresinya tidak akan muncul. Mengapa? Karena jumlah data poin X_train (20 baris) dan X_test (10 baris) sudah berbeda, maka tidak mungkin bisa dibuat garis regresinya.
- Line 26 membuat judul yang akan ditampilkan di bagian paling atas grafik.
- Line 27 membuat label untuk sumbu x.
- Line 28 membuat label untuk sumbu y.
- Line 29 mengeksekusi dan menampilkan hasil dari semua perintah dari line 24 sampai line 28.
Jika sudah, maka hasilnya akan nampak sebagai berikut:

Jika spyder menampilkan gambarnya di bagian console, maka Anda bisa merubahnya untuk tampil di window (jendela) lain. Caranya masuk ke Tools > preferences > IPython console > Graphics > Graphics backend > Backend: Automatic.
Titik merah adalah nilai gaji sesungguhnya, sementara garis biru adalah prediksi gaji dari model regresi kita.
- Line 32 sampai line 37 adalah perintah menampilkan grafik untuk test set. Perhatikan bahwa di line 33 plot line nya masih menggunakan X_train dan bukan X_test, karena model regresi kita berbasis pada training set. Walau demikian, sangat kebetulan sekali seandainya Anda salah menggunakan perintah ini misalnya: plt.plot(X_test, regressor.predict(X_test), color = ‘blue’), maka hasilnya akan sama. Namun, saya ulang kembali Anda tetap perlu mengingat bahwa model regresinya adalah menggunakan X_train dan bukan X_test.
Jika sudah, maka hasil dari test set akan seperti berikut:

Bahasa R
# Mengimpor dataset
dataset = read.csv('Daftar_gaji.csv')
# Membagi dataset menjadi Training set and Test set
# install.packages('caTools') <-- jika belum mempunyai library nya hapus tanda #
library(caTools)
set.seed(123)
split = sample.split(dataset$Gaji, SplitRatio = 2/3)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
# training_set = scale(training_set)
# test_set = scale(test_set)
# Fitting Simple Linear Regression ke the Training set
regressor = lm(Gaji ~ Tahun_bekerja, data = training_set)
# Memprediksi hasil test set
y_pred = predict(regressor, newdata = test_set)
# Visualising the Training set results
library(ggplot2)
ggplot() +
geom_point(aes(x = training_set$Tahun_bekerja, y = training_set$Gaji), colour = 'red') +
geom_line(aes(x = training_set$Tahun_bekerja, y = predict(regressor, newdata = training_set)), colour = 'blue') +
ggtitle('Gaji vs Tahun bekerja (Training set)') +
xlab('Tahun bekerja') +
ylab('Gaji')
# Visualising the Test set results
library(ggplot2)
ggplot() +
geom_point(aes(x = test_set$Tahun_bekerja, y = test_set$Gaji), colour = 'red') +
geom_line(aes(x = training_set$Tahun_bekerja, y = predict(regressor, newdata = training_set)), colour = 'blue') +
ggtitle('Gaji vs Tahun bekerja (Test set)') +
xlab('Tahun bekerja') +
ylab('Gaji')
# Analisis statistik model regresi
summary(regressor)
Penjelasan:
- Line 2 mengimpor datasetnya.
- Line 6 mengimpor library caTools untuk membagi data ke train dan test set.
- Line 7 menentukan bilangan randomnya (Dalam contoh kali ini adalah 123. Tentu saja angkanya bebas).
- Line 8 mendefinisikan variabel split untuk pembagian train dan test set. Untuk bisa melihat parameter apa saja yang diperlukan cukup arahkan kursor ke sample.split, kemudian klik F1. Maka akan muncul dokumentasinya. Parameter pertama adalah variabel dependennya (Gaji), kemudian secara default rasio splitnya adalah 2/3.
- Line 9 menentukan bagian training set, dari hasil boolean TRUE dari variabel split.
- Line 10 menentukan bagian test set, dari hasil boolean FALSE dari variabel split.
- Line 12 sampai line 14 adalah perintah feature scaling jika diperlukan. Kali ini kita tidak memerlukannya.
- Line 17 adalah mendefinisikan objek regressor sebagai sebuah model regresi. Di R, perintah membuat model regresi adalah dengan menggunakan fungsi lm(). Parameter pertama adalah variabel dependen (Gaji) diikuti dengan simbol ~ (disebut dengan tilde). Kemudian setelah simbol ~ diikuti dengan variabel independen yaitu Tahun_bekerja, dan kita definisikan datanya diambil dari training_set.
- Line 20 adalah prediksi pembelajaran machine learning untuk test set. Line 20 ini sama dengan line 21 y_pred dalam perintah bahasa python di atas.
- Line 23 mengimpor library ggplot2 untuk membuat visualisasi model regresi kita. ggplot2 adalah library yang terkenal di R, karena bisa menampilkan visualisasi yang beragam dan powerful. Perlu diperhatikan, penulisan ggplot sebenarnya satu baris, namun Anda bisa melanjutkan penullisan di bawahnya jika layar komputer Anda tidak bisa menampilkan semua perintah dalam satu baris. Jika Anda klik ENTER, maka otomatis akan beralih ke baris di bawahnya, dan R otomatis juga akan memberikan indentasi (menjorok sedikit ke kanan).
- Line 24 perintah awal ggplot, diikuti dengan parameter selanjutnya dengan simbol +. Perintah ggplot() adalah mempersiapkan objek visualisasi, yang jika diikuti simbol + maka semua komponen visualisasi setelah simbol + akan dieksekusi bersamaan.
- Line 25 membuat scatter plot dengan perintah geom_point diikuti dengan aes (singkatan dari aesthetic) untuk menentukan mana sumbu x dan mana sumbu y. dan warna apa yang Anda inginkan.
- Line 26 membuat plot line dengan perintah geom_line. Parameternya sama dengan geom_point.
- Line 27 memberikan judul untuk grafiknya
- Line 28 memberikan label untuk sumbu x
- Line 29 memberikan label untuk sumbu y
Jika dieksekusi, maka akan menampilkan grafik sebagai berikut:
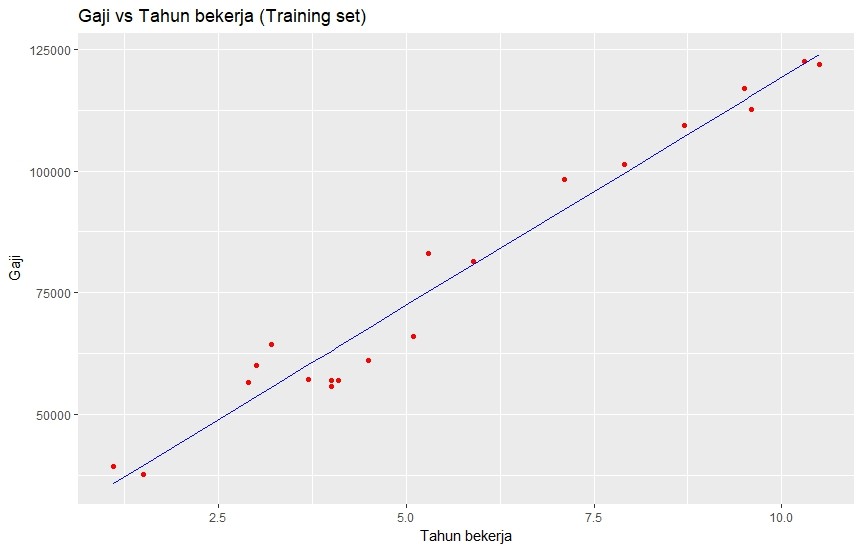
- Line 32 sampai line 38 menampilkan grafik untuk test set.
Jika dieksekusi, maka akan menampilkan grafik sebagai berikut:

Sampai di sini Anda bisa melihat bagaimana model kita (bahasa python dan R) cukup baik memprediksi gaji dengan menggunakan pembelajaran dari dataset X_train.
Untuk bisa memastikan seberapa akurat, maka perlu dilakukan uji statistik. Dalam hal ini R memang didesain sebagai software statistik, maka pengujianya cukup menulis perintah summary pada line 41.
- Line 41 perintah melihat seberapa baik (fit) model regresi yang kita buat. Cukup menulis summary(diikuti model regresinya)
Jika dieksekusi maka hasilnya adalah sebagai berikut:

Residuals adalah seberapa banyak data poin yang tidak bisa dijelaskan dengan model kita. Gambaran umumnya adalah semakin kecil residual, maka semakin kuat model regresi kita menjelaskan hubungan antara variabel dependen dengan independen. Min menyatakan nilai minimum, 1Q menyatakan nilai residual kuartal pertama (persentil 25), median adalah nilai tengah, 3Q adalah persentil 75, dan Max adalah nilai terbesar.
Penjelasan bagian Coefficients:
- Intercept merupakan koefisien yang dimiliki model regresi Anda. Artinya untuk setiap nilai X nol (karyawan tanpa pengalaman bekerja di perusahaan ini), ia akan mendapatkan gaji sebesar 25592 euro per tahun. Angka ini Anda bisa lihat di bagian Estimate dari Intercept.
- Kemudian pada bagian Tahun_bekerja nilai 9365 menyatakan bahwa untuk setiap penambahan tahun bekerja sebanyak 1 tahun, gajinya akan bertambah sebesar 9365 euro per tahun.
- Jika Anda tulis persamaan regresinya maka dapat ditulis sebagai berikut:
- Std.Error (standar error) adalah seberapa menyimpang data prediksi dari data sesungguhnya. Semakin kecil std. error tentu semakin baik model kita.
- t value adalah uji statistik dari distribusi t. Nilai t di atas 2 atau kurang dari -2 secara umum sudah dianggap signifikan.
- Pr adalah p value. Variabel independen kita (Tahun_bekerja) memiliki nilai p di bawah 0.05, artinya ia signifikan memprediksi variabel dependen (Gaji).
- Untuk melihat seberapa baik, maka lihat bagian Multiple R-squared yang merupakan nilai , yang nilainya berkisar dari 0 sampai 1. Nilai nol (0), artinya error (jarak antara nilai prediksi dengan nilai yang sebenarnya) terlalu besar, sehingga modelnya sangat buruk. Sebaliknya jika nilainya 1 adalah model yang sempurna, artinya prediksinya benar-benar tanpa error.
Pastilah tidak mungkin model regresi memiliki nilai 1, karena jika demikian maka model kita terlalu sempurna (ada yang salah, atau tidak beres). Model kita memiliki nilai 0.96 tentunya modelnya sangatlah baik (karena ini hanya data contoh untuk mempermudah).
Jika Anda melakukan pendekatan regresi, kemudian nilai sangat buruk, misal kurang dari 0.5 atau mendekati nol, maka bisa dipastikan hubungan variabel dependen dan independen tidaklah linear. Jika demikian, Anda bisa melakukan fitting (melihat hubungan variabel dependen dengan independen) dengan model regresi polinomial, atau non linear.
Sampai di sini saya berharap Anda bisa membuat model ML (Machine learning) Anda sendiri.
Semoga bermanfaat.
Saya mau tanya gan? saya sudah coba source code di bawah ini.. # Impor dataset dataset = pd.read_csv(‘E:/LatihanPython/Daftar_gaji.csv’) #data = pd.read_csv(“E:/LatihanPython/seminar.csv”) #dataset.head(30) X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 1].values # Membagi data menjadi Training Set dan Test Set from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 1/3, random_state = 0) # Fitting Simple Linear Regression terhadap Training set from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(X_train, y_train) # Memprediksi hasil Test Set y_pred = regressor.predict(X_test) # Visualisasi hasil Training Set plt.scatter(X_train, y_train, color = ‘red’) plt.plot(X_train, regressor.predict(X_train), color = ‘blue’) plt.title(‘Gaji vs Pengalaman (Training… Read more »
Sip berarti sudah ada solusinya ya untuk cross_validation. Sepertinya ketika sklearn diupdate, saya kelupaan update script (dari cross_validation menjadi model_selection) di artikel ini. Untuk plotting nya lancar-lancar saja di sini. Kalau dari yang disampaikan sepertinya berhasil dieksekusi tapi plotnya tidak muncul di layar. Bisa dicek di bagian setting spyder, jupyter notebook, atau IDE lainnya yang dipakai. Terkadang bisa juga komputer sedikit lama memproses grafisnya tergantung speknya (jika ini yang terjadi, ditunggu saja). Untuk –> ‘Accuracy score: ‘, accuracy_score(y_test, y_pred)) dihapus saja, karena line ini digunakan khusus untuk permasalahan klasifikasi, sementara kita membahas regresi. Saya juga bingung kenapa ada line itu… Read more »
bang beda antara cross.validation dan model.selection apa ya?
Sama saja, dulu sklearn masih pakai cross_validation, sekarang sudah diganti model_selection.
Di artikel ini belum saya update, jadi sebaiknya pakai model_selection
Pak untuk menampilkan summary di Python seperti di R gimana ya pak?
Halo,
Kelemahan dari library sklearn di Python adalah tidak bisa menampilkan summary seperti di R, karena sklearn lebih fokus ke predictive analysis dan machine learning, sementara memang software R spesialisasi untuk statistik.
Untuk mendapatkan summary seperti R, gunakanlah library stasmodels.
import statsmodels.api as sm
X = sm.add_constant(X.ravel())
results = sm.OLS(y,X).fit()
results.summary()
Semoga menjawab.
Terimakasih pak infonya, tapi hasil dari python disini nilai coef untuk intercept dan tahun bekerja agak sedikit berbeda pak dengan hasil yang di R 😀 OLS Regression Results ============================================================================== Dep. Variable: Gaji R-squared: 0.957 Model: OLS Adj. R-squared: 0.955 Method: Least Squares F-statistic: 622.5 Date: Mon, 27 Apr 2020 Prob (F-statistic): 1.14e-20 Time: 10:18:52 Log-Likelihood: -301.44 No. Observations: 30 AIC: 606.9 Df Residuals: 28 BIC: 609.7 Df Model: 1 Covariance Type: nonrobust ================================================================================= coef std err t P>|t| [0.025 0.975] ——————————————————————————— Intercept 2.579e+04 2273.053 11.347 0.000 2.11e+04 3.04e+04 Tahun_bekerja 9449.9623 378.755 24.950 0.000 8674.119 1.02e+04 ============================================================================== Omnibus: 2.140 Durbin-Watson: 1.648… Read more »
Halo, Iya hasilnya beda karena di perintah yang saya tulis kemarin langsung membuat model regresi tanpa perlu membagi ke training set dan test set. Silakan dicoba pasti hasilnya sama. Jadi scriptnya seperti ini: Python: import numpy as np import pandas as pd import statsmodels.api as sm dataset = pd.read_csv(‘Daftar_gaji.csv’) X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 1].values X = sm.add_constant(X.ravel()) results = sm.OLS(y,X).fit() results.summary() R dataset = read.csv(‘Daftar_gaji.csv’) regressor = lm(Gaji ~ Tahun_bekerja, data = dataset) summary(regressor) ————- Catatan tambahan, jika ingin dibagi menjadi training dan test set, hasinya nanti tidak akan sama. Mengapa? Karena algoritma pembagian antara Python dan… Read more »
Terimakasih banyak pak atas jawabannya 😀
Assalamualaikum, pak saya izin bertanya bagaimana caranya untuk membuat kode regresi linier dengan inputan variabel yang diminta yang ada di dataset tersebut?
Wa’alaikumsalam, maksudnya bagaimana ya?